
Cloud Architecture and KMS Keys
ACM.9 Key segregation to limit exposure in the event of a data breach
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Check out my series on Automating Cybersecurity Metrics. The Code.
🔒 Related Stories: AWS Security | Cloud Security Architecture | Encryption
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the last post we looked at how an attacker might gain access to your cloud environment using a web application. Specifically, I shared a lab in which an attacker could gain access to a WordPress site and create a C2 channel to send additional commands that the server woudl run in your environment.
Continuing on in this series we want to take steps to a.) prevent the initial attack and b.) reduce the blast radius (a term explained in my book at the bottom of this post). Using KMS keys can help limit access to what an attacker can access in your account — and specifically customer-managed KMS keys.
In order to protect the secrets and data involved in our data processing scenario for the batch jobs we’re going to create we will make use of AWS Key Management Service (KMS). Let’s think through how we might architect our use of KMS keys for this purpose.
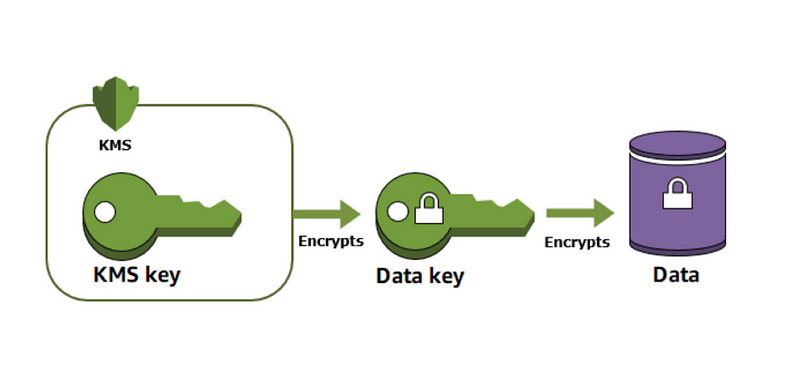
Default encryption on AWS is great, however I’ve written before about using encryption where anyone with AWS credentials in an AWS account to decrypt the data makes encryption somewhat useless. Encryption for compliance sake is not good enough. A proper and thoughtful encryption architecture will help you much more in the event of a data breach.
I’m interested in requiring MFA to kick off an AWS Batch job:
We’re going to use a container for our batch job.
We need to secure that container including any keys or data used by or processed by the batch jobs, plus any output.
One of the biggest risk in the cloud is credential abuse. I explained some ways attackers can abuse credentials applications in cloud environments in this last post. We need to take some steps to protect credentials I need to store somewhere due to the way that MFA works on AWS.
AWS IAM Roles and MFA
One of the things I’ve already done prior to writing these blog posts was to implement a docker container that requires MFA to run a process. It seems that in order to make that work we will need to use an AWS access key and secret key because MFA on AWS is related to users, not AWS IAM roles. I user with MFA will kick off the job to allow the batch to assume a role. From that point, the batch job can use the assumed role.
As I wrote about in this short blog post, we cannot require MFA in IAM policies for actions taken by assumed roles because the metadata does indicate (at least not at the time of this writing) that someone was using credentials with MFA to assume the role:
We can enforce the use of MFA to assume the role. Here’s where we run into some issues with protecting credentials.
When the batch job runs, it will need to pass credentials and a token into the batch job so it can assume a role that requires MFA. I don’t want users to have to store credentials in GitHub or pass credentials around to run batch jobs. That seems risky. I want to pull those credentials out of AWS Secrets Manager. I also want to protect those credentials in Secrets Manager by encrypting them with an AWS key.
I have some thoughts about how this will all work in the end but this is all a proof of concept to see if I can make it work. At this point, I know that I want to have a separate key for the credentials and the data. This is aligned with the concept of separating the control plane and the data plane when architecting and securing systems. The encryption key that protects the credentials that control the job will be separate from the encryption key that protects the data. I could create two separate keys named:
batch.credentials.key
data.keyIf I worked at a large organization, I could grant different people access to these separate keys. I could write much more on that topic but for now we’re just trying to separate concerns.
Data Before and After Transformation
What is my ultimate goal for this batch job? I’ve been writing about security metrics and reporting. I’m specifically interested in value-based security metrics. I’m going to show you how you can transform data from multiple sources into a report.
The batch jobs I write are going to pull data out of one S3 bucket, transform it, and then store it in another S3 bucket. Perhaps I’ll even have event-driven security batch jobs. The source data comes from different projects. Once each project is complete, the data can be archived.
The data needs to be decrypted each time it is read and encrypted each time it gets stored. As the data moves through a process I may provide access to decrypt the data only to some roles with some keys and encrypt the data only to some roles.
If the credentials of someone who has encrypt-only permissions are stolen, then whomever stole those credentials can’t read the data. They can only add new data and encrypted it. That’s still a concern but we’ve cut out a chunk of risk in this process. If a cloud identity has decrypt only permissions, they cannot tamper with the source data, only read it, because they would not be able to re-encrypt it and return it to the original location in the proper encrypted format. The source data remains pristine and unaffected by our transformation processes.
I might have different people working on projects generating data. They generate the data and are allowed to encrypt and store the source data. Then the batch jobs are allowed to decrypt the source data and re-encrypt it with a separate key. I could create two separate keys for source and transformation data so I’d having something like this:
batch.credentials.key
data.source.key (source generator: encrypt, transformation: decrypt)
data.transform.key (transformation: encrypt and decrypt)Separate Keys for Separate Projects
In addition, a person working on one project might not need to see the data associated with another project. Using the need-to-know or zero trust model, I can assign different encryption keys for each project. Using separate keys can help limit the blast radius in a data breach.
How Separate Keys Help Limit Blast Radius in a Data BreachThis concept of separate keys for different applications would have and did, to some extent, help limit the blast radius in the Capital One breach. I talked to some friends involved (who no longer work for the company) over dinner recently. One thing I always wondered why the attacker could access *all* the data in *all* the S3 buckets. I learned that, in fact, some of the S3 buckets used customer managed KMS keys with zero trust policies and those buckets were not accessible by the attacker. We will use that concept in our KMS design for our batch jobs processing reports for different purposes. I want to automate the creation of these keys, so I need a unique key name for each project. I can change the name of the source and transformation keys to include the project id.
batch.credentials.key
[projectid].data.source.key
[projectid].data.transform.keyProduction Data for Customers
Once the data gets transformed to a report for the customer, the report can be encrypted with a separate report key. This type of transformation ensures the people with access to the original source cannot access the final report. I could used various methods to encrypt the final project report with a key provided by the customer that only they and appropriate staff at 2nd Sight Lab can use to decrypt the data.
batch.credentials.key
[projectid].data.source.key
[projectid].data.transform.key
[projectid].data.report.keyEncrypted Secrets and Virtual Machines
We’ll want to encrypt any secrets used in this process and the data on virtual machines. In my case I have some manual processes that generate data. Proper penetration testing will never be fully automated. Users generating manual data work on VMS in the cloud and those VMS need to be encrypted.
I also generate a completely new environment for each project. Along with that users need some information about the environment that could be stored in secrets manager or AWS Systems Manager Parameter Store. In either case, we’ll want to protect those secrets with a key that the user can use to decrypt the data or start a virtual machine (EC2 instance).
If the users are working on a particular project, we could use the KMS keys we used above for S3, but then consider what the key policy would need to be in that case. We’d have to grant a lot more permissions as explained in this article that covers a common error when users don’t have access to a KMS key used to encrypt a VM

We could create a separate key for each user and that key is used on their own VMs and read their own secrets. Then no one else would be able to access or view the data on a particular VM except the people who are allowed to use that decryption key. That would include 2nd Sight Lab administrators and the person working on that particular project with a particular VM. If a person is working on multiple projects they could have one key for their VM or, what we do, is have people create separate VMs for each project. The keys would end up looking something like this:
batch.credentials.key
[projectid].data.source.key
[projectid].data.transform.key
[projectid].data.report.key
[projectid].[userid].keyBackups
I generally will wait a while after a project to ensure customers don’t have any questions. When I confirm with them that they are satisfied, I archive the data.
When the project is complete I no longer need the transformation data or the transformation key or the user-specific project keys. I can always re-run the transformation process if needed with the source data, so I can delete all the transformation-related resources to save some money. I can archive the VMs used on the project also and, if using automation, restore user access fairly easily if required.
I can back up the data with a separate key that is never used except in a break glass scenario if a customer needed access to an old report and something happened to my report data accessible to customers.
I can use a single backup key for easier management and to save money once a project is complete.
There are many more considerations related to backups to help defend against ransomware and create a resilient architecture, but for now let’s say that after the project is complete we should end up with the following keys:
credentials.key
[projectid].data.report.key
archive.data.keyThis may create some complications with encrypted AMIs. You will need to decrypt and re-encrypt the data onto EBS snapshots encrypted with your archive key and test your backups to make sure you can restore them properly. You can save money by storing your snapshots using the Amazon EBS Snapshots Archive storage class.
AWS Accounts for Segregation
One of the things I’ve been testing out lately is how I structure AWS accounts for segregation of duties. I put my KMS keys in a separate account. At one large bank I worked at we had a separate team that handled encryption. If your organization operates this way the people who provide encryption keys to others can do so in a separate account and provide cross account access to KMS keys to people who need them. That way there’s less chance that someone gets access to those KMS keys and can change the policies on them.
I did face one issue with KMS key cross-account logging that I’m still looking into and hope the AWS documentation is updated in regards to that before I get back to that it.
I also haven’t been able to get some aspects of organizational policies working with KMS keys. I tried to assign an organizational unit access to use a KMS key to start VMs encrypted with that key but wasn’t able to get that working on my first attempt. In the end, as explained above, I’ve decided to create user-specific keys anyway so it’s a moot point.
Automation
Of course, all of the above is a bit complicated. Manual processes are not going to be feasible. We’re going to need to think through how we automate the creation of all these keys and secure that creation process so it cannot be abused. I’ll be thinking through the automation of all of this in my next post.
Pricing Considerations
High-volume users will want to look at the cost of the KMS keys. You will need to determine how many keys you will need to support your use case and how many times you will need to encrypt and decrypt the data. The way I read the KMS pricing, the cost for KMS usage is discounted on aggregate usage, not per key but I haven’t tested that. You may want to do a POC or clarify that with AWS if you plan to make heavy use of this service. In other words, if you have 5 KMS keys and you make 5,000 requests with each key, will you pay .03 for each key because each is below the 10,000 limit, or are the requests aggregated so you’d pay .03 for the first 10,000 requests and .03 for the last 5,000 requests? This could matter if you have a huge amount of volume.
Limits:
High-Volume users will also need to be aware of AWS quotas (limits). I will not be hitting limits with my level of usage, but other organizations may need to quest limit increases or change their design to accommodate higher KMS usage levels. You don’t want to find out you are hitting a limit and cause a service outage so make sure you understand your requirements in advance if you think you might hit these limits.
Thinking ahead
I’m not sure if this is exactly how this project will end up but this is the thought process I go through when designing new systems. As always, plans can change as you make new discoveries during the development process. Let’s create some KMS keys next. Follow me for more in this series.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2022
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab



