
Day 59: 60 days of Data Science and Machine Learning Series
NLP and Convolutions…
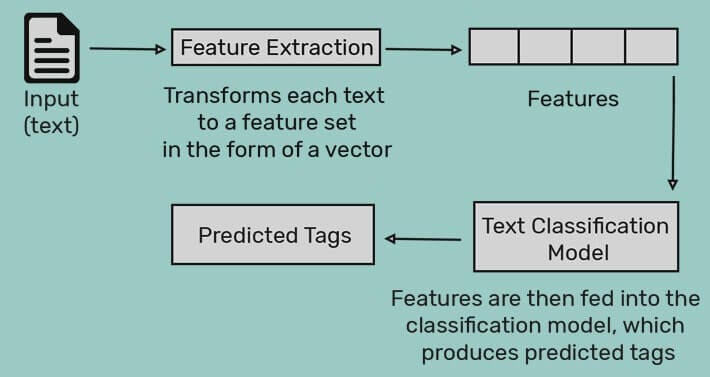
Natural Language Processing is a branch of linguistics, AI and CS for manipulation, translation of natural language which gives the machines an ability to read, understand and derive meaning from human language. It’s an extremely vast field and ( just for) the introductions purpose without dealing with heavy weights , below is a good starting reference point—
Using CNN’s you can perform classifications tasks, such as Text Classification, Sentiment Analysis, Spam Detection or Topic Categorization etc.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
Some of the good reference points for NLP using Convolutions —
In this post we are going to implement 1D Convolutions as Feature Extractors for Text in NLP.
Let’s dive in!
Import Necessary Libraries
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.preprocessing import text, sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import Conv1D, GlobalMaxPooling1D, MaxPooling1D
from sklearn.model_selection import train_test_splitfrom wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as pltLoad and Explore the Data
train_df = pd.read_csv('train.csv').fillna(' ')
x = train_df['comment_text'].values
print(x[2])Output —
Hey man, I'm really not trying to edit war. It's just that this guy is constantly removing relevant information and talking to me through edits instead of my talk page. He seems to care more about the formatting than the actual info.Word Cloud
comments = train_df['comment_text'].loc[train_df['toxic']==1].values
wordcloud = WordCloud(
width = 640,
height = 640,
background_color = 'black',
stopwords = STOPWORDS).generate(str(comments))
fig = plt.figure(
figsize = (12, 8),
facecolor = 'k',
edgecolor = 'k')
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.axis('off')
plt.tight_layout(pad=0)
plt.show()Output —

Value Counts of each class
train_df.toxic.value_counts()Output —
0 144277
1 15294
Name: toxic, dtype: int64Tokenization and Padding
max_features = 20000 mtl = 400 xt = text.Tokenizer(max_features) xt.fit_on_texts(list(x)) xt = xt.texts_to_sequences(x) xtv = sequence.pad_sequences(xt,maxlen = mtl)
Embedding Matrix with Pre-trained GloVe Embeddings
ed = 100
ei = dict()
f = open('glove.6B.100d.txt')for line in f :
v = line.split()
word = v[0]
coefs = np.asarray(v[1:],dtype='float32')
ei[word] = coefs
f.close()
em = np.zeros((max_features,ed))
for w, i in xt.word_index.items():
if i > max_features -1 :
break
else:
ev = ei.get(w)
if ev is not None:
em[i] = evEmbedding Layer
m = Sequential()
m.add(Embedding(max_features,ed,ei=tf.keras.initializers.Constant(em),
trainable= False))
m.add(Dropout(0.2))Build the Model
f= 250
ks = 3
hd = 250m.add(Conv1D(f,ks,padding='valid'))
m.add(MaxPooling1D())
m.add(Conv1D(f,5,padding='valid',activation='relu'))
m.add(GlobalMaxPooling1D())
m.add(Dense(hd,activation='relu'))
m.add(Dropout(0.2))
m.add(Dense(1,activation='sigmoid'))m.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])Train the Model
%%time
x_train,x_val,y_train,y_val = train_test_split(x_train_val,y,test_size=0.15,random_state=1)bs = 32
epochs =3
m.fit(x_train,y_train,batch_size=bs,epochs=3,validation_data=(x_val,y_val))Learnings —
How to use 1D Convolutions as Feature Extractors for Text in NLP, apply Word Embeddings for Text Classification and Perform Binary Text Classification
Day 60: Coming soon!
Follow and Stay tuned. Keep coding :)
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras
That’s it fellas. Peace out and keep coding :)
Stay Tuned and of-course let me end this post with a quote by Steve Jobs ;)
“You have to be burning with an idea, or a problem, or a wrong that you want to right. If you’re not passionate enough from the start, you’ll never stick it out.”




