
Deep Learning
Context RCNN — Long Term Temporal Context for Per-Camera Object Detection
Dynamically incorporate other frames taken by the same camera into the object detection pipeline.
Hi there! Today we will have a look at Context RCNN, a paper by Google research in association with the California Institute of Technology.
Context
Goal: Object detection on static cameras.
Object detection? — Given an image, you should tell what is in the image and where.
What are static cameras? — You keep the camera in the same place for a long time. Ex: Wild-trap cameras and traffic cameras.
How? — By incorporating past data.
Past Data? — The images that the camera has seen in the past to help the detection in the current frame.
Ok, How far? — Useful context information can stretch far beyond few seconds. Experimented on hours, days, weeks, and months.
How to use that data? — An attention mechanism that runs over a memory of past data.
Base Network? — Faster-RCNN that detects the objects in a single image.
Static Camera Data
Sampling rate — as low as 1 frame per second and sometimes irregular due to motion trigger.
Position — Fixed
Background — Constant

Above is an example of a wild-trap camera. These cameras maintain a low sampling rate. If there is any motion, then it samples at a high frame rate. So the data has irregular sampling rates.
Usually, animals follow the same path every day, so the same animal can get captured on different days. The information missing in the current image might be available in an image from last week. This paper uses that context information for solving the issues with single-frame detection models.
Performance
Let’s have a look at some challenges with these static cameras and how well this method tackles those.


The detections look very impressive. It hasn’t missed even a single object. The model is very good in that it detects the objects which are missed by humans. More of that in the results section.
Now that we have seen it visually, let’s look at the quantitative figures and check if it’s worth going deeper into it.
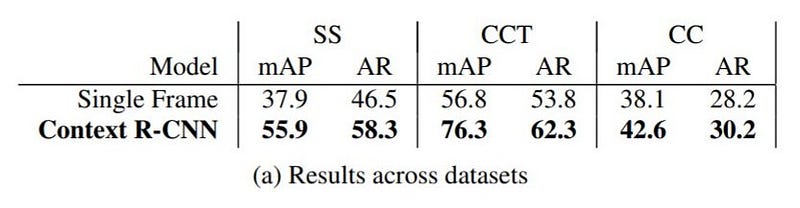
Look at the numbers! There is a huge jump in the mAP. Are you convinced? Continue further if you want to dive into architecture details. Otherwise, Code is available on Tensorflow Object Detection API.
Architecture
Context RCNN builds a “memory bank” based on contextual frames. It modifies the detection model to make predictions based on this memory bank.
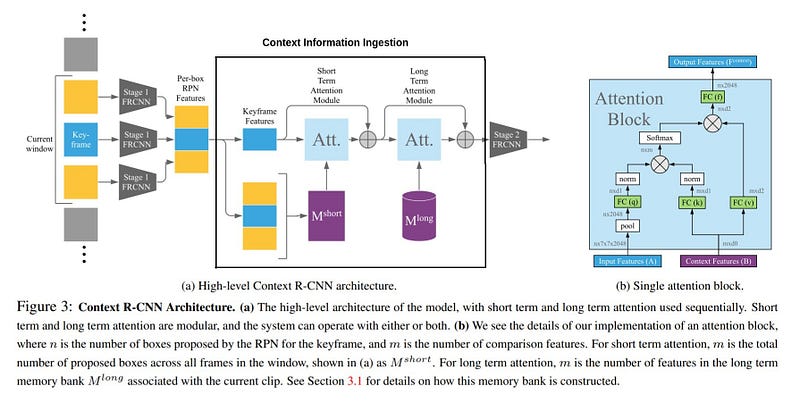
As you can see, It still uses Faster RCNN as the base object detector. This base detector performs detection on a single frame. Faster RCNN is a 2-stage detector. The context information is incorporated between stage-1 and stage-2. Stage-1 uses RPN for generating the boxes. If you don’t know how RPN works, have a look at the below post.
Key Observations
- Keyframe features — Features of the current frame from RPN.
- Context features — Features from a time window before and after the current frame.
- Memory block s— Short term till few frames around the keyframe. Long term span over a very long time horizon into the past.
- Keyframe features propagate to stage-2 via residual connections.
- Information from both short-term and long-term memory is added to keyframe features using an attention mechanism.
- Context features are passed only through the short-term attention module.
- We don’t know how long-term memory is built (there is no connection shown in the architecture diagram).
Now let’s go deeper into each module to understand it better.
Short-term Memory Bank
Short-term memory usually consists of context features from few frames. These features are obtained from the stage-1 detector.
How do you know which features, out of all context features, are helpful for keyframe now? You get it through an attention mechanism.
You can have a look at the attention block in the architecture diagram. The keyframe features are given as Query input and Context features are given as Keys and Values to the attention block.
The similarity between Query and Keys are calculated using dot product and the corresponding weightage is used for fetching the information from Context features.
If you don’t know how the attention module works, have a look at the below post.
Long-term Memory Bank
How is long-term memory built? There is no connection shown in the architecture. Ideally, long-term memory should have context features spanning over a week or a month. And, these features should be calculated during the forward pass of the network as in the case of short-term memory.
Is it feasible? No.
But we do need those features. So how can we do it?
How about using a pre-trained object detector, like Faster RCNN trained on COCO dataset? We can get the prominent features of objects from this. Remember these features are from stage-1. So class information doesn’t matter here.
The authors have used the same approach here. They used a pre-trained object detector for extracting context features for the long-term memory bank.
Now that’s why it is not shown in the architecture as it is not part of the trainable architecture.
These context features from the long-term memory bank are incorporated into the network using an attention module. It works the same way as of short-term case.
Visualizing Attention
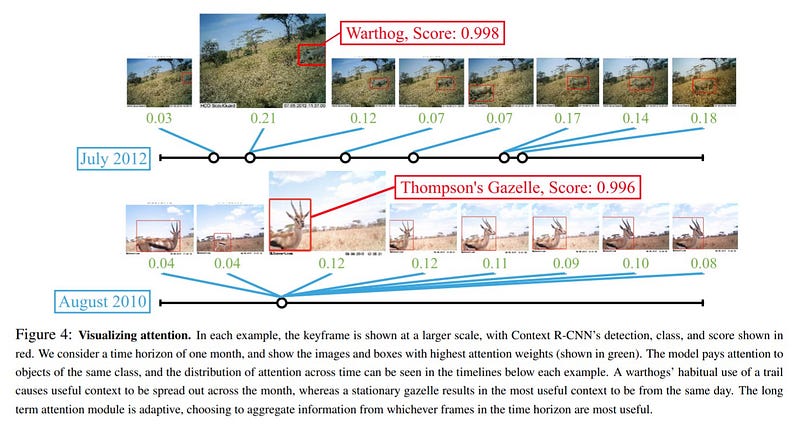
Let’s have a look at how these long-term and short-term features are helpful in detection.
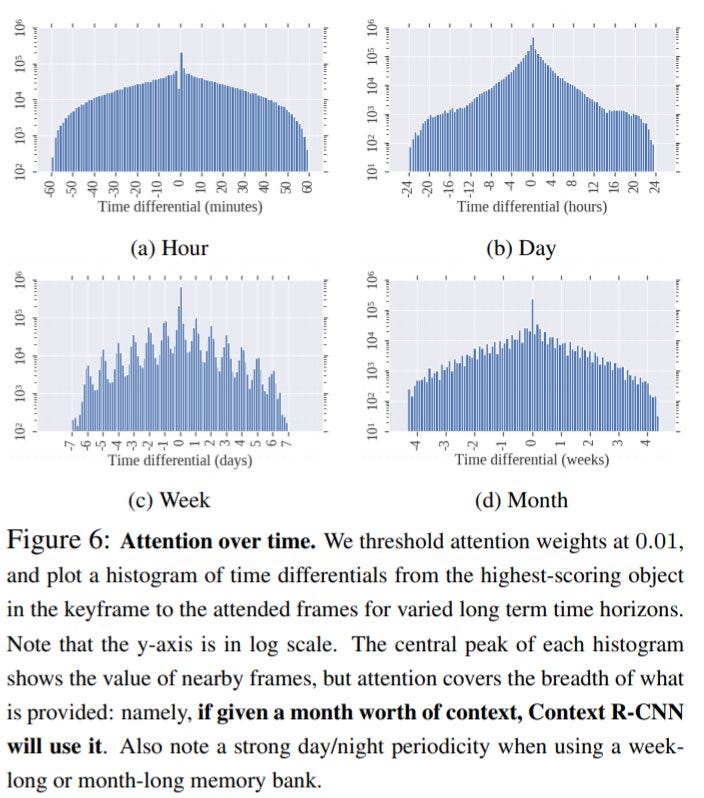
You can see that the context information is distributed uniformly.
Training
Is the network trainable end-to-end? Yes, except the long-term memory bank.
Backpropagation doesn’t happen through the long-term memory bank. It just acts as storage. The context features from both long-term and short-term memory banks are merged into the keyframe features. These weighted features are passed through the stage-2 network for final classification and regression.
Residual connections keep the actual keyframe features intact throughout the flow. This helps in backpropagation as well.
Ablations and Results
We have seen the quantitative figures earlier as a quick overview. Now we will have a detailed analysis of experiments and results.
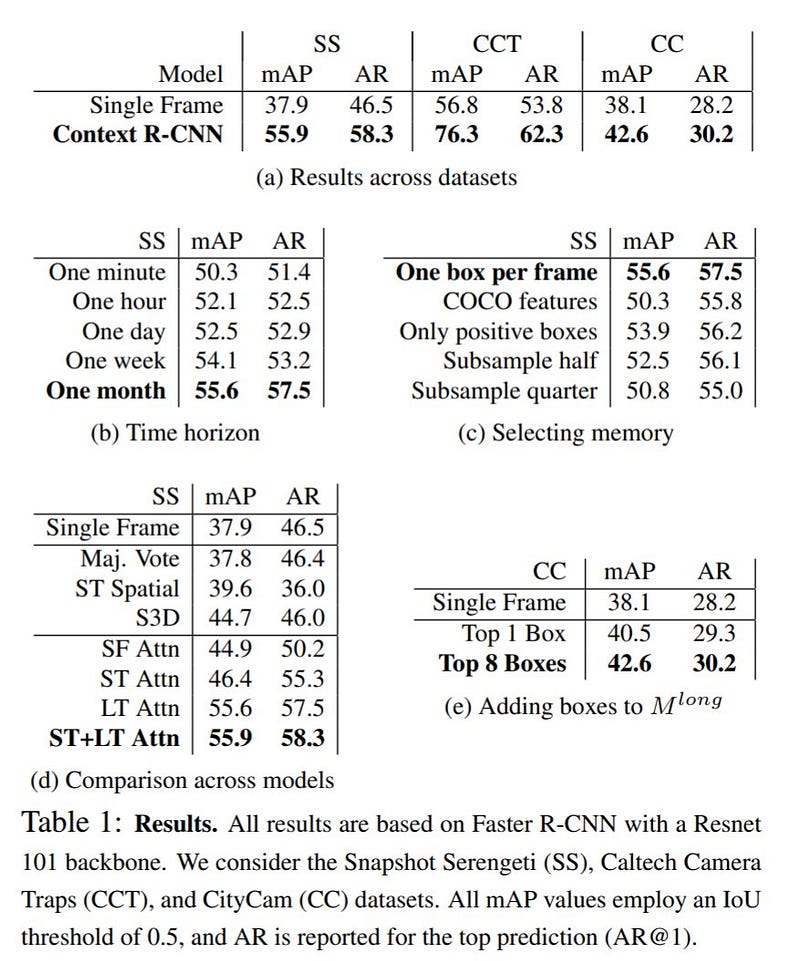
They trained and tested the model on 3 different datasets — Snapshot Serengeti (SS), Caltech Camera Traps (CCT), and CityCam (CC) traffic camera data. They have fine-tuned the COCO object detector for building the long-term memory bank.
mAP figures jumped by 19.5% on CCT, 17.9% on SS, and 4.5% on CC. That’s a huge jump. Recall improves as well, with AR@1 improving 2% on CC, 11.8% on SS, and 8.5% on CCT (table-a).
For the SS dataset, they have tried different time horizons for context features. Using context features over a span of one month gave the best results (table-b).
They have also tried different combinations of short-term and long-term memory banks. Using the combination gave the best results. But long-term memory bank gave a huge improvement in the mAP even if used alone (table-d).
Let’s have a look at the figure below and tell me what you thought.
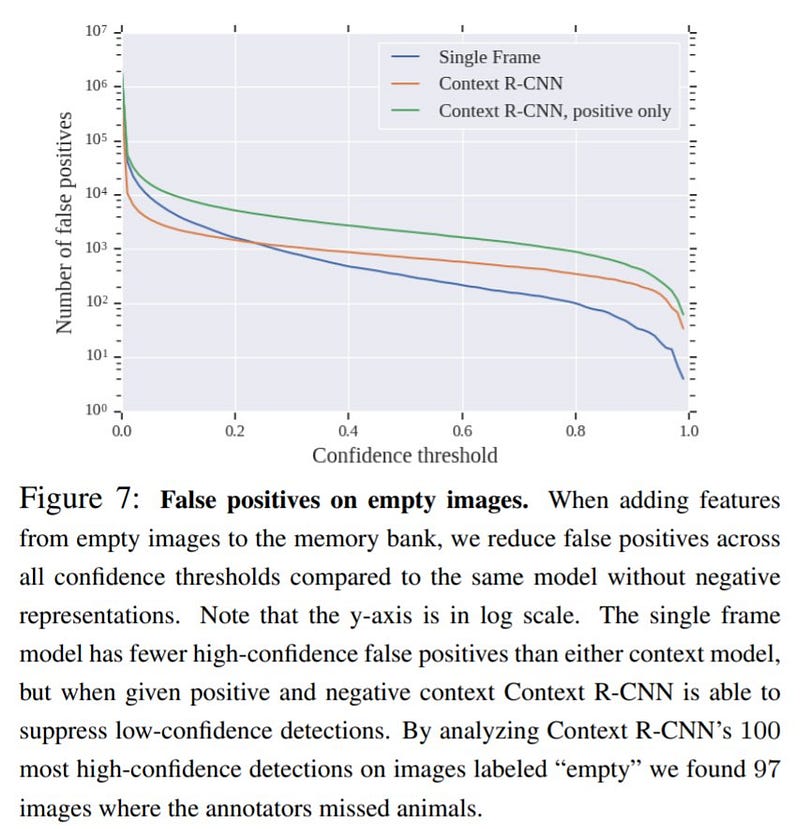
You might argue that the false positives are more. Read the description once. In 97 out of 100 cases, ground-truth is wrong.
There are actual objects present in the image and human annotators missed it because of noise and lack of context.
The remaining 3 images where Context R-CNN erroneously detected an animal were all of the same tree, highly confidently predicted to be a giraffe.
This is a failure mode. If the model predicts confidently, the same prediction spills across the context and performs badly on all the frames further.
Conclusion
We have seen the results, they speak for themselves. This method is general and can be plugged into any base object detector. It can be extended even to other static sensors such as audio and sonar devices. The per-sensor context approach taken by Context R-CNN would be beneficial for any static sensor.
References
- https://arxiv.org/abs/1912.03538 — paper
- https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/context_rcnn.md — Code
Hope you got something out of it. Thank You!