
A Value-Based Approach to Cybersecurity Metrics
ACM.3 Are we security enough to avoid a data breach?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Check out my series on Automating Cybersecurity Metrics. The Code.
🔒 Related Stories: Cloud Architecture | Application Security | Cybersecurity
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the last post we considered one approach to cybersecurity metrics which involves statistics to try to predict whether or not you will have a data breach.
In this post I propose an alternate perspective. Just as there are different approaches to investing, different companies may take a different approach to cybersecurity metrics.
Often the number one question CEOs and boards want to know is whether the organization is secure enough to prevent a data breach. No one can predict that with certainty because no company has perfect security free from risk. It’s a lot like predicting prices of securities on the stock market. You can’t. It’s gambling any way you look at it. Something unexpected could always happen. Too many variables exist.
Learning from stock market investing strategies
As I write this section of my series of articles let me start by saying that this is not investing advice. However, I do have some experience with and knowledge about investing. I worked in the back office of Capital One Investing building systems that deal with investments and read a lot of books about the stock market over the past 25 years or so — to the point that I pretty much invested all my money in my house and avoided the market for a long time. I’m not recommending that either.
My issue with the market was that I found it too akin to gambling after all the things I have learned, and controlled by big firms who have a lot more access to make their trades happen when they want. I thought things were mostly over priced like the big tech stocks. When working for myself I did not have anyone matching my 401K or making those big trades on my behalf. If you do, you should max that out because it’s instantly doubling your money. I put my money into my house and sold it for a pretty sizable profit a little over a year ago. Of course I had to subtract all the time and money I put into it but overall, the price of the house almost doubled from the time I bought it to the time I sold it.
We can learn something from investors in terms of how they manage the risk of prices rising and falling in the stock market. The price of a stock in the market cannot be predicted with 100% accuracy, similar to the chance of a data breach. Investors use strategies to improve odds, limit losses, and increase profits. How do they do it? There are two primary strategies:
Growth Investing: Trying to pick stocks based on their future potential to outperform the market. Growth investing is basically trying to predict the future. You can look at a lot of indicators to make a better prediction, but it is still a prediction. We always hear about the winners, but there are also a lot of losers and a fair share of risk.
Value Investing: Investing in companies that are trading below what they are really worth. Investors look at company financial reports such as a balance sheet, profit and loss statement, and the detailed footnotes in financial reports to determine the value of a company. They will look for a low P/E (price to earnings) ratio and other factors to come up with a value and determine how much money they will make if the stock price rises to match that value. In addition, value-oriented stocks often pay dividends.
Growth Investing Versus Value Investing
As just mentioned, growth investing tries to predict future increases, while value investing tries to find good deals based on the value of a company.
Which method is better? It depends how you look at it as this article explains:
Over all time, value investing has produced better results. In the last 10 years, growth investing has out performed value investing. However, that may be changing as I write this. Take a look at these charts that show stock market trends and indicate the point in time when this article was published.
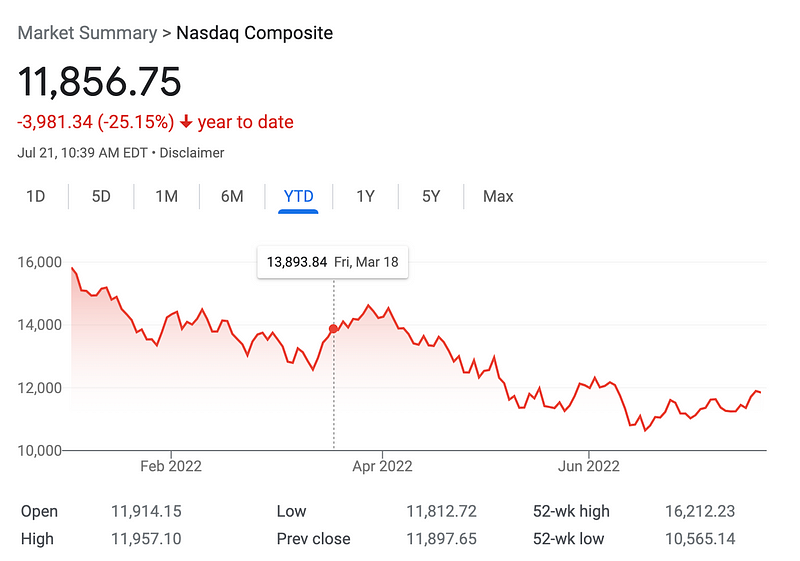
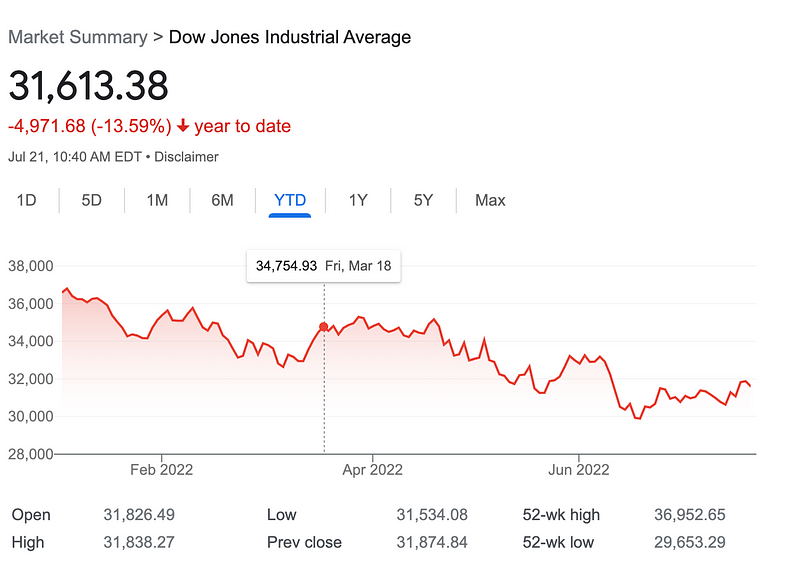
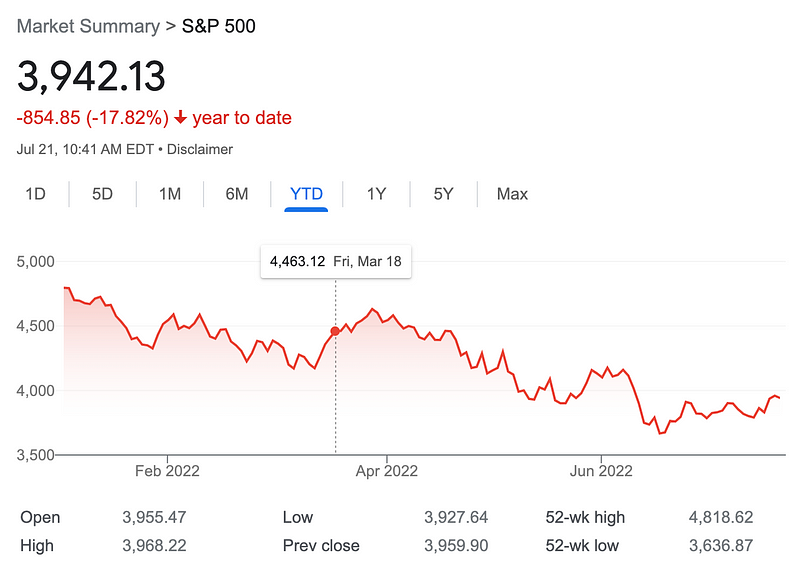
The stock market is falling. Many are predicting that due to inflation and the U.S. Federal Reserve raising interest rates that we are about to go into a recession. Signs already point to the effects of the increased rates in various sectors. Investors are worried about a recession. When that happens, people tend to try to find safer investments. Here’s an article that says investors are turning to value stocks to weather the stock market storm:
You can check out the chart in the above article to see the market shifting towards value-oriented stocks.
Not every growth stock in the past 10 years was a winner
Even if you chose to invest in growth stocks in the past ten years, did you choose the right growth stocks? Those who are investing in growth stocks and are successful at it are often still looking at company financials. The following article warns against picking stocks that are overvalued:
The concept of value still applies when selecting stocks that you think will grow. The ideal scenario would be to find an undervalued growth stock with solid business financials. Best of both worlds. Lower risk, greater upside.
I recently read about investors jumping in and buying any electric-vehicle-related stock they could find. Some of those companies were complete facades and others are currently struggling for different reasons. Here are a few examples:
If you invested and were not paying attention to the financials of these companies, you might be headed for some losses. Regardless of what method you use to invest, it’s generally a good idea to understand the financial health of the the companies in which you invest. The financial health is gleaned from the details in the financial reports.
Using quantitative models to help make investment decisions
There is one more type of investing to consider. The name may sound similar to the quantitative metrics we’ve been discussing in this thread of blog posts, but I’ll explain how it also could be different. I’m a fan of quantitative methods to analyze metrics and numbers but prefer to take a value-investing approach to versus a predictive statistical approach. Hold that thought.
Quantitative Investing or Quantitative Analysis (QA) in finance leverages mathematical and statistical analysis to help determine the value of a financial asset, such as a stock or option.
In the above definition there are different types of quantitative metrics that could be applicable. The book I reviewed seemed to imply that the only quantitative methods you could use where the predictive quantitative methods they described, but a quantitative method could be anything that leverages numbers to measure and evaluate something as compared to words (a qualitative approach).
Quantitative analysis has been around longer than computers — over 80 years. Quantitative methods use mathematical models to make decisions. You could use methods I wrote about previously like Monte Carlo simulations and the Bayes theorem, or you could look at financial metrics the way Warren Buffet does. Both are quantitative.
How successful is trading based on quantitative methods? That article sums it up nicely:
Choosing the right data is by no means a guarantee, just as trading patterns that appear to suggest certain outcomes may work perfectly until they don’t. Even when a pattern appears to work, validating the patterns can be a challenge. As every investor knows, there are no sure bets.
Humans are emotional. They will often be swayed by market swings to make the wrong investment choices. Taking humans out of the equation can and letting a computer algorithm make the trades removes the emotion and provides more consistent trading. It also can speed up trade execution. This is known as “high-frequency trading.” This method of trading can also lead to big problems when algorithms go haywire. Quoting from the article below about a trading algorithm used by a company called Knight Capital:
We don’t know exactly what. They switched it on and immediately they started losing literally $10 million [£6.4m] a minute. It looks like they were buying high and selling low many, many times per second, and losing 10 or 15 dollars each time. And this went on for 45 minutes. At the end of it all they wound up having lost $440 million [£281m].
As the article goes on to explain, some nefarious individuals or groups try to figure out what trading algorithms investment firms use. Then they try to manipulate financial data and offers to trick these algorithms into making the trades they want.
Quantitative methods can to miss what Nassim Nicolas Taleb calls a “black swan” in his book: The Black Swan:
A “black swan” is an event that your risk predicting algorithms might suggest is highly unlikely. In other words, the odds of this event occurring seem to be miniscule. And yet, it happens. And when it does, it results in huge losses. Two examples that quantitative methods missed according to the aforementioned article:
- The 2008 crash where they failed to account for mortgage-backed securities.
- Taleb tells a story about a trader basing his currency trades on statistical probabilities and he went from a high-flying trader with loads of money to broke in a short period of time when his favorite algorithm failed him.
That latter story was in Taleb’s second book, Fooled by Randomness, which I actually read first and possibly like better than the first at the time I read them.
The book I reviewed and wrote about about in my last post on using statistical methods for cybersecurity metrics suggests that arguments about black swans are irrelevant. Here are the prior posts if you missed them:
The authors of the book brush off the black swan concept stating that even those things considered black swans could have been predicted with a proper quantitative methods. They mention the 2008 crash as one example of something that could have been predicted. Ironically, the article above points out that quantitative investing missed that crash entirely. If you believe that article, it refutes the argument made in the book that the event was predictable with quantitative methods.
Of course, if everyone had perfect models it would have been predictable, but as one person put it my last post, “the models are never perfect.” These examples point to the validity of a quote from my last post that suggested people should be more concerned with failures than successes. That is especially true in cybersecurity where it is the failure — a data breach — results in substantial cost for organizations based on the average cost of a data breach. Can you afford to be wrong? Do you want to be? That is up to your CEO and board to decide.
Someone did, in fact, predict the 2008 crash — Michael Burry — but he didn’t do it by calculating probabilities. He discovered the problem by pouring over the details of financial data. He noticed a problem with the data in the mortgage industry. You can read the story about those who did predict this crash and who argued against the possibility here:
The dot-bomb crash in 2000 was also predictable, but it did not take quantitive predictive statistical methods to do it. I had recently read Warren Buffet’s book on value investing at the time and it was obvious to me that the money pouring into startups was more than they could ever repay based on their business models. I was offered jobs at many of those companies in Seattle and opted not to take a job with any of them. I didn’t buy think most of their business models would work, while at the same time, venture capital was pouring millions or billions into all of them. My CPA told me later I was the first one to tell him it was a house of cards and all going to crash.
Sometimes you just need a little common business sense, not a fancy algorithm.
What does Taleb think of Bayesian analysis? I can’t speak to the legitimacy of this post but it sounds about right, and I agree with the last line:
He is a Bayesian in epistemological terms, he agrees Bayesian thinking is how we learn what we know. However he is an empiricist (and a skeptical one) meaning he does not believe Bayesian priors come from any source other than experience. For example, suppose a Bayesian says he thinks earthquake size and frequency obey a power law with some prior, and uses historical data to compute the probability of a magnitude 8.0 or larger earthquake in California over the next decade. Nassim would criticize the analysis because the prior essentially determines the answer.
Aside from philosophic subtleties, where he differs from many practicing Bayesians is in his preference for robust conclusions based on broad observation over specific models. When people construct priors to analyze specific data sets looking for specific types of conclusions, Nassim would say, they often miss the point. Simpler and more general methods can be more reliable, and formal analysis can give a false precision to answers.
You can read some of Taleb’s thoughts on his twitter account. Here’s one example:
And apparently there’s more in his book published March 2020. I haven’t read it but I’m guessing so because it’s got the tag “bayesian-schmayesian” on his blog. On Amazon:
When it comes to predicting what will happen in the stock market using AI (an idea which has been around since the 1940s), the following article covers some of the challenges:
While artificial intelligence has dramatically improved chess programs, the investment markets behave differently than a board game that has fixed rules and no element of chance. As with ordinary, human-inspired intelligence, the artificial version thereof may require special information to succeed. Great thoughts alone may not suffice.
I would suggest that cybersecurity falls into that same category and will face similar challenges. It will be difficult to use an algorithm to determine what an attacker will do next. In fact, the attackers will try to hack your prediction engines. If a hacker breaches your systems and knows what algorithm you are using — that might actually help them to craft an attack you will miss. Consider the effects of an attack called data poisoning:
Leveraging a value-based approach to cybersecurity metrics
Back to the title of this post: A Value-Based Approach to Cybersecurity Metrics. What do I mean by that? Instead of trying to predict the future or bet the odds, what if we could look at a company’s cybersecurity fundamentals and determine their value based on some metrics? What if we could use those metrics to improve the value of the company and it’s ability to withstand a cyber-attack?
How do we do that? We need to be able to measure the state of security controls at the company using security reports — akin to financial reports as I describe in my book. These security reports I have in mind can give us empirical data on which to base a cybersecurity risk assessment. This data demonstrates how many chances a company is giving attackers to break in. It also shows the potential damage, should an attack occur, based on the ability to travers internal systems or access data on private networks.
I wrote about all those concepts in my book, Cybersecurity for Executives in the Age of Cloud, also shown at the bottom of this post if you are unfamiliar with any of those terms or don’t know what I mean.
Companies could construct reports based on cybersecurity metrics that demonstrate the security health of a company. These reports would not be based on human analysis or prone to human judgement or statistical models. They are just metrics. They are the kind of quantitative metrics that measure the things that could facilitate a data breach or increase the resulting impact due to the length of time it takes to discover the breach or the ability to accurately define the scope of affected records. Those things can all be measured objectively.
If a company has more findings over time, the risk is increasing. If the company has less findings over time, the risk is decreasing. That is a bit simplified but it is a general starting point. We need to find a common way to measure cybersecurity metrics the way the financial industry has established a means to measure the financial health of a company. That allows us to make value judgments such as whether or not to give a company a cyber insurance policy or what you should charge for it. It may help you determine if you want to do business with that company. These value judgements are based on security fundamentals.
Security fundamentals
What are security fundamentals? They are the characteristics that define the state of security at an organization. Much like a balance sheet you can create reports that quantify the state of your security.
Don’t we already have things like that? We have PCI compliance and SOC2 and ISO 27001 the CIS top security controls. As I explain in my book those frameworks and assessments are useful and you could use them if that’s all you have — but they aren’t always directly correlated with what causes data breaches or increases the scope. They also sometimes involve a lot of paperwork and manual processes and lack sufficient metrics.
I tried to stick to metrics in my book that quantify what causes, prevents, and reduces the scope of data breaches. Most of the metrics in my book come down to security configurations and processes that allow attackers to breach an organization or disallow them from accessing sensitive systems and data. I also want to try to automate gathering, reporting on, and analyzing those metrics — with quantitative methods but not the type that try to predict a breach. Rather, they calculate risk based on the quantity of findings and ideally, incorporate data on the cause of breaches in the industry. We don’t have enough specific data on the latter as I started explaining here:
Gathering the data (metrics)
People keep looking for a simpler answer. How can we possibly know and track all of our security configurations? But at the end of the day, your configurations and processes are what let an attacker breach systems or not. The book I mentioned earlier glosses over the concept of configuration metrics with the example of an organization that has a firewall but hasn’t configured any firewall rules. I propose that we can do better at measuring the state of cyber security at an organization.
I wrote a related blog post about how you treat the data within your organization and hope to provide more concrete methods for doing what I am proposing in this latest series of blog posts (if I have time.)
Configurations and processes are measurable and can be evaluated. Once we know what risky configurations and processes exist within an organization we can decide what to do about it based on the potential for a risky configuration to lead to a data breach, similar to a door without a lock or a house without an alarm.
After you’ve collected the data, you could use statistical methods like those proposed in the book I reviewed on how to measure anything in cybersecurity, or you could simply consider the cost of the worst-case scenario along with your budget and resources that could be applied to remediating the problem. I pondered those options in the last post on leveraging statistical methods in cybersecurity.
If you track misconfigurations in a holistic way you can generate reports that tell you whether your risky configurations are increasing or decreasing, regardless of the probability of a data breach. Clearly, an increase in configurations which provide an opening for attackers increases your risk that they will do so.
Given the potential cost of a data breach and the challenges associated with predictive models, perhaps instead of trying to beat the odds, companies can focusing on risk reduction by improving security-related configurations — and thereby improving the security fundamentals that make up their cybersecurity balance sheets:
Assets - Liabilities = Owners EquityFollow for updates.
Teri Radichel | © 2nd Sight Lab 2022
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab





