
Day 32: 60 days of Data Science and Machine Learning Series
Regression Project 2..
Welcome back peeps. Finally, holidays have kicked in and work has taken a back seat. I have ample time now so, I intend to complete this series in the last 12 days of 2021.
In this post we will cover multiple linear regression with a project. Along the lines we would be evaluating model fit and accuracy using numerical measures such as R² and RMSE.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
Linear Regression is used to model the relationship between two variables by fitting a linear equation to given data where one variable is explanatory variable and the other is a dependent variable. Multiple linear Regression uses many such explanatory variables to predict the outcome of a target variable i.e two or more independent variables and one dependent variable.

Data for this project can be accessed here :
Lets dive in!
Import necessary Libraries
import pandas as pd
import numpy as np
import seaborn as sns
from scipy.stats import skew
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use("ggplot")
plt.rcParams['figure.figsize'] = (15, 10)Load the Data
ad = pd.read_csv('Path to the file')ad.info()Output —
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 4 columns):
TV 200 non-null float64
radio 200 non-null float64
newspaper 200 non-null float64
sales 200 non-null float64
dtypes: float64(4)
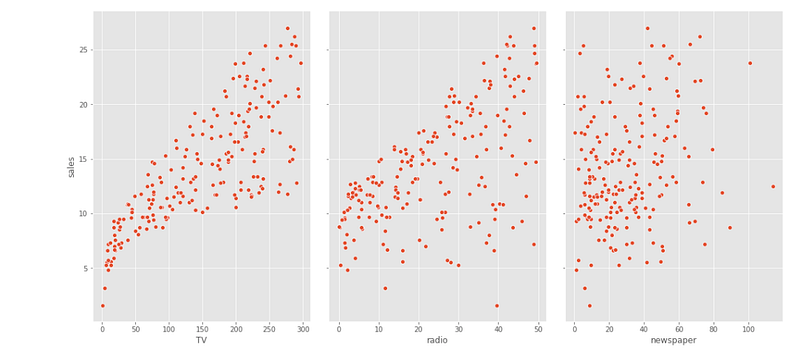
memory usage: 6.3 KBRelationships between Features and Target
sns.pairplot(ad,x_vars=['TV','radio','newspaper'],y_vars='sales',height=7,aspect=0.7)Output —
Multiple Linear Regression Model
from sklearn.linear_model import LinearRegressionX= ad[['TV','radio','newspaper']]
y=ad.salesl = LinearRegression()
l.fit(X,y)print(l.intercept_)
print(l.coef_)Output —
2.9388893694594085
[ 0.04576465 0.18853002 -0.00103749]list(zip(['TV','radio','newspaper'], l.coef_))Output —
[('TV', 0.0457646454553976),
('radio', 0.18853001691820453),
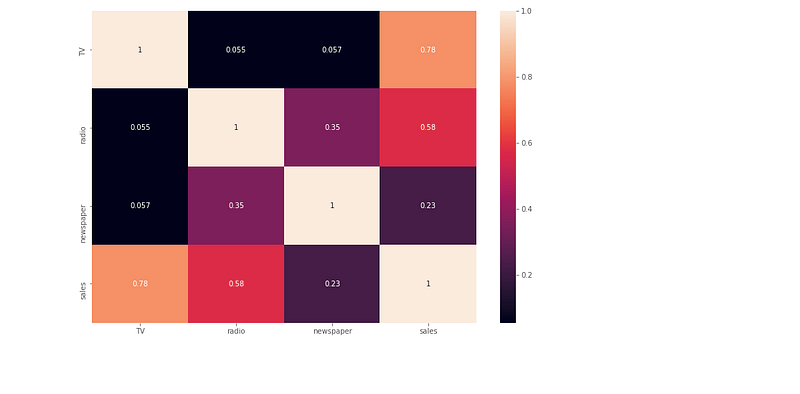
('newspaper', -0.00103749304247629)]Plot heatmap
sns.heatmap(ad.corr(),annot=True)Feature Selection
from sklearn.metrics import r2_scorel2=LinearRegression().fit(X[['TV','radio']],y)
l2_preds = l2.predict(X[['TV','radio']])
print('R^2 score',r2_score(y,l2_preds))Output —
R^2 score 0.8971942610828957l3=LinearRegression().fit(X[['TV','radio','newspaper']],y)
l3_preds = l3.predict(X[['TV','radio','newspaper']])
print('R^2 score',r2_score(y,l3_preds))Output —
R^2 score 0.8972106381789522Evaluation Using Train/Test Split & Model Metrics
Mean Absolute Error (MAE) is the mean of the absolute value of the errors
Mean Squared Error (MSE) is the mean of the squared errors
Root Mean Squared Error (RMSE) is the mean of the squared errors
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorX= ad[['TV','radio','newspaper']]
y= ad.salesX_train, X_test, y_train, y_test = train_test_split(X,y,random_state=1)
l4 =LinearRegression().fit(X_train,y_train)
l4_preds = l4.predict(X_test)print("RMSE",np.sqrt(mean_squared_error(y_test,l4_preds)))
print("R^2:", r2_score(y_test,l4_preds))Output —
RMSE 1.4046514230328953
R^2: 0.9156213613792232X= ad[['TV','radio']]
y= ad.salesX_train, X_test, y_train, y_test = train_test_split(X,y,random_state=1)
l5 =LinearRegression().fit(X_train,y_train)
l5_preds = l5.predict(X_test)print("RMSE",np.sqrt(mean_squared_error(y_test,l5_preds)))
print("R^2:", r2_score(y_test,l5_preds))Output —
RMSE 1.3879034699382888
R^2: 0.9176214942248908from yellowbrick.regressor import PredictionError,ResidualsPlotv = PredictionError(l5).fit(X_train,y_train)
v.score(X_test,y_test)
v.poof()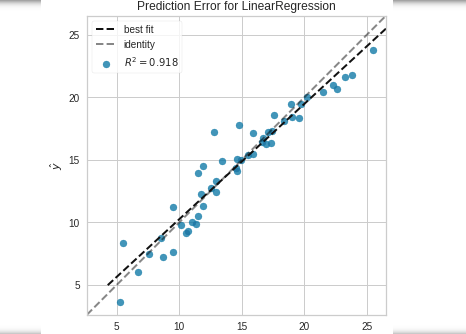
ML Regression Project 3: Coming soon
Follow and Stay tuned. Keep coding :)
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras
That’s it fellas. Peace out and keep coding :)
Stay Tuned and of-course let me end this post with a quote by Steve Jobs ;)
“Remembering that you are going to die is the best way I know to avoid the trap of thinking you have something to lose. You are already naked. There is no reason not to follow your heart.”





