
Deep Learning
Fast Fourier Convolution — A detailed view
Solving issues with Vanilla CNNs
Hello all, Hope you are doing good. In this post, we will go through a research paper named “Fast Fourier Convolution”. This paper explores the problems with the convolution operator in CNNs and proposes a new operator to replace the convolution operator. This has improved the accuracies for computer vision tasks such as image classification, action recognition etc.,
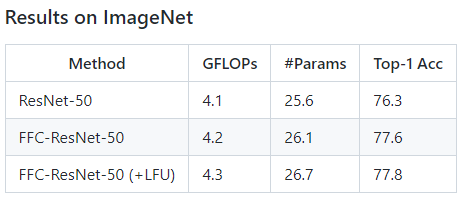
The Resnet architecture has been modified to include the FFC operator in place of convolution layers and has shown an improvement of 1.5 in Top-1 accuracy on the Imagenet dataset. The accuracies have improved in a similar manner for action recognition and human keypoint detection tasks across different architectures. More of this is in the results section.
Problems with CNNs
- Receptive field — The image part that is accessible by one filter. Most of the CNNs have 3x3 filters which have less receptive fields. This has been solved to some extent by stacking the layers. But for context-sensitive tasks such as human pose estimation, a large receptive field is highly desired.
- Cross-scale fusion — CNNs provide different levels of feature abstraction at different stages. For accurate spatial detection, the fusion of these features is preferred. Works like FPN does the same thing, but with additional layers. This increases the complexity of the network.
FFC is a novel convolutional operator that efficiently implements non-local receptive fields and fuses multi-scale information.
Idea
- Borrowed from Spectral-domain (Spectral convolution theorem)
- Updating a single value in spectral-domain globally affects all original data
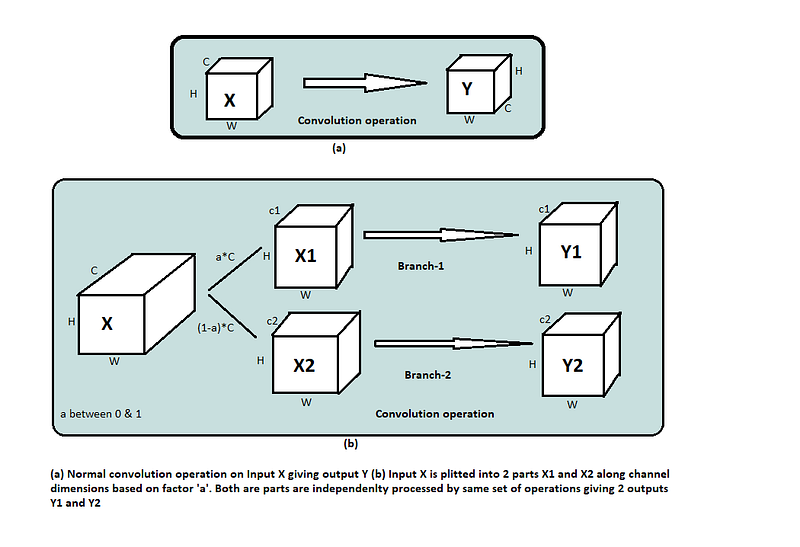
- Convert the spatial features to spectral features — Apply some operations — Convert back to spatial features
- operations in spectral-domain indicate the receptive field of convolution to the full resolution of the input feature map
FFC Components
The idea is to replace the convolution layer (Conv2D) with the FFC block.
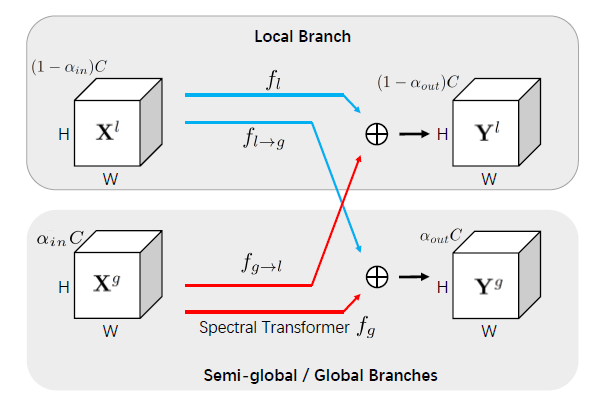
FFC block consists of 2 paths — local and global. The local path uses ordinary convolution operators on the input feature maps and the global path operates in the spectral domain. You can get an idea from the figure below.
The actual FFC has interconnections between 2 paths as shown below
The output blocks Y_l and Y_g are calculated as below.
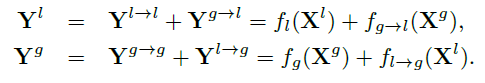
Except for f_g() all other 3 functions (f_l, f_l_g, f_g_l) are convolution layers. f_g() function is a Spectral Transformer.
You can see the code block below for the FFC block for better understanding.
Remember, The whole FFC block shown above is just a replacement of Conv2D layer
The only unknown block in the FFC implementation is Spectral Transformer. Let’s have a look at Spectral Transformer in detail.
Spectral transformer
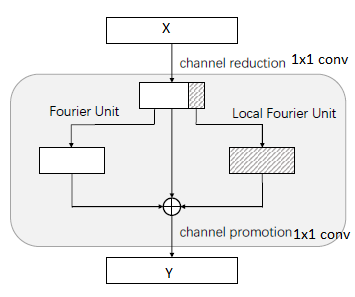
The spectral transformer has 3 branches — Fourier Unit (FU) and Local Fourier Unit (LFU) and a Residual connection. FU operates on the whole input feature map X, whereas the LFU operates only on a quarter of the input feature channels (C/4).
Fourier Unit: The Fourier unit has a series of operations. The block diagram and pseudo-code are given below. The blocks are self-explanatory.
- FFT is applied on the input X which gives x_r, x_i which are real and imaginary parts.
- Concatenate both x_r and x_i to get a single feature map.
- Apply convolution operation on the concatenated features.
- Split the output into real and imaginary parts again — y_r, y_i.
- Apply Inverse FFT on y_r, y_i to get final output Y.
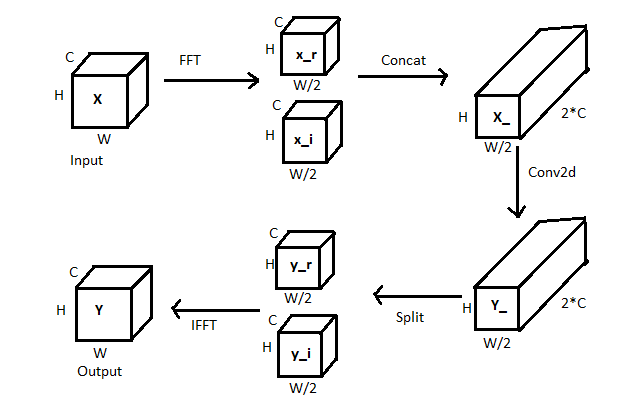

The code below should help you in understanding better.
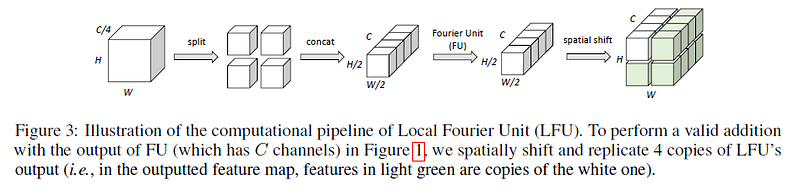
Local Fourier Unit: FU manipulates the entire feature map whereas LFU captures semi-local information. The main difference between both is an additional split and concatenate step.
- LFU receives only 1/4th of the feature channels (C/4) and it splits the input into 4 halves spatially. Each block still has C/4 channels, but width and height are reduced by half. — (4, H/2,W/2,C/4)
- Concatenate the 4 blocks to get single block — (1,H/2,W/2,C)
- Apply Fourier Unit block on the concatenated output and then replicate it to form (1,H,W,C)
Both FU and LFU are parallel branches and are added element-wise, so the output dimensions from both the branches should match. That is the reason for the replication of LFU output. Check the figure below for a clear picture.
This concludes the whole FFC block. FFC block is fully differentiable and can be inserted into most CNNs without additional modification.
Experiments & Results
FFC was evaluated on 3 tasks — image classification, video action classification and human keypoint detection. It performed better than the vanilla architectures for all tasks by replacing the convolution layers with FFC blocks.
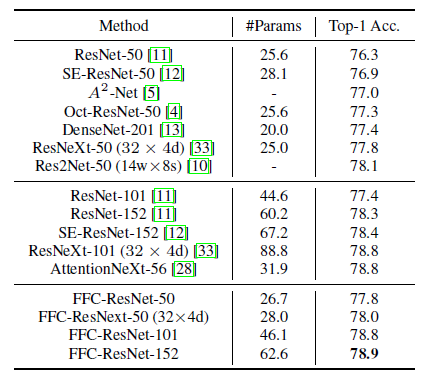
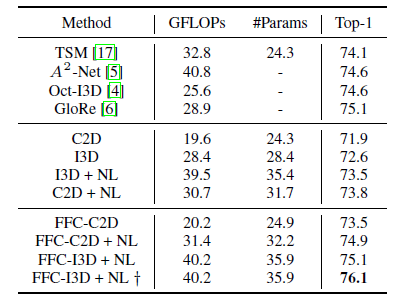
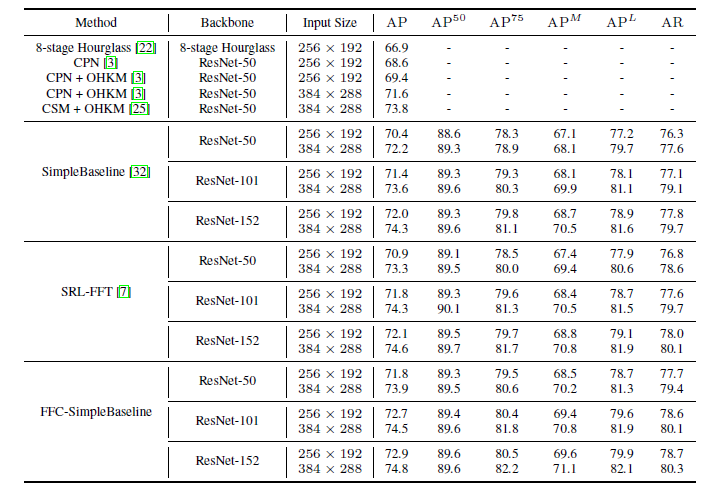
As you can see from the tables, networks with FFC blocks consistently improved top-1 accuracies by 1.5%.
Choice of alpha: Ablation studies have been conducted to find the effect of alpha. The value 0 indicates there is no global branch in FFC, which in turn indicates there is no spectral transformer. So this is the same as vanilla convolutions. Value 1 indicates that all features go through the Spectral transformer. Below are the results of ablation studies on the Imagenet dataset with the ResNet-50 backbone.
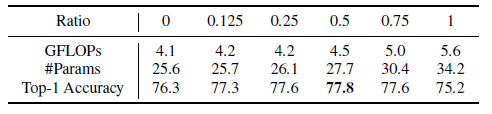
alpha=0.5 gave the best results but alpha=0.25 was used in all the experiments considering the tradeoff between performance and complexity.
That’s all for this post. Let me know if you have any doubts or clarifications required. Below are the links for paper and code implementation.
References
- https://papers.nips.cc/paper/2020/file/2fd5d41ec6cfab47e32164d5624269b1-Paper.pdf
- https://github.com/pkumivision/FFC
Check out my previous paper walkthroughs.




