
Machine Learning Art
How to make 3D models from a single image
New AI method to generate AR/VR scenes [update Aug 2023]

From a single image, a 3D object generation is possible. In recent years, the term “inverse graphics” has gotten a lot of press. Several efforts seek to reconstruct the form, or the shape and appearance, of a single item per image, whilst others aim to extract numerous objects per image or to produce a holistic representation of an entire scene.
- August 2023 — AI art tools update can be found ➡️ HERE ⬅️
All of these methods employ differentiable rendering to calculate a reconstruction cost when comparing the predicted 3D model to the 2D picture, albeit the format used to encode the 3D model differs. 3D meshes, signed distance functions, depth, and implicit models are all popular options. The authors use the New Method, often known as implicit models, in this study.
Project Page / Github (scroll down)
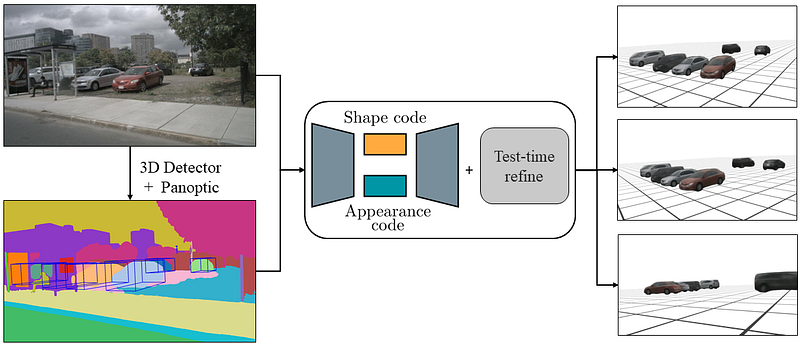
AutoRF is a novel method for learning neural 3D object representations in which each item in the training set is seen from only one perspective.
This is in sharp contrast to the vast majority of previous efforts, which use multiple views of the same object, use explicit priors during training, and need pixel-perfect annotations. Instead, the authors suggest learning a normalized, object-centric representation whose embedding characterizes and disentangles form, appearance, and position to solve this problematic situation.
text-to-3D new OpenAI generative 3D modeling Shap·E . DEMO
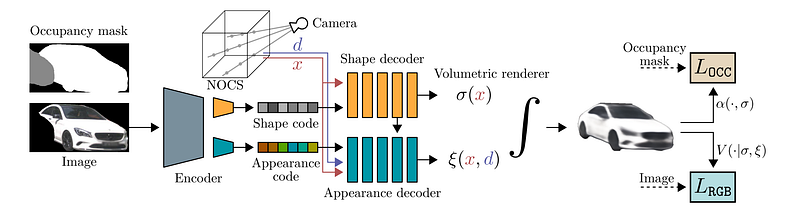
Each encoding gives generalizable, concise information about the item of interest, which is decoded into a new target view in a single shot, allowing for innovative view synthesis. By improving form and appearance codes at test time and fitting the representation precisely to the input image, the authors increase the reconstruction quality even further.
They demonstrate that the novel technique generalizes effectively to unseen items in a number of studies, using nuScenes, KITTI, and Mapillary Metropolis datasets of complex real-world street scenes.
🔵 Editing an AR / VR scene
AutoRF detangles object shape, appearance, and position in a natural way. This enables for independent control of each property while moving the camera freely, resulting in the first ever inherently reverse-parked automobile.
🔵 Datasets that have never been seen before
AutoRF can synthesise appropriate picture representations even on unseen datasets with vastly diverse camera attributes, light conditions, and scene compositions.
Conclusion
The authors suggested a new method for learning neural 3d shape representations that, unlike most previous work, relies only on single views of real — world objects during training, rather than using additional 3d model shape priors like CAD models or relying on curated datasets. The novel technique uses machine-generated labels, such as 3D object identification and panoptic segmentation, to develop a standardized object-centric representation that is posture invariant and factorizes into a geometry and an appearance component. These two components are combined to form an object’s implicit radiance field representation, which may subsequently be displayed into new target views. They show that new method generalizes effectively to unseen items, even across a variety of real-world datasets of street scenes.
DATAsculpting
Machine Learning in Art on the example of myFATHERintheCloud.ai
towardsdatascience.com
AR/VR applications
New Method aids in furthering research into the possibility of using real-world, large-scale data to create building representations for future AR/VR applications. However, concerning the limits, similar to comparable research from neural representation learning, this method necessitates large computing expenditures to produce models of unique viewpoints.
@inproceedings{mueller2022autorf,
author = {M{\"{u}}ller, Norman and Simonelli, Andrea and Porzi, Lorenzo and Bulò, Samuel Rota and Nie{\ss}ner, Matthias and Kontschieder, Peter}},
title = {AutoRF: Learning 3D Object Radiance Fields from Single View Observations},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022}}
Project Page:
https://sirwyver.github.io/AutoRF/static/AutoRF.pdf
Github:
coming soon
Keywords: 3D, computer vision, Artificial Intelligence, Graphics, Machine Learning, AI art, art, digital art, AutoRF, AR, VR, inverse graphics, Pattern Recognition, have i been trained?
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai




