
Day 47: 60 days of Data Science and Machine Learning Series
RNN and LSTM with a project…

Recurrent Neural Network, created in the 1980’s, is a state of the art algorithm for dealing with sequential data by using internal memory to remember important things about the input RNN’s received to precisely predict what’s coming next. RNN’s are popularly used in language translation, natural language processing (nlp), speech recognition, captioning etc.
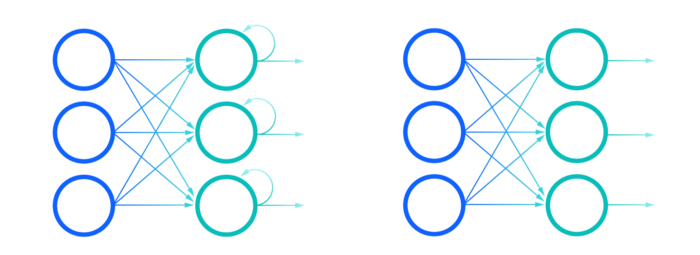
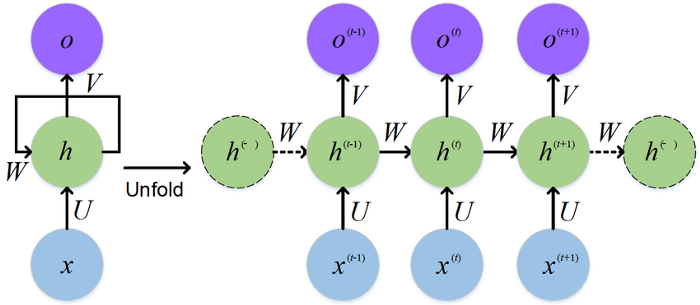
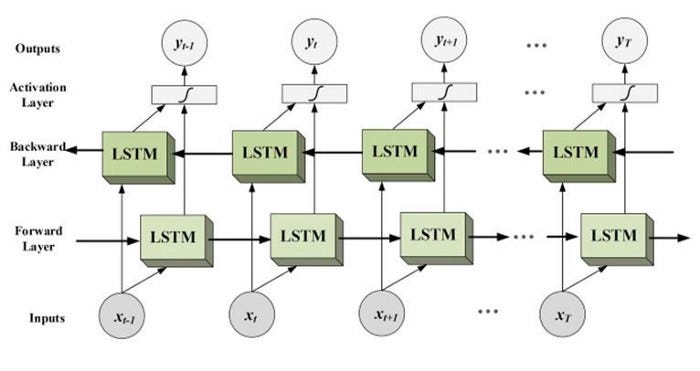
Long Short Term Memory networks (LSTM) introduced by Hochreiter & Schmidhuber are special type of Recurrent Neural Networks ( RNN) designed to avoid the long-term dependency problem and can selectively remember patterns for long duration of time.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
In this post we will implement a project in which we will build model to detect Fake News. The data for this project can be found ( at below link) —
Let’s dive in!
Import necessary libraries
import nltk
nltk.download('punkt')
nltk.download("stopwords")
from nltk.corpus import stopwordsimport tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud, STOPWORDS
import nltk
import re
from nltk.stem import PorterStemmer, WordNetLemmatizer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenizefrom nltk import word_tokenize
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDSfrom sklearn.model_selection import train_test_split
import kerasfrom sklearn.metrics import accuracy_score
from tensorflow.keras.preprocessing.text import one_hot, Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Embedding, Input, LSTM, Conv1D, MaxPool1D, Bidirectional
from tensorflow.keras.models import Model
from jupyterthemes import jtplot
jtplot.style(theme='monokai', context='notebook', ticks=True, grid=False)Load datasets
# load the data
df_true = pd.read_csv("Path to data file/True.csv")
df_fake = pd.read_csv("Path to data file/Fake.csv")Explore data and feature engineering
df_true['isfake'] = 1
df_fake['isfake'] = 0
df = pd.concat([df_true, df_fake]).reset_index(drop = True)
df.drop(columns = ['date'], inplace = True)
df['original'] = df['title'] + ' ' + df['text']
Perform Data Cleaning
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
def preprocess(text):
result = []
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3 and token not in stop_words:
result.append(token)
return result
df['clean'] = df['original'].apply(preprocess)
print(df['clean'][0])
list_of_words = []
for i in df.clean:
for j in i:
list_of_words.append(j)
total_words = len(list(set(list_of_words)))
df['clean_joined'] = df['clean'].apply(lambda x: " ".join(x))Output —
['budget', 'fight', 'looms', 'republicans', 'flip', 'fiscal', 'script', 'washington', 'reuters', 'head', 'conservative', 'republican', 'faction', 'congress', 'voted', 'month', 'huge', 'expansion', 'national', 'debt', 'cuts', 'called', 'fiscal', 'conservative', 'sunday', 'urged', 'budget', 'restraint', 'keeping', 'sharp', 'pivot', 'republicans', 'representative', 'mark', 'meadows', 'speaking', 'face', 'nation', 'drew', 'hard', 'line', 'federal', 'spending', 'lawmakers', 'bracing', 'battle', 'january', 'return', 'holidays', 'wednesday', 'lawmakers', 'begin', 'trying', 'pass', 'federal', 'budget', 'fight', 'likely', 'linked', 'issues', 'immigration', 'policy', 'november', 'congressional', 'election', 'campaigns', 'approach', 'republicans', 'seek', 'control', 'congress', 'president', 'donald', 'trump', 'republicans', 'want', 'budget', 'increase', 'military', 'spending', 'democrats', 'want', 'proportional', 'increases', 'defense', 'discretionary', 'spending', 'programs', 'support', 'education', 'scientific', 'research', 'infrastructure', 'public', 'health', 'environmental', 'protection', 'trump', 'administration', 'willing', 'going', 'increase', 'defense', 'discretionary', 'spending', 'percent', 'meadows', 'chairman', 'small', 'influential', 'house', 'freedom', 'caucus', 'said', 'program', 'democrats', 'saying', 'need', 'government', 'raise', 'percent', 'fiscal', 'conservative', 'rationale', 'eventually', 'people', 'money', 'said', 'meadows', 'republicans', 'voted', 'late', 'december', 'party', 'debt', 'financed', 'overhaul', 'expected', 'balloon', 'federal', 'budget', 'deficit', 'trillion', 'years', 'trillion', 'national', 'debt', 'interesting', 'hear', 'mark', 'talk', 'fiscal', 'responsibility', 'democratic', 'representative', 'joseph', 'crowley', 'said', 'crowley', 'said', 'republican', 'require', 'united', 'states', 'borrow', 'trillion', 'paid', 'future', 'generations', 'finance', 'cuts', 'corporations', 'rich', 'fiscally', 'responsible', 'bills', 'seen', 'passed', 'history', 'house', 'representatives', 'think', 'going', 'paying', 'years', 'come', 'crowley', 'said', 'republicans', 'insist', 'package', 'biggest', 'overhaul', 'years', 'boost', 'economy', 'growth', 'house', 'speaker', 'paul', 'ryan', 'supported', 'recently', 'went', 'meadows', 'making', 'clear', 'radio', 'interview', 'welfare', 'entitlement', 'reform', 'party', 'calls', 'republican', 'priority', 'republican', 'parlance', 'entitlement', 'programs', 'mean', 'food', 'stamps', 'housing', 'assistance', 'medicare', 'medicaid', 'health', 'insurance', 'elderly', 'poor', 'disabled', 'programs', 'created', 'washington', 'assist', 'needy', 'democrats', 'seized', 'ryan', 'early', 'december', 'remarks', 'saying', 'showed', 'republicans', 'overhaul', 'seeking', 'spending', 'cuts', 'social', 'programs', 'goals', 'house', 'republicans', 'seat', 'senate', 'votes', 'democrats', 'needed', 'approve', 'budget', 'prevent', 'government', 'shutdown', 'democrats', 'leverage', 'senate', 'republicans', 'narrowly', 'control', 'defend', 'discretionary', 'defense', 'programs', 'social', 'spending', 'tackling', 'issue', 'dreamers', 'people', 'brought', 'illegally', 'country', 'children', 'trump', 'september', 'march', 'expiration', 'date', 'deferred', 'action', 'childhood', 'arrivals', 'daca', 'program', 'protects', 'young', 'immigrants', 'deportation', 'provides', 'work', 'permits', 'president', 'said', 'recent', 'twitter', 'messages', 'wants', 'funding', 'proposed', 'mexican', 'border', 'wall', 'immigration', 'changes', 'exchange', 'agreeing', 'help', 'dreamers', 'representative', 'debbie', 'dingell', 'told', 'favor', 'linking', 'issue', 'policy', 'objectives', 'wall', 'funding', 'need', 'daca', 'clean', 'said', 'wednesday', 'trump', 'aides', 'meet', 'congressional', 'leaders', 'discuss', 'issues', 'followed', 'weekend', 'strategy', 'sessions', 'trump', 'republican', 'leaders', 'white', 'house', 'said', 'trump', 'scheduled', 'meet', 'sunday', 'florida', 'republican', 'governor', 'rick', 'scott', 'wants', 'emergency', 'house', 'passed', 'billion', 'package', 'hurricanes', 'florida', 'texas', 'puerto', 'rico', 'wildfires', 'california', 'package', 'exceeded', 'billion', 'requested', 'trump', 'administration', 'senate', 'voted']Visualize the cleaned data
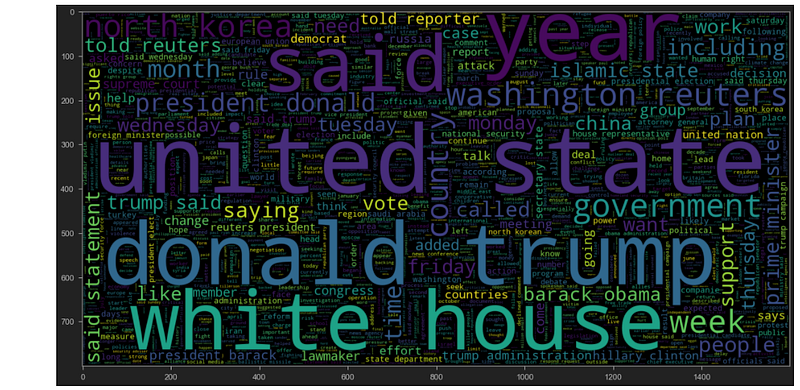
#Real plt.figure(figsize = (20,20))
wc = WordCloud(max_words = 2000 , width = 1600 , height = 800 , stopwords = stop_words).generate(" ".join(df[df.isfake == 1].clean_joined))
plt.imshow(wc, interpolation = 'bilinear')Output —
# Fakeplt.figure(figsize = (20,20))
wc = WordCloud(max_words = 2000 , width = 1600 , height = 800 , stopwords = stop_words).generate(" ".join(df[df.isfake == 0].clean_joined))
plt.imshow(wc, interpolation = 'bilinear')Output —
# length of maximum document will be needed to create word embeddings
maxlen = -1
for doc in df.clean_joined:
tokens = nltk.word_tokenize(doc)
if(maxlen<len(tokens)):
maxlen = len(tokens)
print("The maximum number of words in any document is =", maxlen)Output —
The maximum number of words in any document is = 4405Tokenizing and padding
tokenizer = Tokenizer(num_words = total_words)
tokenizer.fit_on_texts(x_train)
train_sequences = tokenizer.texts_to_sequences(x_train)
test_sequences = tokenizer.texts_to_sequences(x_test)
padded_train = pad_sequences(train_sequences,maxlen = 40, padding = 'post', truncating = 'post')
padded_test = pad_sequences(test_sequences,maxlen = 40, truncating = 'post')
for i,doc in enumerate(padded_train[:2]):
print("The padded encoding for document",i+1," is : ",doc)Output —
The padded encoding for document 1 is : [ 2365 558 332 2311 2716 42 972 27 11043 950 513 120
258 57 30 558 332 6402 972 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
The padded encoding for document 2 is : [ 49 183 5 3537 231 75 4423 20 877 694 751 4037 16 12 20 278 316 694 751 838 38 204 23342 844 1023 694 49568 9060 4 4423 348 4631 352 98 45 20 521 694 751 355]Build and train the model
# Sequential Model
model = Sequential()# embeddidng layer
model.add(Embedding(total_words, output_dim = 128))
# model.add(Embedding(total_words, output_dim = 240))# Bi-Directional RNN and LSTM
model.add(Bidirectional(LSTM(128)))# Dense layers
model.add(Dense(128, activation = 'relu'))
model.add(Dense(1,activation= 'sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
model.summary()Output —
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 128) 13914112
_________________________________________________________________
bidirectional_3 (Bidirection (None, 256) 263168
_________________________________________________________________
dense_6 (Dense) (None, 128) 32896
_________________________________________________________________
dense_7 (Dense) (None, 1) 129
=================================================================
Total params: 14,210,305
Trainable params: 14,210,305
Non-trainable params: 0
_________________________________________________________________y_train = np.asarray(y_train)
model.fit(padded_train, y_train, batch_size = 64, validation_split = 0.1, epochs = 2)Output —
Train on 32326 samples, validate on 3592 samples
Epoch 1/2
32326/32326 [==============================] - 321s 10ms/sample - loss: 0.0421 - acc: 0.9815 - val_loss: 0.0073 - val_acc: 0.9992
Epoch 2/2
32326/32326 [==============================] - 316s 10ms/sample - loss: 0.0016 - acc: 0.9997 - val_loss: 0.0096 - val_acc: 0.9981Performance Analysis
pred = model.predict(padded_test)
# if the predicted value is >0.5 it is real else it is fake
prediction = []
for i in range(len(pred)):
if pred[i].item() > 0.5:
prediction.append(1)
else:
prediction.append(0)
accuracy = accuracy_score(list(y_test), prediction)print("Model Accuracy : ", accuracy)Output —
Model Accuracy : 0.9968819599109131Learnings —
How to RNN, LSTM, create a pipeline to remove stop-words ,perform tokenization, build a model and evaluate its performance.
Day 48: Coming soon!
Follow and Stay tuned. Keep coding :)
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras
That’s it fellas. Peace out and keep coding :)
Stay Tuned and of-course let me end this post with a quote by Steve Jobs ;)
“Your work is going to fill a large part of your life, and the only way to be truly satisfied is to do what you believe is great work. And the only way to do great work is to love what you do. If you haven’t found it yet, keep looking. Don’t settle. As with all matters of the heart, you’ll know when you find it.”





