
Day 49: 60 days of Data Science and Machine Learning Series
Yellowbrick for NLP…
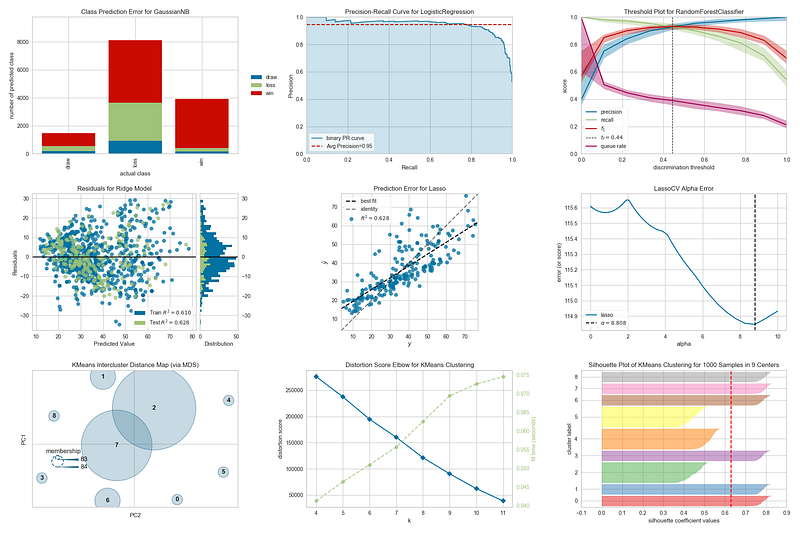
Yellowbrick combines scikit-learn with matplotlib and provides the scikit-learn API to produce visualizations for the machine learning workflow. A good reference point to understand the vastness of Yellowbrick and how to use it —
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
You can install yellowbrick using the command below —
$ pip install yellowbrickIn this post, we will analyze the text data using Yellowbrick and assess document similarity, topic modelling etc that are predicated on the notion of “similarity” between documents.
Import necessary libraries
from sklearn.feature_extraction.text import TfidfVectorizer
from yellowbrick.text import TSNEVisualizerLoad Corpus
from textDB import load_data
corpus = load_data('hobbies')
corpus.categoriesOutput —
['books', 'cinema', 'cooking', 'gaming', 'sports']Vectorize the Documents
vec = TfidfVectorizer()
docs = vec.fit_transform(corpus.data)
labels= corpus.target
docs.shapeOutput —
(448, 21379)Cluster Similar Documents
# Euclidean Distancetsne = TSNEVisualizer(size=(700,500),metrics = 'euclidean')
tsne.fit(docs,labels)
tsne.poof()Output —
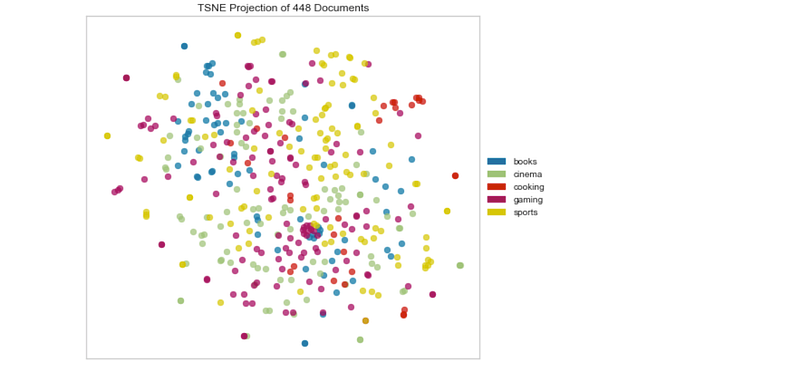
Manhattan Distance
#cityblocktsne = TSNEVisualizer(metic = 'cityblock',size = (700,500))
tsne.fit(docs,labels)
tsne.poof()Output —
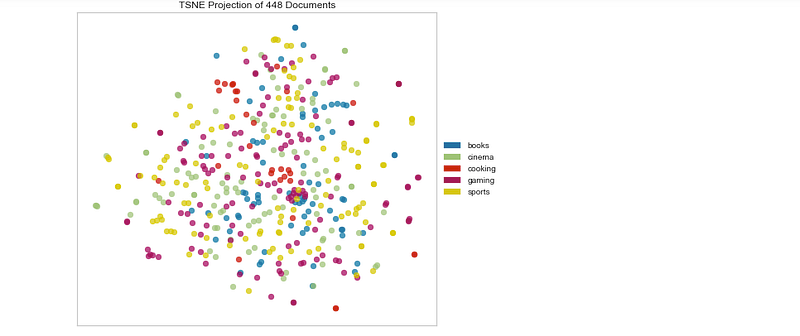
Bray Curtis Dissimilarity
#braycurtistsne = TSNEVisualizer(metric='braycurtis',size=(700,500))
tsne.fit(docs,labels)
tsne.poof()Output —
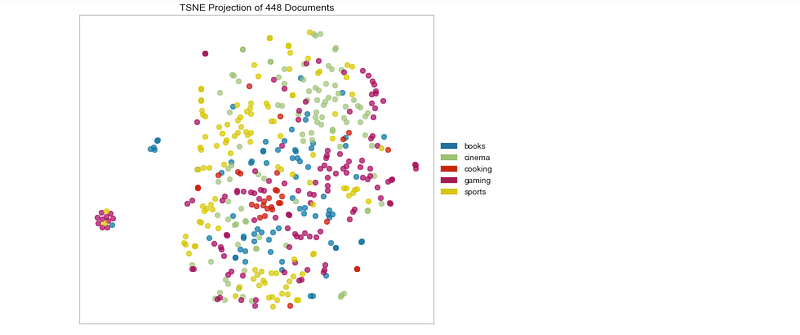
Canberra Distance
tsne = TSNEVisualizer(metric='canberra',size=(700,500))
tsne.fit(docs,labels)
tsne.poof()Output —
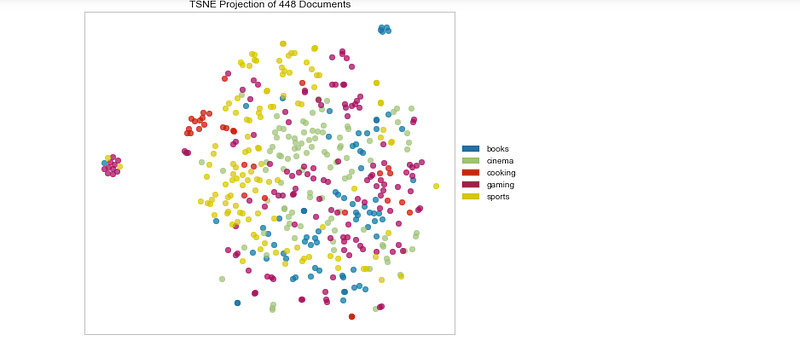
Cosine Distance
tsne = TSNEVisualizer(metric='cosine',size=(700,500))
tsne.fit(docs,labels)
tsne.poof()Output —
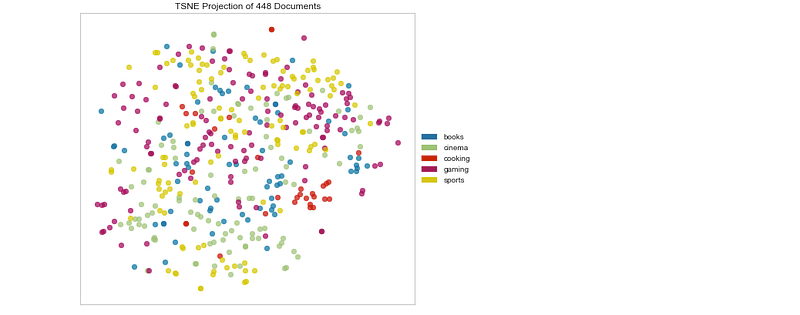
Learnings —
How to vectorize text data using TF-IDF and clustering documents using embedding techniques
Day 50: Coming soon!
Follow and Stay tuned. Keep coding :)
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras
That’s it fellas. Peace out and keep coding :)
Stay Tuned and of-course let me end this post with a quote by Steve Jobs ;)
“Your work is going to fill a large part of your life, and the only way to be truly satisfied is to do what you believe is great work. And the only way to do great work is to love what you do. If you haven’t found it yet, keep looking. Don’t settle. As with all matters of the heart, you’ll know when you find it.”





