
Two minutes NLP — Visualizing Seq2seq Models with Attention
Seq2seq, RNN, encoder-decoder, and Attention
A sequence-to-sequence model (also known as seq2seq) is a deep learning model that takes as input a sequence of items, such as words, and outputs another sequence of items. Sequence-to-sequence models achieved a lot of success in tasks like machine translation, text summarization, and image captioning.
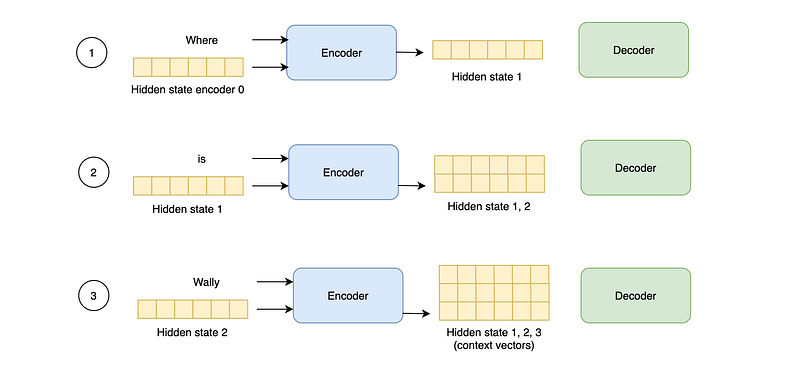
Under the hood, these models are composed of an encoder and a decoder, which usually are both recurrent neural networks (RNN).
The encoder processes each item in the input sequence and encloses the information it captures into a vector, called context vector. After processing the entire input, the encoder sends the context vector over to the decoder, which begins producing the output sequence item by item.
Seq2seq models without Attention
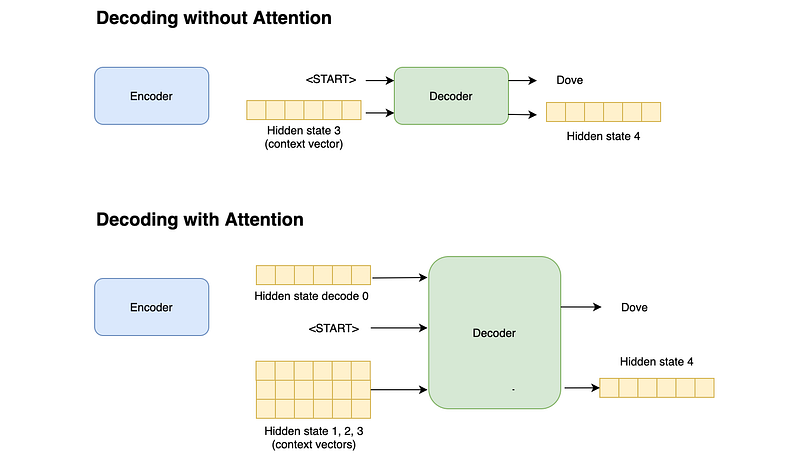
Consider a seq2seq model that translates the sentence “Where is Wally” to its Italian counterpart “Dove è Wally”.

An RNN takes two inputs at each time step: an item (such as one word from the input sentence), and a hidden state. The output is a new hidden state.

This is how the encoder processes the whole input sequence and produces the final context vector.

Similar to the encoder, the decoder accepts a word as input and a hidden state. The context vector produced by the encoder is used as the initial hidden state of the decoder. To start producing output, we pass a <START> token to the decoder as the first input word.

The decoder then updates its hidden state and produces the first output word, which will be used as the next input word for the decoder. The process of decoding stops when the decoder outputs the <END> token.
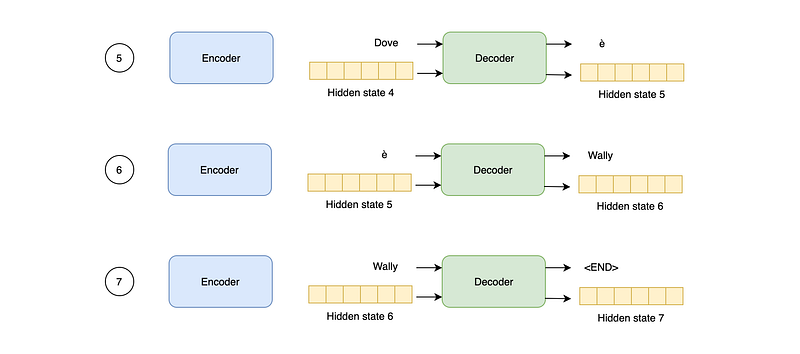
If the context vector represents a good summary of the entire input sequence, then the decoder should be able to produce a good-quality output accordingly.
However, empirical experience shows that a fixed-length context vector is not able to remember long input sequences, as it tends to forget the earlier parts of the sequence. The attention mechanism was born to resolve this problem.
Seq2seq models with Attention
A solution was proposed in the papers “Neural Machine Translation by Jointly Learning to Align and Translate” and “Effective Approaches to Attention-based Neural Machine Translation”. These papers introduced and refined a technique called “Attention”, which allows the model to focus on the relevant parts of the input sequence as needed.
An attention model has two main differences from classical seq2seq models. First, the encoder passes all the hidden states to the decoder, instead of passing only the last hidden state.
Second, the decoder accepts both an initial hidden state and all the hidden states produced by the encoder. All this information is then used to produce an output word and a new hidden state.
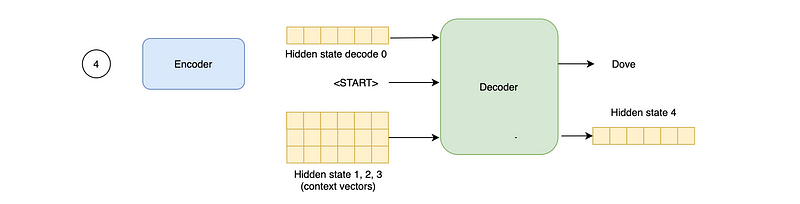
At the next step, the decoder utilizes the hidden state and the word produced by the decoder at the previous step, along with all the hidden states produced by the encoder.
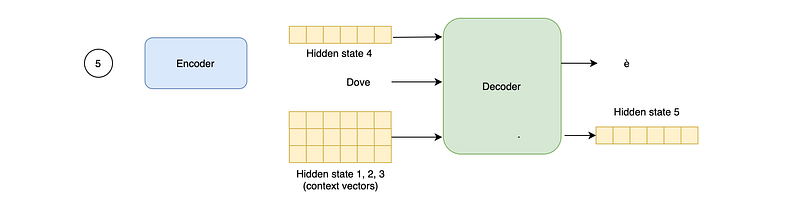
But how does the decoder use the context vectors, as their amount depends on the length of the input sequence?
It does so through a mechanism called attention.
Attention produces a single fixed-size context vector from all the encoder context vectors (often with a weighted sum). The weight of each context depends on the input word that the decoder is accepting at the moment, and represents the “attention” that must be given to that context when processing such input word.
Typically, the resulting vector is then concatenated with the hidden state produced by the decoder RNN, which passes through a feed-forward neural network to produce the output word.
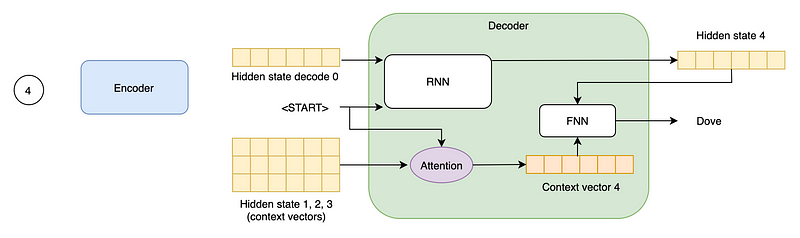
The way in which the weights of each context vector are produced and the final context vector is made depends on the specific type of attention used.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts




