
Deep Learning
Dynamic RCNN — Towards High-Quality Object Detection via Dynamic Training
Fixing the inconsistency problems during training
Hi there! Today we will have a look at Dynamic RCNN, a paper by the researchers of the Chinese Academy Of Sciences.
Overview
Goal: Fixing the inconsistency problems in the training process
Inconsistency? — Network parameters are fixed, but the learning is dynamic. Ex: Quality of the proposals increase as training goes regardless of a certain IOU, but we keep the same IOU throughout the training.
In this paper, they have dealt with 2 inconsistency problems in Network training: Proposal Classification and Bounding box regression.
Let’s see the inconsistency problems in both these cases.
Proposal Classification
The annotations for the object detection task are the bounding boxes of objects. RPN stage generates proposals at every location on the image and we have to assign these proposals to ground truth. It is not very clear how to say that a proposal is positive or negative. The most widely used technique here is to calculate the IOU of the proposal with the GT and find out whether it falls within some threshold.
Let us consider that the IOU threshold is 0.5, now proposals with values more than 0.5 are considered as positive and others are considered as negatives. However, it is observed that having a single IOU threshold throughout the training is degrading the performance and different IOU thresholds result in different performances. Check the graphs below.
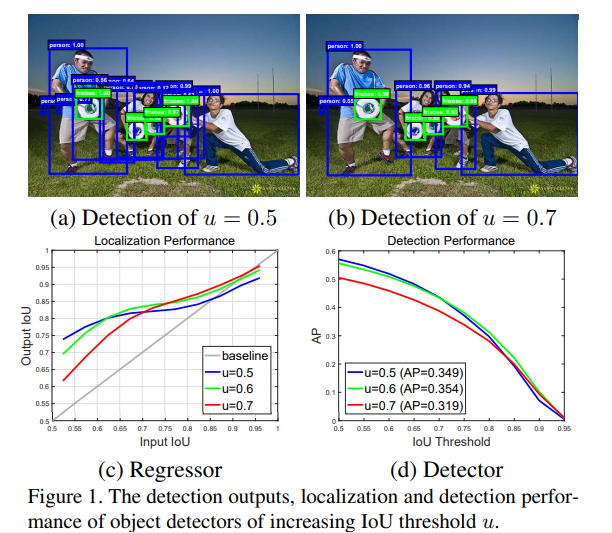
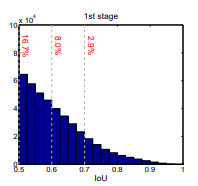
High IOU thresholds give high-quality proposals, but we can’t keep high thresholds at the beginning of training as it won’t give enough positive proposals for the model to learn.
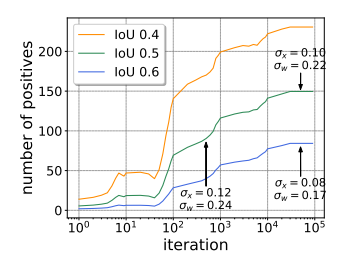
The number of positive proposals increases over time during training. As the number of iterations increases, positive proposals increases.
To solve this issue, Dynamic Label Assigmement is proposed.
Dynamic Label Assignment
Idea: Dynamically change the IOU threshold as learning improves during training
Instead of using a fixed IOU threshold throughout training, threshold T keeps changing.
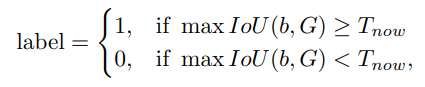
T_now stands for current IOU threshold.
Calculation of T_now:
- Calculate the IoUs I between proposals and their target ground-truths
- Keep storing the K-th largest value from I for C iterations in set S_k
- Take the mean value of S_k as current threshold T_now
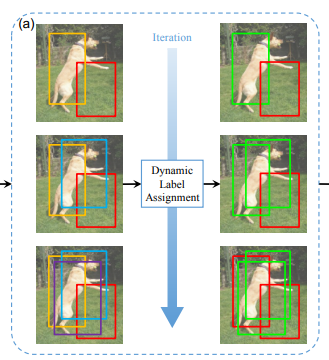
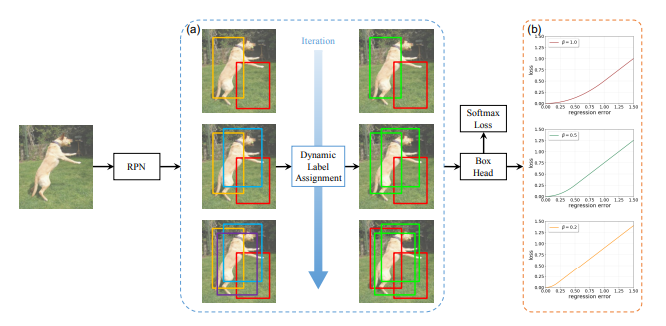
We can find that there are more high-quality proposals as the training goes. With the improved quality of proposals, DLA will automatically raise the IoU threshold based on the proposal distribution. Then positive (green) and negative (red) labels are assigned for the proposals by DLA which are shown in the right part of the figure.
Bounding box regression
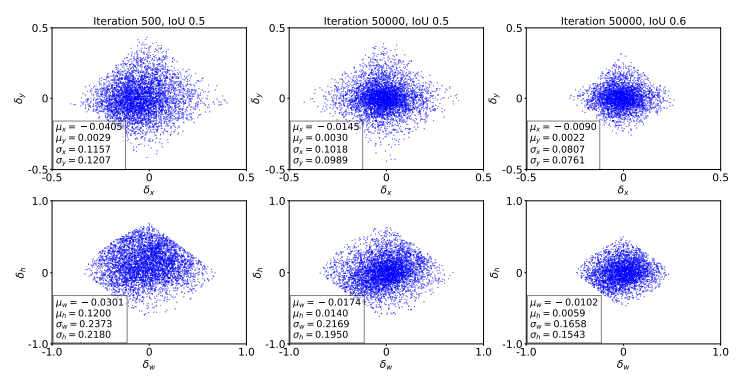
In regression, the task is to regress the positive proposals to their corresponding target ground-truth boxes (offset ∆ = (δx, δy, δw, δh)). These offsets are learned through regression loss function. The distribution of ∆ changes as training goes. Check the figure below.
The smooth L1 loss used for regression is as below:
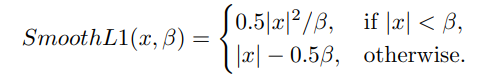
Here the x stands for the regression label. β is a hyper-parameter controlling in which range we should use a softer loss function like l1 loss instead of the original l2 loss. Considering the robustness of training, β is set to default as 1.0 to prevent the exploding loss due to the poorly trained network in the early stages. As you can see in the below figure, smaller β values accelerate the training.
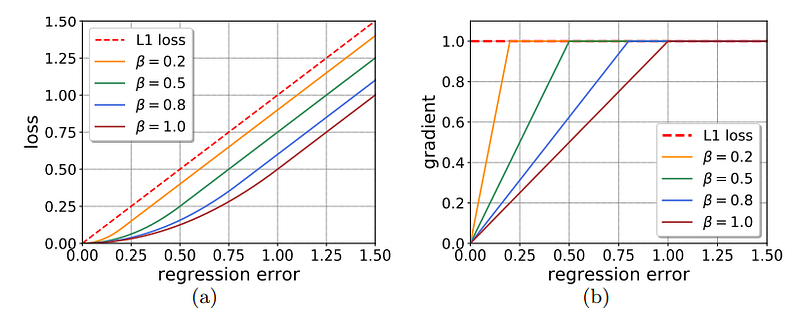
We need to fit the distribution change and adjust the regression loss function to compensate for the high-quality samples.
Dynamic SmoothL1 Loss
Idea: Dynamically change the β values as training goes to improve the quality of proposals.
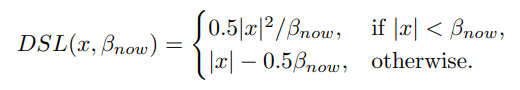
βnow will be calculated as follows:
- Calculate the regression labels E between proposals and their target ground-truths
- Keep storing the K-th smallest value from E for C iterations in set S_k
- Take the median value of S_k as current βnow
Median is chosen instead of mean to deal with outliers.
The whole Dynamic RCNN algorithm can be summarized as below

By dynamically choosing the values of T and β, the quality of learning can be improved.
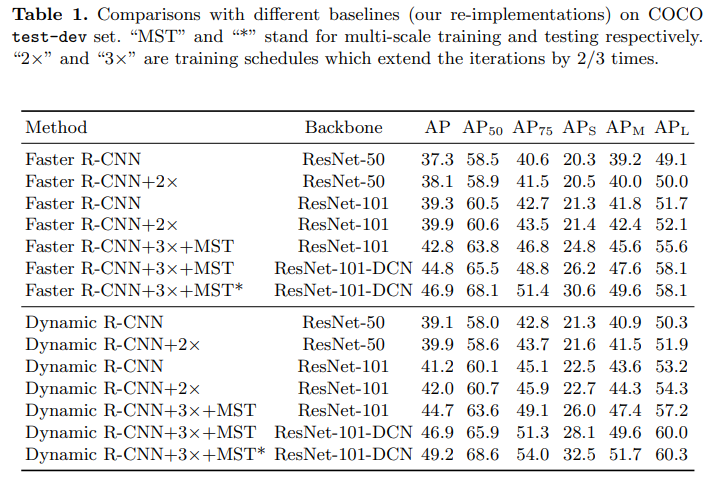
Results
Check out the improvements in Average Precision values below.
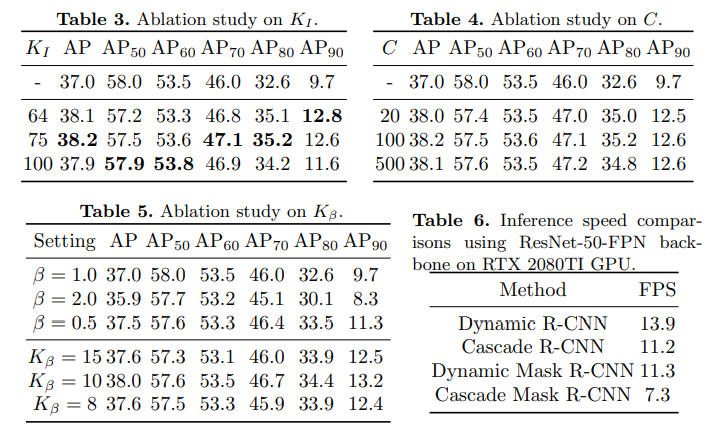
By doing several ablation studies, it is found that values of K, C doesn’t matter. Also, there is no increase in training time as there is no additional computation required except the calculation of mean and median. Check the details below.
References
- https://arxiv.org/abs/2004.06002 — paper
- https://github.com/hkzhang95/DynamicRCNN — Pytorch implementation
- https://arxiv.org/abs/1712.00726 — Cascade RCNN
Check out my previous articles