
Two minutes NLP — Easy document annotation with Wikipedia concepts
Semantic annotations, Wikification, Ontologies, and PageRank
A specific type of semantic annotation, known as wikification, involves using Wikipedia as a source of possible semantic annotations. In this setting, Wikipedia is treated as a large and fairly general-purpose ontology, where each page is thought of as representing a concept, while the relations between concepts are represented by internal hyperlinks between different Wikipedia pages.
The advantage of this approach is that Wikipedia is a freely available source of information, it covers a wide range of topics, has a rich internal structure, and each concept is associated with a semi-structured textual document (i.e. the contents of the corresponding Wikipedia article) which can be used to aid in the process of semantic annotation.
In this article, I’ll explain the wikification process proposed in the paper Annotating Documents with relevant Wikipedia Concepts. The paper authors also built a web service that performs wikification with their algorithm for free.
Wikification process
The task of wikifying an input document can be broken down into several closely interrelated subtasks:
- Identification of candidate annotations.
- Disambiguation of semantic annotations.
- Choice of relevant annotations.
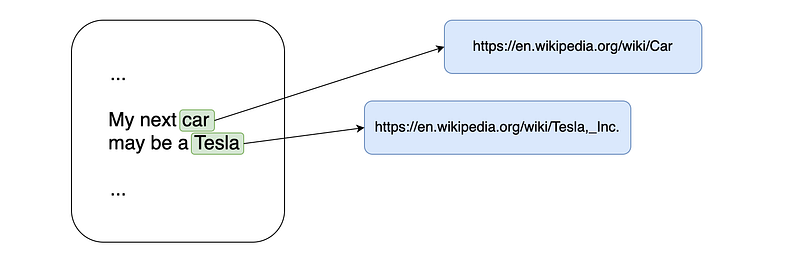
Let’s see them with an example. Suppose we want to annotate the text “My next car may be a Tesla”.
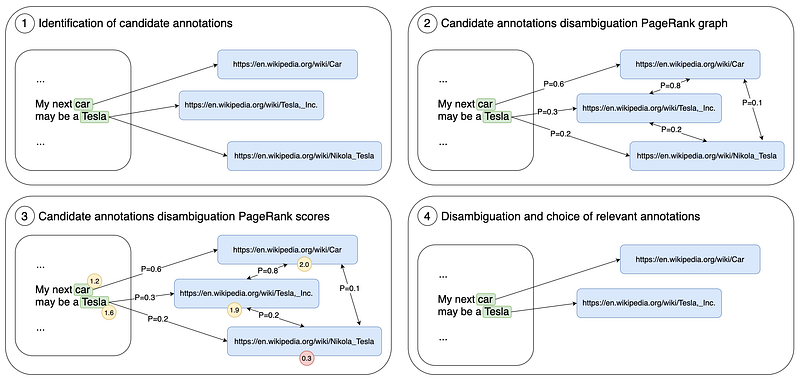
Identification of candidate annotations
The approach makes use of the rich internal structure of hyperlinks between Wikipedia pages. A hyperlink can be thought of as consisting of a source page, a target page, and the link text (also known as the anchor text).
If a source page contains a link with the anchor text A to the target page T, this is an indication that the phrase a might be a reference to (or representation of) the concept that corresponds to page T. Thus, if the input document that we’re trying to wikify contains the phrase A, it might be the case that this occurrence of A in the input document also constitutes a mention of the concept T, and the concept T is a candidate annotation for this particular phrase.
In our example, we got a candidate annotation for the word “car” and two candidate annotations for the word “Tesla”, which refer to the car company and to the scientist Nikola Tesla.
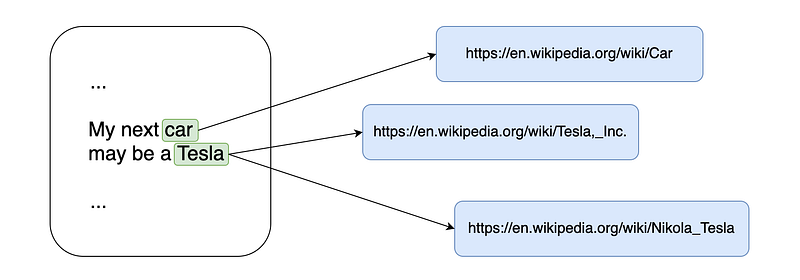
Disambiguation of semantic annotations
How can we disambiguate the correct annotation for the word “Tesla”? We can leverage the fact that the input text contains also the word “car”, which is mapped to the Wikipedia concept of car, which is more similar to the concept of the car company than the concept of Nikola Tesla.
The next question now is how do we compute the similarity between Wikipedia concepts. This can be done by building a graph between candidate annotations and linked Wikipedia concepts and using the PageRank algorithm to compute an importance score for each node.
The probability of each edge can be computed by analyzing on Wikipedia the frequencies of the links between pages with the specific anchor texts. More detail in the paper.
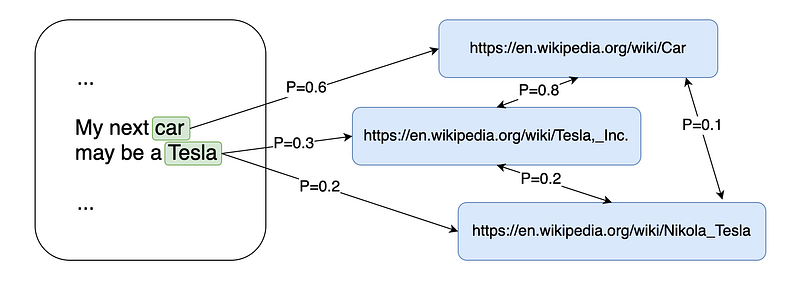
A high PageRank score means that the node is relevant for the graph, which in our case means that a Wikipedia concept or a candidate anchor text in the input document is relevant.
We can then disambiguate semantic annotations by keeping the Wikipedia concepts with the highest scores.
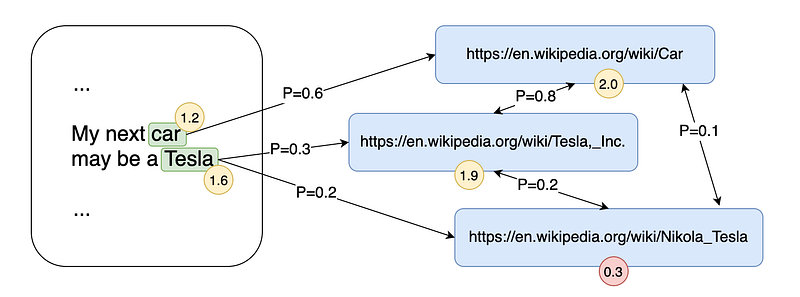
Choice of relevant annotations
The last step is to keep only the relevant annotations, which can be done easily by thresholding on the PageRank score previously obtained.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts




