
Two minutes NLP — 11 word embeddings models you should know
TF-IDF, Word2Vec, GloVe, FastText, ELMO, CoVe, BERT, RoBERTa, etc.
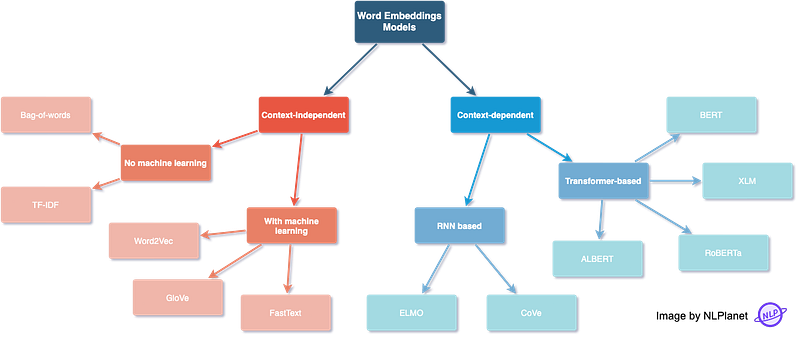
The role of word embeddings in deep models is important for providing input features to downstream tasks like sequence labeling and text classification. Several word embedding methods have been proposed in the past decade.
Context-independent
The learned representations are characterised by being unique and distinct for each word without considering the word’s context.
Context-independent without machine learning
- Bag-of-words: a text, such as a sentence or a document, is represented as the bag of its words, disregarding grammar and even word order but keeping multiplicity.
- TF-IDF: gets this importance score by getting the term’s frequency (TF) and multiplying it by the term inverse document frequency (IDF).
Context-independent with machine learning
- Word2Vec: shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words. Word2vec can utilize either of two model architectures: continuous bag-of-words (CBOW) or continuous skip-gram. In the CBOW architecture, the model predicts the current word from a window of surrounding context words. In the continuous skip-gram architecture, the model uses the current word to predict the surrounding window of context words.
- GloVe (Global Vectors for Word Representation): Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
- FastText: unlike GloVe, it embeds words by treating each word as being composed of character n-grams instead of a word whole. This feature enables it not only to learn rare words but also out-of-vocabulary words.
Context-dependent
Unlike context-independent word embeddings, context-dependent methods learn different embeddings for the same word based on its context.
Context-dependent and RNN based
- ELMO (Embeddings from Language Model): learns contextualized word representations based on a neural language model with a character-based encoding layer and two BiLSTM layers.
- CoVe (Contextualized Word Vectors): uses a deep LSTM encoder from an attentional sequence-to-sequence model trained for machine translation to contextualize word vectors.
Context-dependent and transformer-based
- BERT (Bidirectional Encoder Representations from Transformers): transformer-based language representation model trained on a large cross-domain corpus. Applies a masked language model to predict words that are randomly masked in a sequence, and this is followed by a next-sentence-prediction task for learning the associations between sentences.
- XLM (Cross-lingual Language Model): it’s a transformer pretrained using next token prediction, a BERT-like masked language modeling objective, and a translation objective.
- RoBERTa (Robustly Optimized BERT Pretraining Approach): it builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with much larger mini-batches and learning rates.
- ALBERT (A Lite BERT for Self-supervised Learning of Language Representations): it presents parameter-reduction techniques to lower memory consumption and increase the training speed of BERT.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts




