
Day 44: 60 days of Data Science and Machine Learning Series
LSTM with Keras…
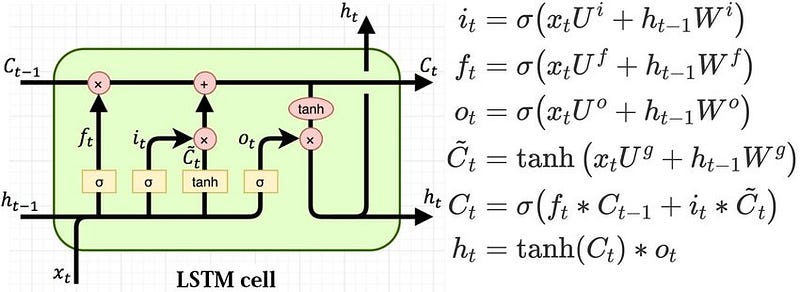
Welcome back peeps. In this post we are going to understand the basics of LSTM with Keras through a project.
Long Short Term Memory networks (LSTM) introduced by Hochreiter & Schmidhuber are special type of Recurrent Neural Networks ( RNN) designed to avoid the long-term dependency problem and can selectively remember patterns for long duration of time.
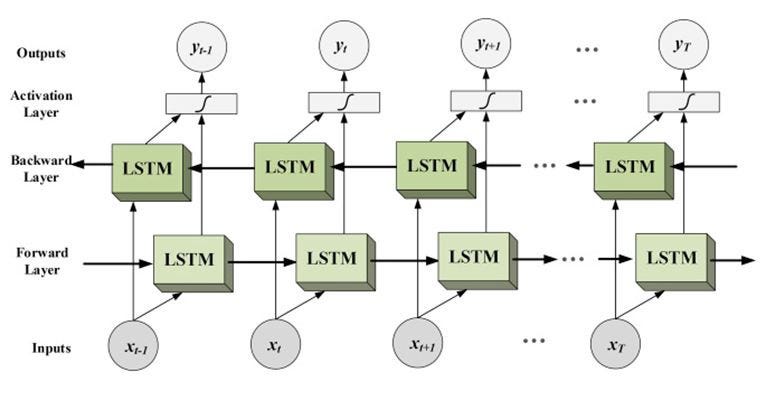
“The Long Short Term Memory architecture was motivated by an analysis of error flow in existing RNNs which found that long time lags were inaccessible to existing architectures, because backpropagated error either blows up or decays exponentially.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
An LSTM layer consists of a set of recurrently connected blocks, known as memory blocks. These blocks can be thought of as a differentiable version of the memory chips in a digital computer. Each one contains one or more recurrently connected memory cells and three multiplicative units — the input, output and forget gates — that provide continuous analogues of write, read and reset operations for the cells. … The net can only interact with the cells via the gates.”
— Alex Graves, et al., Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005.
A good reference to understand the vastness of LSTM —
In this we are going to implement bidirectional LSTM through a project.The Data for this project can be found ( at below link) :
Let’s dive in!
Import necessary libraries
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.random.seed(0)
plt.style.use("ggplot")import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from tensorflow.keras import Model, Input
from tensorflow.keras.layers import LSTM, Embedding, Dense
from tensorflow.keras.layers import TimeDistributed, SpatialDropout1D, Bidirectional
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from livelossplot.tf_keras import PlotLossesCallbackLoad and Explore the Dataset
data = pd.read_csv('Path to data file/datav1.4.csv',encoding ='latin1')
data = data.fillna(method = 'ffill')
# Unique wordsprint(data['Word'].nunique())
print(data['Tag'].nunique())
words = list(set(data['Word'].values))
words.append('ENDPAD')
num_words = len(words)
tags= list(set(data['Tag'].values))
num_tags = len(tags)
num_words, num_tagsOutput —
35178
17
(35179, 17)Retrieve Sentences and Tags
class sg(object):
def __init__(self,data):
self.n_sent = 1
self.data = data
af = lambda s: [(w,p,t) for w,p,t in zip(s['Word'].values.tolist(),
s['POS'].values.tolist(),
s['Tag'].values.tolist())]
self.grouped = self.data.groupby('Sentence #').apply(af)
self.sentences = [s for s in self.grouped]
g = sg(data)
s = g.sentences
s[2]Output —
[('Helicopter', 'NN', 'O'),
('gunships', 'NNS', 'O'),
('Saturday', 'NNP', 'B-tim'),
('pounded', 'VBD', 'O'),
('militant', 'JJ', 'O'),
('hideouts', 'NNS', 'O'),
('in', 'IN', 'O'),
('the', 'DT', 'O'),
('Orakzai', 'NNP', 'B-geo'),
('tribal', 'JJ', 'O'),
('region', 'NN', 'O'),
(',', ',', 'O'),
('where', 'WRB', 'O'),
('many', 'JJ', 'O'),
('Taliban', 'NNP', 'B-org'),
('militants', 'NNS', 'O'),
('are', 'VBP', 'O'),
('believed', 'VBN', 'O'),
('to', 'TO', 'O'),
('have', 'VB', 'O'),
('fled', 'VBN', 'O'),
('to', 'TO', 'O'),
('avoid', 'VB', 'O'),
('an', 'DT', 'O'),
('earlier', 'JJR', 'O'),
('military', 'JJ', 'O'),
('offensive', 'NN', 'O'),
('in', 'IN', 'O'),
('nearby', 'JJ', 'O'),
('South', 'NNP', 'B-geo'),
('Waziristan', 'NNP', 'I-geo'),
('.', '.', 'O')]Mappings
wi = {w: i+1 for i,w in enumerate(words)}
ti = {t: i for i,t, in enumerate(tags)}
wiOutput —
{'Pan': 1,
'809': 2,
'Series': 3,
'semifinals': 4,
'Luka': 5,
'estate': 6,
'clamp': 7,
'ripening': 8,
'Goot': 9,
'Northern': 10,
'power-sharing': 11,
'surpass': 12,
'trained': 13,
'morally': 14,
'Observers': 15,
'predictions': 16,
'upswing': 17,
'Kasai': 18,
'diversity': 19,
'sixth-largest': 20,
'140': 21,
'loaded': 22,
'unaware': 23,
'catwalk': 24,
'453': 25,
'Boel': 26,
'brilliant': 27,
'unbiased': 28,
'Dujail': 29,
'verdict': 30,
'representative': 31,
'regarded': 32,
'commonly': 33,
'troubled': 34,
'Janice': 35,
'Gilchrist': 36,
'Yunlin': 37,
'by-election': 38,
'Condoleezza': 39,
'registered': 40,
'decelerated': 41,
'unfurling': 42,
'hedge': 43,
'Afghan': 44,
'tsunami': 45,
'sustaining': 46,
'Settled': 47,
'Bangladesh': 48,
'plank': 49,
'1970s': 50,
'integrate': 51,
'American-born': 52,
'sideways': 53,
'45.2': 54,
'NZ': 55,
'selfish': 56,
'Kor': 57,
'nomadic': 58,
'nationwide': 59,
'Reza': 60,
'trillions': 61,
'Shahid': 62,
'disclose': 63,
'Chandipur': 64,
'Napa': 65,
'Hare': 66,
'joyous': 67,
'anti-Eritrean': 68,
'Shigeru': 69,
'Davos': 70,
'Rhodesia': 71,
'recoverable': 72,
'Rajapakshe': 73,
'Daron': 74,
'best-seller': 75,
'Chubais': 76,
'government-controlled': 77,
'Mohmand': 78,
'channeling': 79,
'Waziriyah': 80,
'1,254': 81,
'tendrils': 82,
'sexual': 83,
'Smyr': 84,
'Cavalese': 85,
'Sufa': 86,
'1,460': 87,
'jailing': 88,
'single-dose': 89,
'polling': 90,
'founding': 91,
'Dal': 92,
'aragonite': 93,
'spewing': 94,
'Nursery': 95,
'assists': 96,
'Pastrana': 97,
'Nikkei': 98,
'touchdown': 99,
'Triple': 100,
'shaky': 101,
'backfired': 102,
'attributes': 103,
'Qasim': 104,
'examples': 105,
'war-crimes': 106,
'conservatives': 107,
'seeing': 108,
'Macau': 109,
'rallied': 110,
'When': 111,
'Paya': 112,
'web-slinging': 113,
'Street': 114,
'Volver': 115,
'peregrine': 116,
'Davenport': 117,
'underestimated': 118,
'Qomi': 119,
'above-market': 120,
'wells': 121,
'Uwezo': 122,
'Deal': 123,
'reconnaissance': 124,
'stumps': 125,
'painting': 126,
'earlier': 127,
'graduated': 128,
'Wadia': 129,
'tighter': 130,
'acknowledged': 131,
'unaffected': 132,
'threatens': 133,
'Nasir': 134,
'CANTV': 135,
'demostrators': 136,
'61.3': 137,
'California-based': 138,
'Indebted': 139,
'disinfected': 140,
'2-2.5': 141,
'moans': 142,
'counterattack': 143,
'Turkey': 144,
'pricey': 145,
'inability': 146,
'defacate': 147,
'reform': 148,
'Muthmahien': 149,
'Ignacio': 150,
'Giordani': 151,
'torchbearer': 152,
'desk': 153,
'9.72': 154,
'Racism': 155,
'discriminate': 156,
'luge': 157,
'quails': 158,
'reunification': 159,
'engineered': 160,
'Pich': 161,
'Panggabean': 162,
'Czink': 163,
'role': 164,
'Sajida': 165,
'says': 166,
'Bartoli': 167,
'good-bye': 168,
'watches': 169,
'shootouts': 170,
'Radhika': 171,
'saddled': 172,
'Vitaly': 173,
'Rusafa': 174,
'Within': 175,
'amortization': 176,
'Mahdist': 177,
'Kenjic': 178,
'DNA': 179,
'Lausanne-based': 180,
'DOG': 181,
'Hong-ryon': 182,
'circulation': 183,
'opted': 184,
'positive': 185,
'Earl': 186,
'Mezni': 187,
'control': 188,
'highest-ever': 189,
'04-Feb': 190,
'landfill': 191,
'Catholics': 192,
'typhoid': 193,
'shrinks': 194,
'Lebedev': 195,
'Greenville': 196,
'First-half': 197,
'nearer': 198,
'al-Qaida-linked': 199,
'unmarried': 200,
'fighting': 201,
'295': 202,
'Ifugao': 203,
'canceling': 204,
'bless': 205,
'line-of-control': 206,
'Batna': 207,
'spiral': 208,
'lieutenant': 209,
'colonies': 210,
'expression': 211,
'delegate': 212,
'Mohamed': 213,
'socializing': 214,
'dolls': 215,
'Karami': 216,
'lease': 217,
'59.4': 218,
'basic': 219,
'Belarusian': 220,
'Abeto': 221,
'wounds': 222,
'Golding': 223,
'scrap': 224,
'validated': 225,
'27-Nov': 226,
'assert': 227,
'war-torn': 228,
'ridiculous': 229,
'helpful': 230,
'defused': 231,
'northern-based': 232,
'Us': 233,
'Mofaz': 234,
'unopposed': 235,
'bacteria': 236,
'Mac': 237,
'heartless': 238,
'environments': 239,
'anti-inflationary': 240,
'Chiefs': 241,
'Nambiar': 242,
'ceased': 243,
'Ant': 244,
'coldest': 245,
'MW': 246,
'Kupwara': 247,
'restarted': 248,
'McCullogh': 249,
'Roshan': 250,
'Sandinista': 251,
'queen': 252,
'leave': 253and more...Padding and train test split
ml = 50X= [[wi[w[0]] for w in s ] for s in s]
X = pad_sequences(maxlen=ml,sequences = X,padding ='post',value = num_words-1)y= [[ti[w[2]] for w in s ] for s in s]
y = pad_sequences(maxlen=ml,sequences = y,padding ='post',value = ti["O"])
y = [to_categorical(i,num_classes = num_tags) for i in y]
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.1,random_state=1)Build and Compile Bidirectional LSTM Model
input_word = Input(shape=(ml,))
m = Embedding(input_dim = num_words, output_dim = ml,input_length = ml)(input_word)
m= SpatialDropout1D(0.1)(m)
m = Bidirectional(LSTM(units=100, return_sequences = True, recurrent_dropout =0.1))(m)
out= TimeDistributed(Dense(num_tags,activation = 'softmax'))(m)
m = Model(input_word,out)
m.summary()Output —
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 50)] 0
_________________________________________________________________
embedding (Embedding) (None, 50, 50) 1758950
_________________________________________________________________
spatial_dropout1d (SpatialDr (None, 50, 50) 0
_________________________________________________________________
bidirectional (Bidirectional (None, 50, 200) 120800
_________________________________________________________________
time_distributed (TimeDistri (None, 50, 17) 3417
=================================================================
Total params: 1,883,167
Trainable params: 1,883,167
Non-trainable params: 0
_________________________________________________________________m.compile(optimizer='adam', loss ='categorical_crossentropy',metrics=['accuracy'])Train the Model
es= EarlyStopping(monitor='val_accuracy',patience=1,verbose=0,mode='max',restore_best_weights=False)
cb = [PlotLossesCallback(),es]h = m.fit(
x_train, np.array(y_train),
validation_split = 0.2,
batch_size=32,
epochs=3,
verbose = 1)
Output —
Train on 34530 samples, validate on 8633 samples
Epoch 1/3
34530/34530 [==============================] - 221s 6ms/sample - loss: 0.1891 - accuracy: 0.9568 - val_loss: 0.0686 - val_accuracy: 0.9802
Epoch 2/3
34530/34530 [==============================] - 210s 6ms/sample - loss: 0.0529 - accuracy: 0.9844 - val_loss: 0.0500 - val_accuracy: 0.9848
Epoch 3/3
34530/34530 [==============================] - 211s 6ms/sample - loss: 0.0384 - accuracy: 0.9884 - val_loss: 0.0470 - val_accuracy: 0.9856Evaluate
m.evaluate(x_test,np.array(y_test))Output —
4796/4796 [==============================] - 6s 1ms/sample - loss: 0.0493 - accuracy: 0.9854[0.04933204667780974, 0.98542535]Learnings —
How to build and train a bidirectional LSTM with Keras.
Day 45: Coming soon!
Follow and Stay tuned. Keep coding :)
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras
That’s it fellas. Peace out and keep coding :)
Stay Tuned and of-course let me end this post with a quote by Steve Jobs ;)
“Your work is going to fill a large part of your life, and the only way to be truly satisfied is to do what you believe is great work. And the only way to do great work is to love what you do. If you haven’t found it yet, keep looking. Don’t settle. As with all matters of the heart, you’ll know when you find it.”





