
Democratization of 3D content creation | Code
3D Diffusion Models
AI system that creates 3D renderings from a single input image

The traditional 2D to 3D approaches produce unwanted artifacts and are prone to blurriness. A novel method may provide roughly 3D consistent views with exceptionally sharp sample quality.
Generate realistic 3D models from text
Can you convert a 2D image to 3D?
3DiM, pronounced “three dim,” is a diffusion model for creating a new 3D view from as few as one image. The core of 3DiM is an image-to-image diffusion model. 3DiM takes a single reference view and a relative pose as input and uses diffusion to create a new view. After our new stochastic conditioning sampler, 3DiM can then make a whole 3D scene that is consistent.
The scene’s output frames are made in a way called “autoregression.” At each step of the denoising process, the method chooses a random conditioning frame from the set of frames that came before. This is part of the reverse diffusion process. Stochastic conditioning gives much more consistent 3D results than the naive sampling process, which only looks at a single frame before making a decision.
3DiMs don’t need hyper-networks or test-time optimization to create new views, and a single model can be easily scaled to a large number of scenes.
Highlights of 3DiM research
🟠 The authors show how diffusion models work to create new points of view.
🟠 Stochastic conditioning is a new way to get close to 3D consistency using a sampler.
🟠 X-UNet — changed the usual image-to-image UNet to use weight-sharing and cross-attention to get better results.
🔵 3D consistency scoring is a new way to measure how consistent 3D models without geometry are.
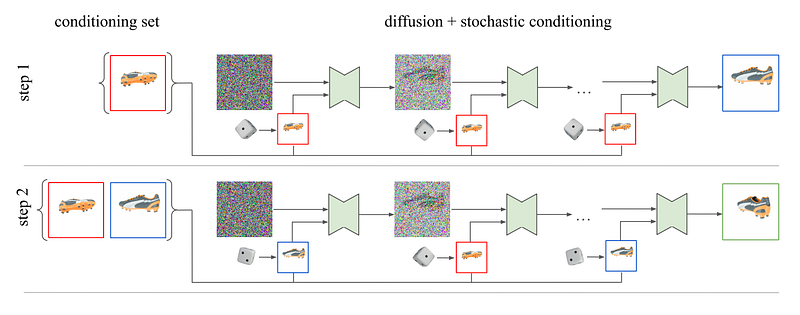
Sampler for stochastic conditioning The sampling method is made up of two main parts: 1) The autoregressive process of making more than one frame, 2) The process of removing noise from each frame. At each step of denoising, it chooses a previous frame at random as the conditioning frame when making a new frame. Therefore, the method doesn’t show the pose inputs in the diagram so as not to make it too busy. However, they are recalculated at each step based on chosen random conditioning view.
State-of-the-art comparisons

These images show the input and output of a 3DiM trained on the SRN vehicles dataset at 128x128, and they compare well to other geometry-aware algorithms.
The prospect of using 3DiM, which can model whole datasets with a single model, to the biggest 3D datasets from the real world excites me the most. Even though additional work is needed to handle noisy postures, variable focus lengths, and other issues posed by such datasets.
Further simplifying the widespread use of these models might be achieved by solving the research challenge of developing an end-to-end strategy for the high-quality generation that is 3D consistent by design.
Project Page (scroll down)
I invite you to explore the concept of Machine Learning by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, wombo dream, digital art, Dalle 2, Imagen, wombo ai, Parti, 3D point cloud, diffusion models, generative art, wombo art, photographic quality, img by AI system, AI art generator, text to art generator, 3D, midjourney, dalle2, stablediffusion, 3D pose,

Project Page:
https://3d-diffusion.github.io/static/paper.pdf
Title: Novel View Synthesis with Diffusion Models
Authored by Daniel Watson, William Chan, Ricardo Martin-Brualla, Jonathan Ho, Andrea Tagliasacchi, and Mohammad Norouzi