
Two minutes NLP — Using Word2Vec to learn node embeddings on graphs
Node2Vec, Word2Vec, graphs, and random walks

Learning useful representations from graphs is useful for a variety of machine learning applications. Naively, nodes in a graph can be represented with discrete vectors using one-hot encoding, similar to how words are encoded with the bag-of-words approach in NLP. However, as machine learning models have been tuned to work better on fixed-dimension continuous features, it would be useful to embed nodes in low-dimensional spaces similar to how word embeddings are learned in NLP with algorithms like Word2Vec, GloVe, and BERT.
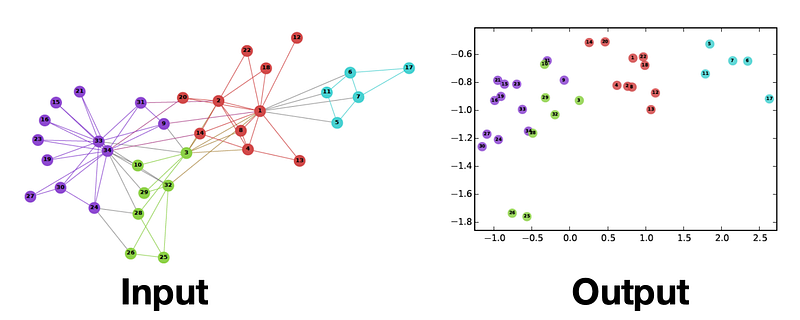
Can the word embedding algorithms from NLP be used to produce node embeddings of graphs as well?
Word embedding algorithms learn from a corpus of sentences, where each sentence is a sequence of consecutive words that share a context.
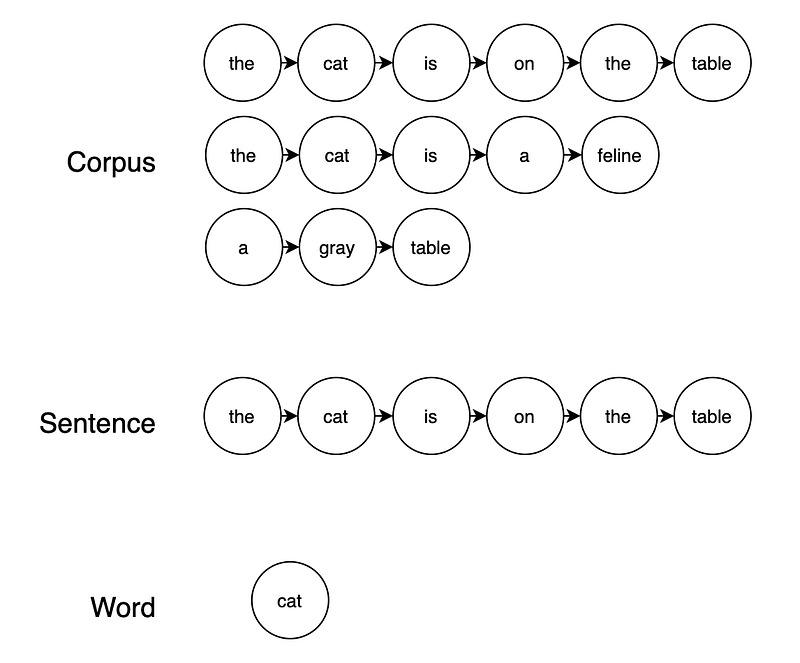
Similar to sentences, let’s try to extract sequences of nodes that share some context from graphs.
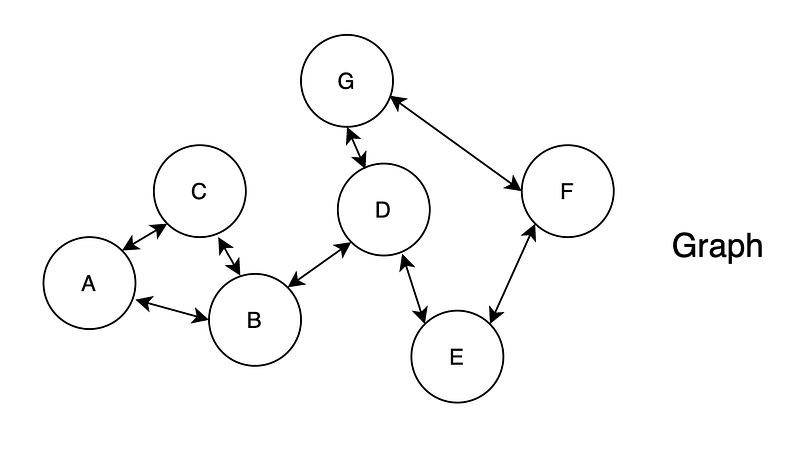
How can we get these sequences of nodes? Simple, using random walks!
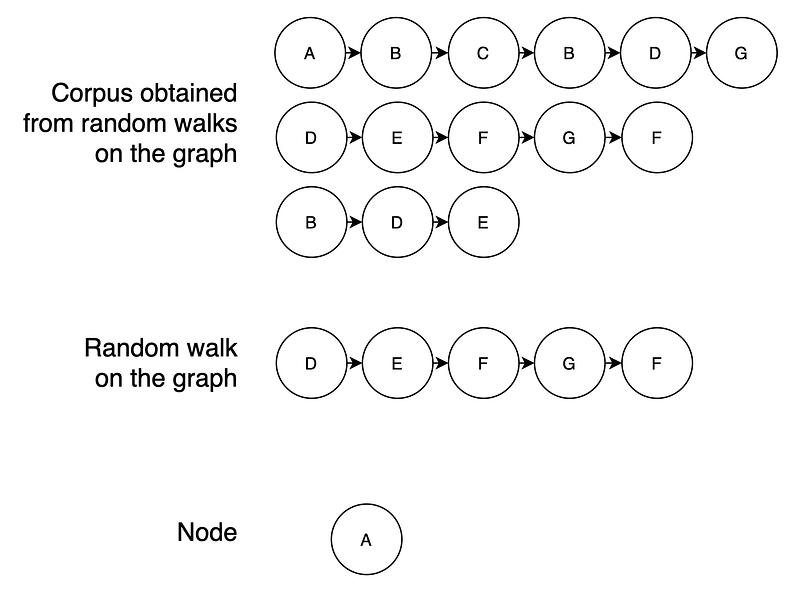
We can perform many random walks from distinct starting nodes of the graph to obtain a corpus of random walks, i.e. sequences of related nodes. With this corpus, we can use the same models we use in NLP to learn embeddings, such as Word2Vec.
Node2Vec is exactly this algorithm: it follows the intuition that random walks through a graph can be treated like sentences in a corpus. It’s part of a family of algorithms called walk-based graph embedding algorithms, which learn node embeddings in two steps:
- Create a corpus of node sequences by performing random walks on the graph
- Learn node embeddings on such corpus using machine learning models that learn on sequences.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts