
What is Embedding in AI? Explained in Everyday Language for Beginners
Updates: AI for Absolute Beginners is an ongoing series that now covers:
Last time, we talked about RAG (What is RAG in AI? Explained in Everyday Language for AI Beginners), a critical component in AI chatbots that retrieves external knowledge and integrates it into responses. This time, let’s explore another crucial concept in Large Language Models (LLM): “embedding.”
The term “embedding” originates from math and topology. You don’t need to grasp the full mathematical definition, and I’m probably not an expert in these areas. However, in a basic sense, similar to ‘implanting something into something else’ in the physical world, embedding in math refers to mapping ‘something’ into a mathematical structure.
In natural language processing (NLP) and Large Language Models, embedding involves using a mathematical structure to represent words or data, such as images.
Sounds familiar? But Embedding is different.
Many might be familiar with Morse code. To some extent, if you consider dots as 0s and lines as 1s, Morse code can be seen as a mathematical form of representing letters — for example, if A is ‘01’ and B is ‘1000’, then ‘BAD’ translates to ‘1000–01–100’.

This is a traditional way of representing things in numbers. However, this isn’t the same kind of ‘embedding’ we’re discussing in AI, because this method doesn’t reflect the meaning of words. There’s no way to tell from their mathematical representations that the words ‘BAD’ and ‘WORSE’ are more closely related in meaning than ‘BAD’ and ‘BED’. In Morse code, BAD and BED are definitely more related as they have more letters overlapping.
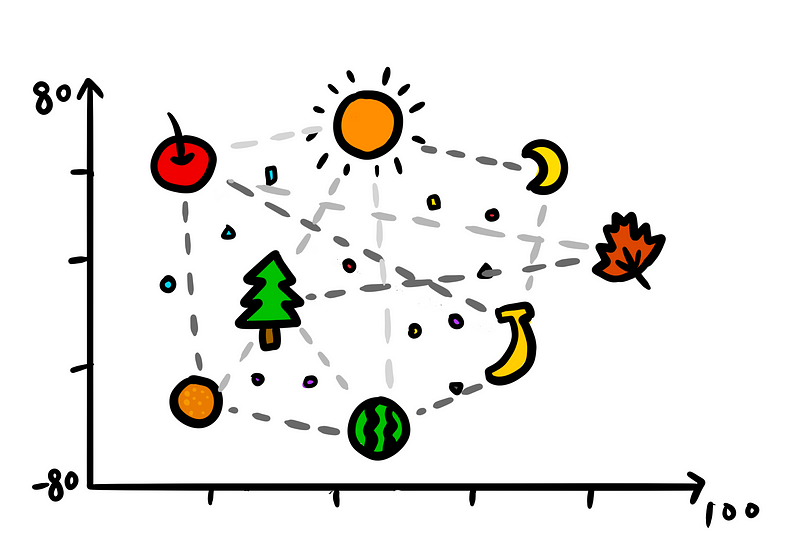
Now imagine you have a word like “cat.” In an embedding, “cat” might be represented by a list of numbers like [0.2, -0.4, 0.7]. These numbers are learned from data and they capture information about the word. So similar words, like “cat” and “kitten,” will have lists of numbers that are also similar. Such representation helps AI understand that these words are related in meaning.
This process is not just for words; it can be for other types of data too, like images or user behavior on a website.
So what is embedding like?
Think of word embedding in NLP or LLM like a school yearbook. In a yearbook, students are grouped by their interests or activities, like sports teams, music bands, or science clubs. Each group tells you something about the students in it — for instance, students on the basketball team are probably interested in sports.
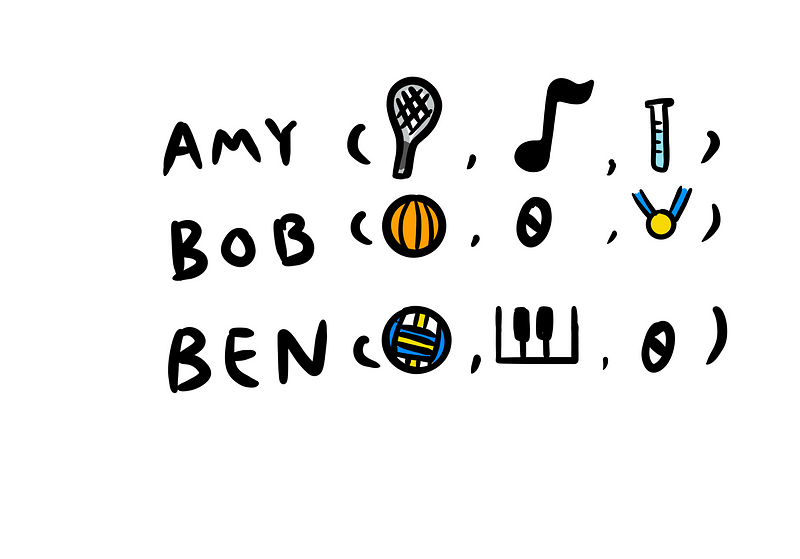
In word embedding, words are like students, and the groups are like lists of numbers. Each word is assigned to a ‘group’ (a unique list of numbers) based on its ‘interests’ (meaning and use in language). For example, words like ‘cat’, ‘dog’, and ‘pet’ might be grouped similarly because they share similar meanings and are often used in similar contexts.
Just like how you can understand a student’s interests by seeing what groups they’re in, an AI can understand a word’s meaning by looking at its number list. This helps the AI to see relationships between words and understand language better.
So, word embedding is like a yearbook for words, where their ‘group photos’ (number lists) help AI to understand what they ‘like’ (their meanings) and how they relate to each other.
Then, how does embedding work? Manual? Magic?
Embedding in AI, especially in the context of NLP and LLMs, functions more like a ‘black box’ than something dependent on manual labeling.
Imagine placing random people in a large room. Leave them there in the morning, close the door, and return in the afternoon. You’ll likely find them naturally grouped by commonalities such as origin, interests, gender, or the language they speak. This scenario is akin to how ‘black box’ embedding works.
But, here’s a more serious explanation:
- Automatic Learning: Embeddings are typically generated through automated processes, where the AI learns from large amounts of data. It analyzes how words are used in different contexts and then represents these words as vectors (lists of numbers). This learning process does not generally require manual labeling of the words. The AI algorithm, such as a neural network, figures out the best representation on its own based on the patterns it observes in the data.
- No Manual Intervention Needed: Unlike some other machine learning tasks, creating embeddings does not require humans to label the data beforehand. The embeddings are learned from the context in which words appear within the training material, usually a vast corpus of text.
- Complex and Opaque Process: The process by which these embeddings are created and how exactly they represent the meanings and relationships of words can be quite complex and not easily interpretable by humans. The internal workings of these models (why a particular word has a specific vector representation) are often not transparent, hence the ‘black box’ nature.
- Contextual Understanding: Modern embedding techniques, especially in context-aware models like BERT or GPT, are sophisticated enough to capture nuances, synonyms, and different meanings based on context without any manual input.
In summary, embeddings in AI are largely automated and do not rely on manual labeling. They are a product of AI learning from large datasets, and the specifics of how they represent and understand language can be opaque, contributing to their ‘black box’ characterization.




