
Day 58: 60 days of Data Science and Machine Learning Series
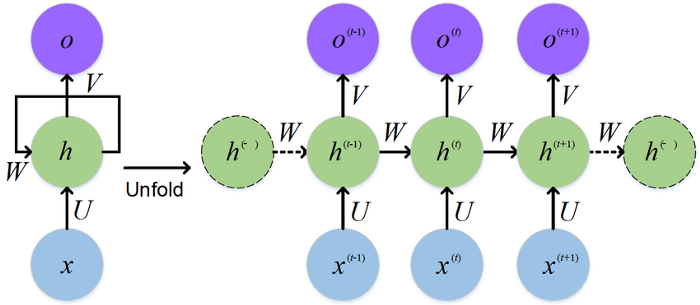
Welcome back peeps. In this post we are going to understand the basics of RNN and LSTM through a project.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
Recurrent Neural Network, created in the 1980’s, is a state of the art algorithm for dealing with sequential data by using internal memory to remember important things about the input RNN’s received to precisely predict what’s coming next. RNN’s are popularly used in language translation, natural language processing (nlp), speech recognition, captioning etc.
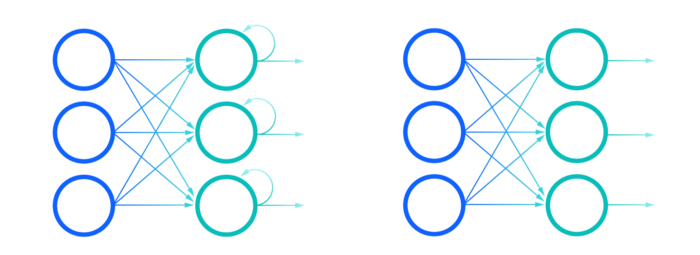
Long Short Term Memory networks (LSTM) introduced by Hochreiter & Schmidhuber are special type of Recurrent Neural Networks ( RNN) designed to avoid the long-term dependency problem and can selectively remember patterns for long duration of time.
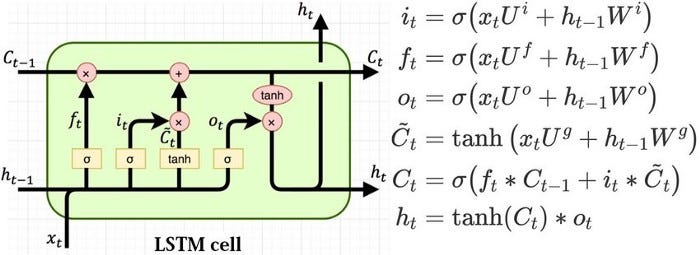
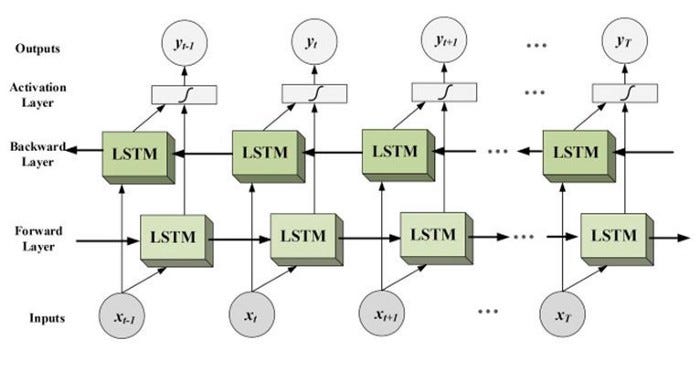
“The Long Short Term Memory architecture was motivated by an analysis of error flow in existing RNNs which found that long time lags were inaccessible to existing architectures, because backpropagated error either blows up or decays exponentially.
An LSTM layer consists of a set of recurrently connected blocks, known as memory blocks. These blocks can be thought of as a differentiable version of the memory chips in a digital computer. Each one contains one or more recurrently connected memory cells and three multiplicative units — the input, output and forget gates — that provide continuous analogues of write, read and reset operations for the cells. … The net can only interact with the cells via the gates.”
— Alex Graves, et al., Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005.
A good reference to understand the vastness of LSTM —
In this post we are going to implement translator using LSTM.
Let’s dive in!
Import libraries and datasets
from collections import Counter
import operator
import plotly.express as px
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud, STOPWORDSfrom sklearn.model_selection import train_test_split
import nltk
import re
from nltk.stem import PorterStemmer, WordNetLemmatizer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from tensorflow.keras.preprocessing.text import one_hot, Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, TimeDistributed, RepeatVector, Embedding, Input, LSTM, Conv1D, MaxPool1D, Bidirectional
from tensorflow.keras.models import Model
from jupyterthemes import jtplot
jtplot.style(theme='monokai', context='notebook', ticks=True, grid=False)
nltk.download('punkt')
nltk.download("stopwords")Load Data and Data Preprocessing
# load the data
df_english = pd.read_csv('small_vocab_en.csv', sep = '/t', names = ['english'])
df_french = pd.read_csv('small_vocab_fr.csv', sep = '/t', names = ['french'])
print(df_english.info())df = pd.concat([df_english,df_french],axis=1)
Output —
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 137860 entries, 0 to 137859
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 english 137860 non-null object
dtypes: object(1)
memory usage: 1.1+ MBRemove Punctuations and Word Cloud
def remove_punc(x):
return re.sub('[!#?,.:";]', '', x)
df['french'] = df['french'].apply(remove_punc)
df['english'] = df['english'].apply(remove_punc)
def guw(x,word_list):
for word in x.split():
if word not in word_list:
word_list.append(word)
df['english'].apply(lambda x:guw(x,english_words))
df['french'].apply(lambda x: guw(x,french_words))
plt.figure(figsize = (20,20))
wc = WordCloud(max_words = 2000, width = 1600, height = 800 ).generate(" ".join(df.english))
plt.imshow(wc, interpolation = 'bilinear')
Output —
Tokenization, Padding and Split the data into train and test set
def tokenize_and_pad(x, maxlen):
# a tokenier to tokenize the words and create sequences of tokenized words
tokenizer = Tokenizer(char_level = False)
tokenizer.fit_on_texts(x)
sequences = tokenizer.texts_to_sequences(x)
padded = pad_sequences(sequences, maxlen = maxlen, padding = 'post')
return tokenizer, sequences, padded
x_tokenizer, x_sequences, x_padded = tokenize_and_pad(df.english, maxlen_english)
y_tokenizer, y_sequences, y_padded = tokenize_and_pad(df.french, maxlen_french)
def pad_to_text(padded, tokenizer):id_to_word = {id: word for word, id in tokenizer.word_index.items()}
id_to_word[0] = ''return ' '.join([id_to_word[j] for j in padded])
pad_to_text(y_padded[0], y_tokenizer)
x_train, x_test, y_train, y_test = train_test_split(x_padded, y_padded, test_size = 0.1)Build and train the model
# Sequential Model
model = Sequential()
# embedding layer
model.add(Embedding(english_vocab_size, 256, input_length = maxlen_english, mask_zero = True))
# encoder
model.add(LSTM(256))
# decoder
# repeatvector repeats the input for the desired number of times to change
# 2D-array to 3D array. For example: (1,256) to (1,23,256)
model.add(RepeatVector(maxlen_french))
model.add(LSTM(256, return_sequences= True ))
model.add(TimeDistributed(Dense(french_vocab_size, activation ='softmax')))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()model.fit(x_train, y_train, batch_size=1024, validation_split= 0.1, epochs=10)Output —
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 15, 256) 51200
_________________________________________________________________
lstm (LSTM) (None, 256) 525312
_________________________________________________________________
repeat_vector (RepeatVector) (None, 24, 256) 0
_________________________________________________________________
lstm_1 (LSTM) (None, 24, 256) 525312
_________________________________________________________________
time_distributed (TimeDistri (None, 24, 351) 90207
=================================================================
Total params: 1,192,031
Trainable params: 1,192,031
Non-trainable params: 0Prediction
def prediction(x, x_tokenizer = x_tokenizer, y_tokenizer = y_tokenizer):
predictions = model.predict(x)[0]
id_to_word = {id: word for word, id in y_tokenizer.word_index.items()}
id_to_word[0] = ''
return ' '.join([id_to_word[j] for j in np.argmax(predictions,1)])Learnings —
How to perform tokenization and padding, create a pipeline to remove stop-words and implement Recurrent Neural Networks and LSTM.
Day 59: Coming soon!
Follow and Stay tuned. Keep coding :)
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras
That’s it fellas. Peace out and keep coding :)
Stay Tuned and of-course let me end this post with a quote by Steve Jobs ;)
“You have to be burning with an idea, or a problem, or a wrong that you want to right. If you’re not passionate enough from the start, you’ll never stick it out.”





