
Day 57: 60 days of Data Science and Machine Learning Series
Deep learning and BERT…
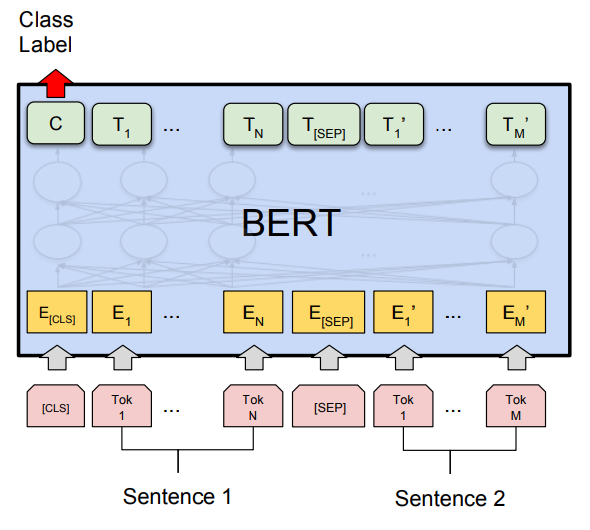
Bidirectional Encoder Representations from Transformers ( BERT) , developed by Google is a deeply bidirectional transformer-based machine learning technique for NLP. It primarily trains the language models based on the complete set of words in a query or sentence during text processing.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
A good reference to understand the vastness of BERT —
Tensorflow is an open source platform for machine learning and deep learning developed by Google Brain Team and written in C++, Python, and CUDA created for large numerical computations and deep learning. It ingests the data in the form of tensors which are nothing but multi-dimensional arrays of higher dimensions to handle large amounts of data. It works on the data flow graphs that have nodes and edges and supports both CPUs and GPUs. It works by preprocessing the data, building the model, training and estimating the model.
A good reference to Tensorflow ( used in this project as well ) —
In this post we will learn how to perform sentiment analysis using BERT.
Let’s dive in!
Import necessary Libraries
import torch
import pandas as pd
from tqdm.notebook import tqdm
from sklearn.model_selection import train_test_splitfrom transformers import BertTokenizer
from torch.utils.data import TensorDataset
from transformers import BertForSequenceClassification
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from transformers import AdamW, get_linear_schedule_with_warmupimport random
seed_val = 17
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)Load Data and Preprocessing
df = pd.read_csv(
'Path to data file/data.csv',
names=['id','text','category'])
df.set_index('id',inplace=True)
df.info()Output —
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3085 entries, 611857364396965889 to 611566876762640384
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 3085 non-null object
1 category 3085 non-null object
dtypes: object(2)
memory usage: 72.3+ KBValue Counts
print(df.category.value_counts())
label_dict = {}
for index, possible_label in enumerate(possible_labels):
label_dict[possible_label] = index
print(label_dict)
df['label'] = df.category.replace(label_dict)Output —
nocode 1572
happy 1137
not-relevant 214
angry 57
surprise 35
sad 32
happy|surprise 11
happy|sad 9
disgust|angry 7
disgust 6
sad|angry 2
sad|disgust 2
sad|disgust|angry 1
Name: category, dtype: int64{'happy': 0,
'not-relevant': 1,
'angry': 2,
'disgust': 3,
'sad': 4,
'surprise': 5}Training/Validation Split
X_train, X_val, y_train,y_val = train_test_split(
df.index.values, df.label.values,test_size=0.15,
random_state=42,stratify=df.label.values)
df['data_type'] = ['not_set'] * df.shape[0]
df.loc[X_train,'data_type'] = 'train'
df.loc[X_val,'data_type'] = 'val'
df.groupby(['category','label','data_type']).count()Tokenization and Encoding
tokenizer = BertTokenizer.from_pretrained(
'bert-base-uncased',
do_lower_case = True
)
edt = tokenizer.batch_encode_plus(df[df.data_type == 'train'].text.values,
add_special_tokens=True,
return_attention_masks=True,
pad_to_max_length=True,
max_length=256,return_tensors = 'pt')
edv = tokenizer.batch_encode_plus(df[df.data_type == 'val'].text.values,
add_special_tokens=True,
return_attention_masks=True,
pad_to_max_length=True,
max_length=256,return_tensors = 'pt')
input_ids_train = edt['input_ids']
attention_mask_train = edt['attention_mask']
labels_train = torch.tensor(df[df.data_type == 'train'].label.values)input_ids_val = edv['input_ids']
attention_mask_val = edv['attention_mask']
labels_val = torch.tensor(df[df.data_type == 'val'].label.values)
dataset_train = TensorDataset(input_ids_train,
attention_mask_train,labels_train)dataset_val = TensorDataset(input_ids_val,attention_mask_val,labels_val)BERT Pretrained Model and Data Loaders
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels = len(label_dict),
output_attentions= False,
output_hidden_states = False
)
batch_size = 4dataloader_train = DataLoader(dataset_train,
sampler = RandomSampler(dataset_train),
batch_size=batch_size
)dataloader_val = DataLoader(dataset_val,
sampler = RandomSampler(dataset_val),
batch_size=32
)Optimizer and Scheduler
optimizer = AdamW(model.parameters(),lr = 1e-5, eps = 1e-8)
epochs = 10
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps=0,
num_training_steps=len(dataloader_train) * epochs)
Creating our Training Loop
def evaluate(dataloader_val):model.eval()
loss_val_total = 0
predictions, true_vals = [], []
for batch in dataloader_val:
batch = tuple(b.to(device) for b in batch)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[2],
}with torch.no_grad():
outputs = model(**inputs)
loss = outputs[0]
logits = outputs[1]
loss_val_total += loss.item()logits = logits.detach().cpu().numpy()
label_ids = inputs['labels'].cpu().numpy()
predictions.append(logits)
true_vals.append(label_ids)
loss_val_avg = loss_val_total/len(dataloader_val)
predictions = np.concatenate(predictions, axis=0)
true_vals = np.concatenate(true_vals, axis=0)
return loss_val_avg, predictions, true_vals
for epoch in tqdm(range(1, epochs+1)):
model.train()
ltt=0
pb = tqdm(dataloader_train,desc ='Epoch {:1d}'.format(epoch),
leave=False,
disable = False)
for b in pb:
model.sero_grad()
btch= tuple(bi.to(device) for bi in b)
inputs = {
'input_ids' : btch[0],
'attention_mask' :btch[1],
'labels' : btch[2]
}
outputs = nodel(**inputs)
loss = outputs[0]
ltt +=loss.items()
loss.backward()
torch.nn_utils.clip_grad_norm_(model.parameters(),1.0)
optimizer.step()
scheduler.step()
pb.set_postfix({'training loss': '{:.2f}'.format(loss.item()/len(batch))
)Load the Model
model = BertForSequenceClassification.from_pretrained("bert-base-uncased",
num_labels=len(label_dict),
output_attentions=False,
output_hidden_states=False)Learnings —
How to clean and preprocess data for BERT, use pretrained BERT with custom output layer and train and evaluate finetuned BERT.
Day 58: Coming soon!
Follow and Stay tuned. Keep coding :)
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras
That’s it fellas. Peace out and keep coding :)
Stay Tuned and of-course let me end this post with a quote by Steve Jobs ;)
“You have to be burning with an idea, or a problem, or a wrong that you want to right. If you’re not passionate enough from the start, you’ll never stick it out.”





