
Two minutes NLP — Doc2Vec in a nutshell
CBOW and Skip-gram Word2Vec, DM and DBOW Doc2Vec

Doc2Vec is an unsupervised algorithm that learns embeddings from variable-length pieces of texts, such as sentences, paragraphs, and documents. It’s originally presented in the paper Distributed Representations of Sentences and Documents.
Let’s review Word2Vec first, as it provides the inspiration for the Doc2Vec algorithm.
Word2Vec
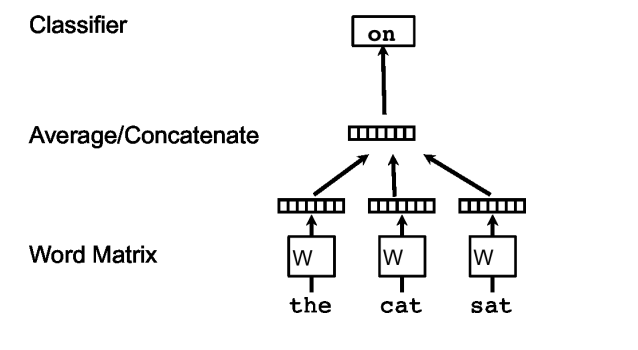
Word2Vec learns word vectors by predicting a word in a sentence using the other words in the context. In this framework, every word is mapped to a unique vector, represented by a column in a matrix W. The concatenation or sum of the vectors is then used as features for the prediction of the next word in a sentence.
The word vectors are trained using stochastic gradient descent. After the training converges, words with similar meanings are mapped to a similar position in the vector space.
The presented architecture is called Continuous Bag-of-Word (CBOW) Word2Vec. There is also a second architecture called Skip-gram Word2Vec, where word vectors are learned by predicting the context from a single word.
Doc2Vec
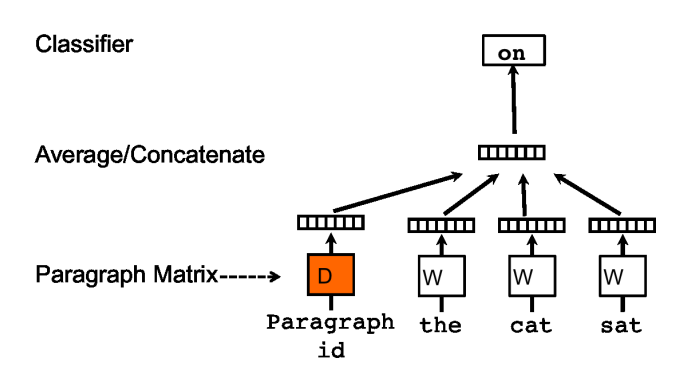
We’ll see now how to learn embeddings of paragraphs but the same approach can be used to learn embeddings of entire documents as well.
In Doc2Vec, every paragraph in the training set is mapped to a unique vector, represented by a column in matrix D, and every word is also mapped to a unique vector, represented by a column in matrix W. The paragraph vector and word vectors are averaged or concatenated to predict the next word in a context.
The paragraph vector is shared across all contexts generated from the same paragraph but not across paragraphs. The word vector matrix W, however, is shared across paragraphs.
The paragraph token can be thought of as another word. It acts as a memory that remembers what is missing from the current context. For this reason, this model is called Distributed Memory (DM) Doc2Vec. There is also a second architecture called Distributed Bag-of-Words (DBOW) Doc2Vec, which is inspired by Skip-gram Word2Vec.
The paragraph vectors and word vectors are trained using stochastic gradient descent.
At prediction time, one needs to obtain the paragraph vector for a new paragraph by gradient descent, keeping fixed the parameters for the rest of the model.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts