
Deep Learning
Involution: Inverting the Inherence of Convolution for Visual Recognition
Inverting the inherent principles of Convolution.

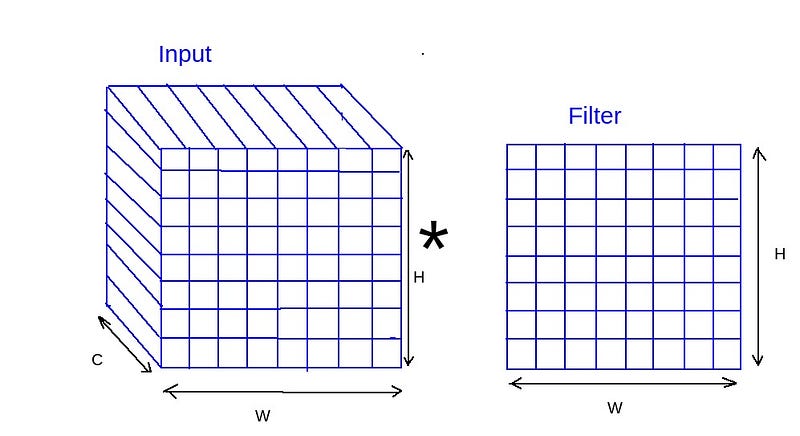
Convolutional Neural Networks have been ruling the computer vision domain for almost a decade now. They have been the go-to networks for any Computer Vision task ranging from Image classification to Instance Segmentation.
The basic building block in CNNs is Convolution operation. It works similar to traditional computer vision filters for detecting edges and shapes etc., The basic idea is the same except that the filter is learned from data here.
Have a look at this post for an intuitive understanding of Convolution.
The basic principles of convolution operation are Spatial agnostic and Channel Specific.
Spatial Agnostic
The same filter is used for convolution across spatial dimensions.
Intuition: Filters should learn the features of objects irrespective of location on the images. For example, the filter should identify a cat whether it is present in the top-left or bottom-right in the image.
Channel Specific
Different filters are used to learn different properties which we call channels in a CNN.
There are few limitations to these principles.
- Filters won’t be able to adapt to diverse visual patterns with respect to different spatial positions.
- You can’t capture the long-range spatial interactions in a single shot.
- A lot of redundancy among channels (filters).
The solutions for the above limitations are:
- Make spatial-specific filters to learn diverse visual patterns across spatial positions.
- Use some sort of attention mechanism for capturing long-range spatial interactions. Ex: DETR
- Reduce the number of channels — channel-agnostic.
Involution
To solve the limitations of Convolution, An operation named involution is introduced in this research paper by Hong Kong University of Science & Technology.
Involution is just the inverse of convolution. It has inverse characteristics of convolution, namely, spatial-specific and channel-agnostic.
Channel-agnostic
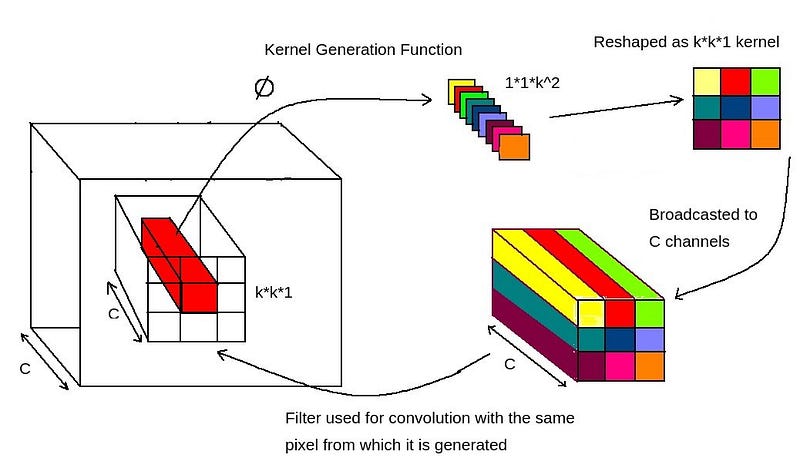
Channel-agnostic is pretty simple. Use the same filter across all the input channels. At least use few filters and broadcast them to match the input channels. This should reduce the redundancy in convolution.
Spatial Specific
In convolution, we use the same 3x3 filter and slide it across the input spatially. This 3x3 filter is agnostic to spatial dimensions. How can we make spatial-specific filters?
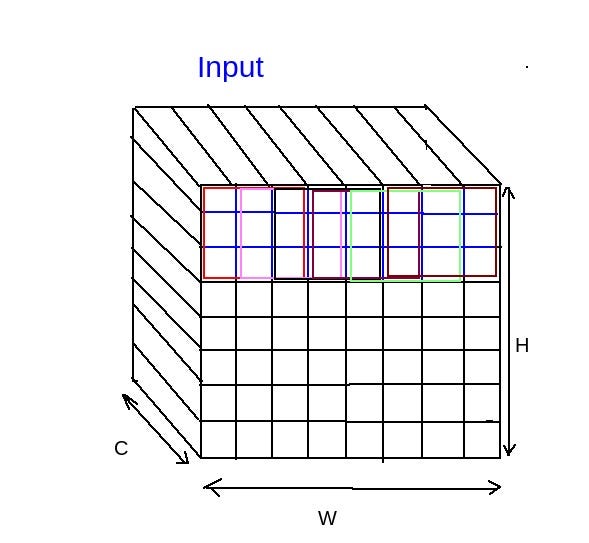
One way to think is to create a filter with the same dimensions as the input. The one like below. There is no more sliding, just broadcast it to C channels and multiply.
The above approach might not work well and also we can’t use different resolutions of images.
So, is there any other way?
Can we come up with a method to keep just 3x3 filter, for example, but a different one at each sliding position on input?
The solution for this is dynamically generating filters at every spatial position based on the neighborhood.
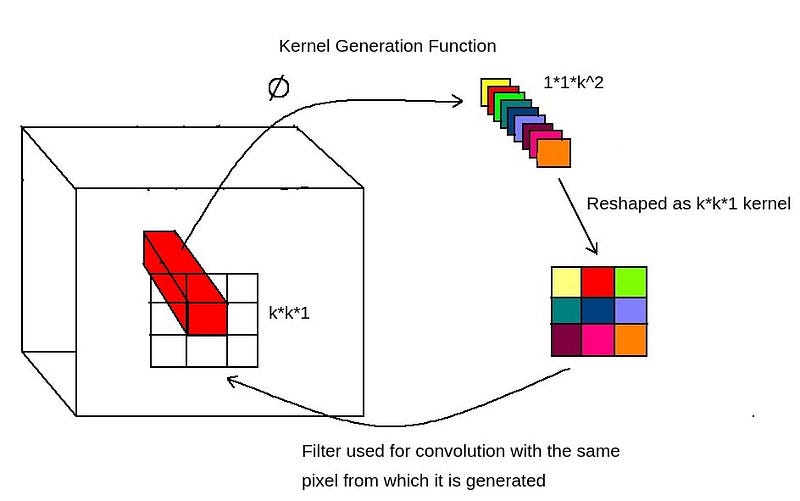
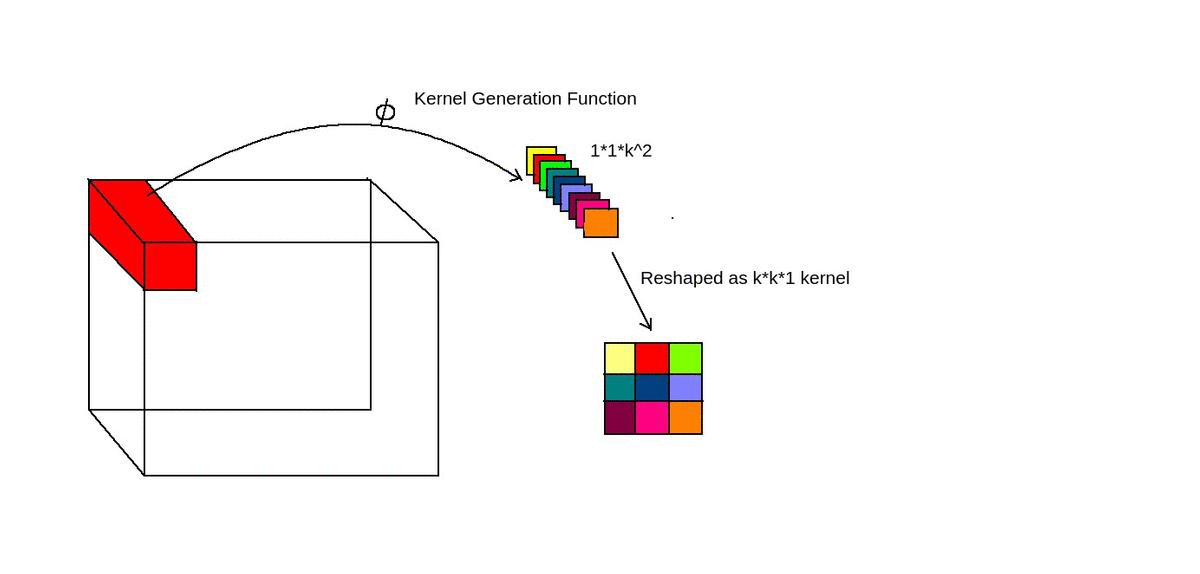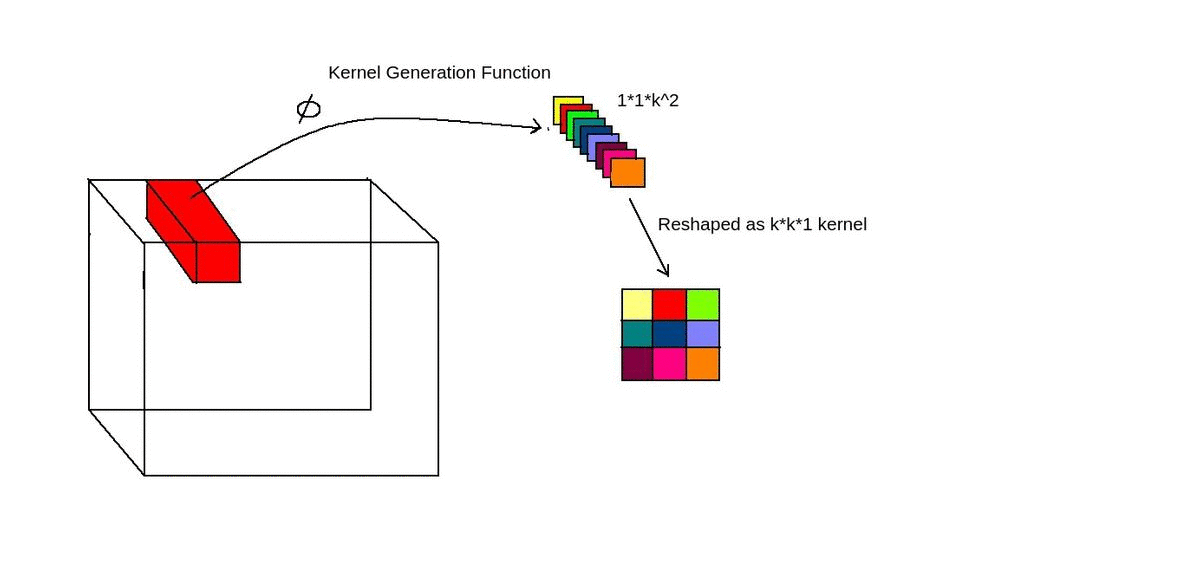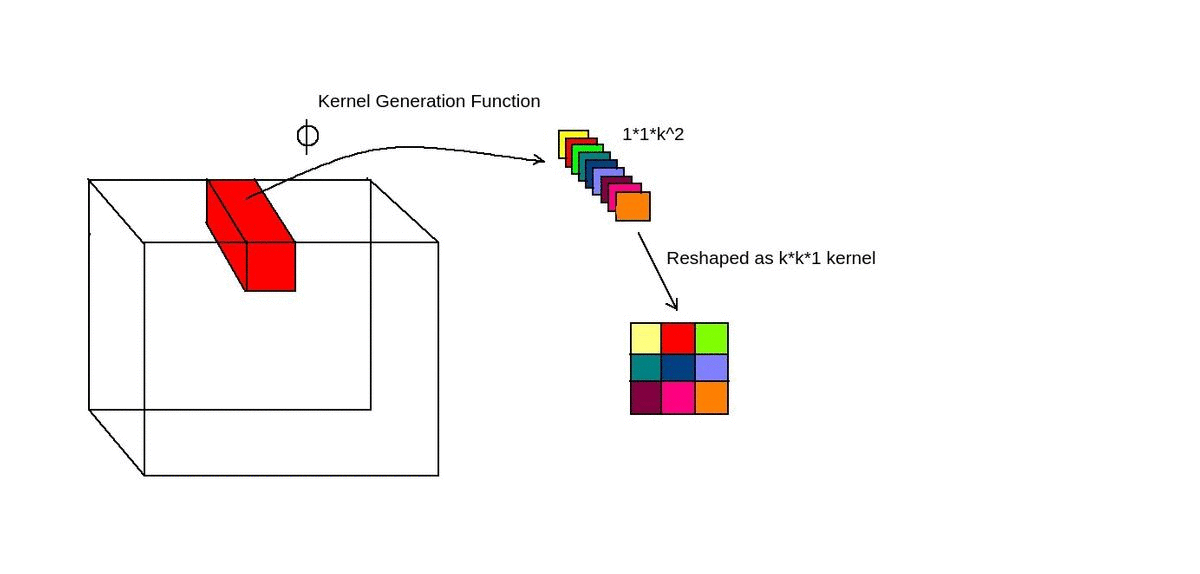
Kernel Generation
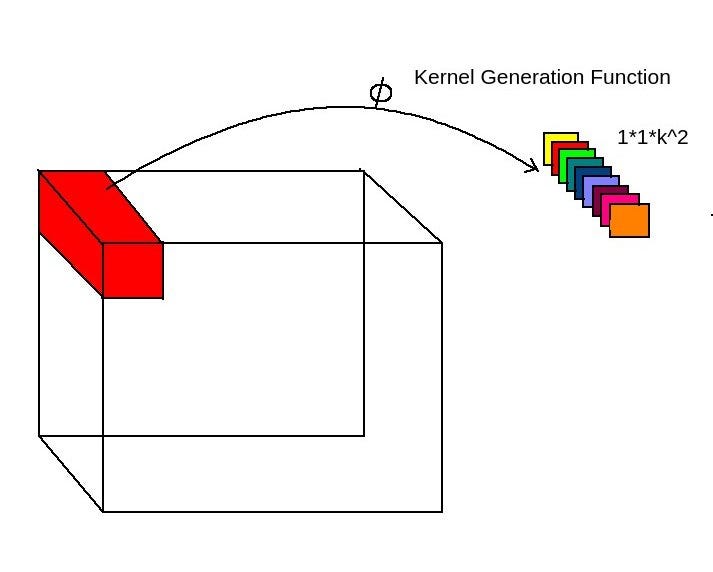
For generating kernel/filter dynamically, a convolution layer is used.
- Take 1x1xC feature block and convert it into 1x1xK² features using convolution layer.
- Phi function is just a convolution layer.
- 1x1xK² features are converted into KxKx1 features using another convolution operation.
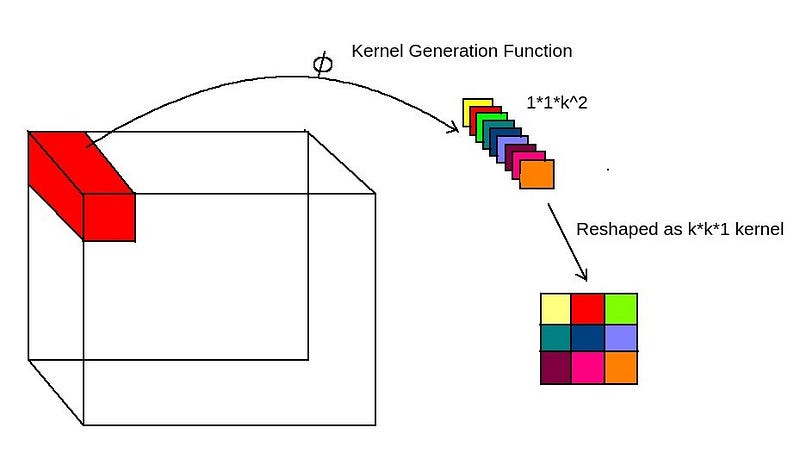
- The KxKx1 filter we get is used for performing element-wise multiplication just as in the case of convolution.
- The same KxK filter is broadcasted across C channels of input (Channel-agnostic).
Below is the Gif demonstrating the kernel generation dynamically at every spatial location.
The final output after performing the Involution operation looks like below.
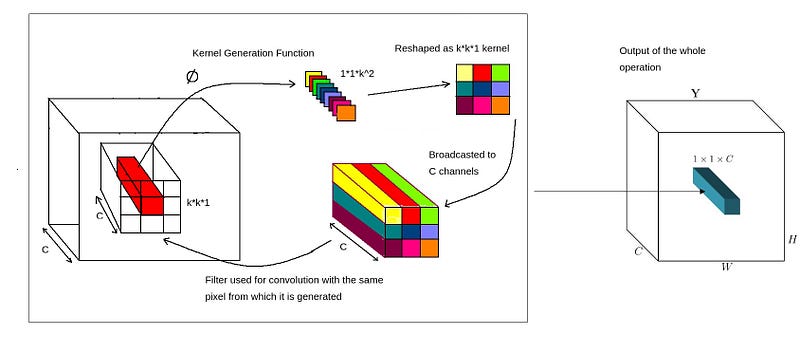
To make it easy for demonstration, I have used KxKx1 filter, but in the actual case, it is KxKxG filters, where G is the number of channel groups. Instead of using a single filter and broadcasts it across all C channels of input, we create G filters and broadcast them into C/G channels each.
Pseudocode of Involution
Below is the pseudocode of the involution operation from the paper. I have added additional comments to make it clear.

This is the fundamental operation that replaces the actual convolution operation.
Experiments
RedNet — a mirror of ResNet with all Convolutions replaced by Involutions except for residual connections. This RedNet was trained on the Imagenet dataset with 224x224 image sizes. Below are the accuracy and speed benchmarks.
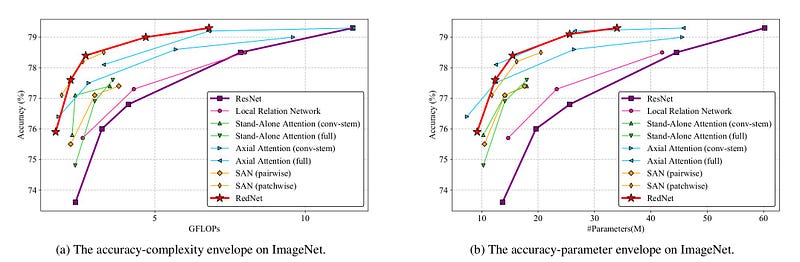
They have done experiments for Object detection and segmentation tasks as well. RedNet backbone performed better than ResNet in both cases.
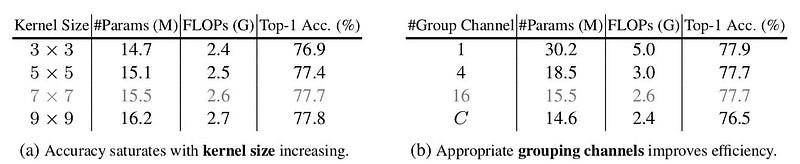
Below are the results of ablation studies on kernel size in Involution operation (K) and channel groups (G).
Conclusion
We have seen that the Involution operation is efficient and effective for visual representation learning. This basic operation will be the building block for upcoming architectures. More details on experiments and ablation studies can be found in the paper. I am sharing the links to both paper and code in the references.
References
- https://arxiv.org/abs/2103.06255
- https://github.com/d-li14/involution
- https://github.com/facebookresearch/detr
Here are some of my posts that you might like.
Originally published at https://mlfornerd.com on May 17, 2021.