
Two minutes NLP — The OpenAI WebGPT model that answers questions browsing the web
GPT-3, Information Retrieval, Text Synthesis, Imitation Learning, and Reward Modeling

The OpenAI team just presented WebGPT, a fine-tuned GPT-3 to answer long-form questions using a text-based web-browsing environment, which allows the model to search and navigate the web. The prototype copies how humans research answers to questions online: it submits search queries, follows links, and scrolls up and down web pages. It is trained to cite its sources, which makes it easier to give feedback to improve factual accuracy.

WebGPT is part of the field of long-form question-answering (LFQA), in which a paragraph-length answer is generated in response to an open-ended question. LFQA systems have the potential to become one of the main ways people learn about the world, but currently lag behind human performance. Existing work tends to focus on two core components of the task: Information Retrieval and Text Synthesis.
Instead of trying to improve these ingredients, OpenAI focused on combining them using more faithful training objectives. Answers are judged with human feedback for their factual accuracy, coherence, and overall usefulness.
The WebGPT model
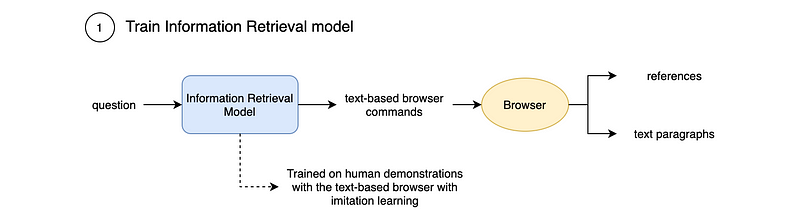
WebGPT is made of several components. First, there is an Information Retrieval Model which accepts a question as input and outputs commands to issue to the text-based browser and their references, with the goal of extracting relevant text paragraphs that answer the question. It is trained on human demonstrations with Imitation Learning.
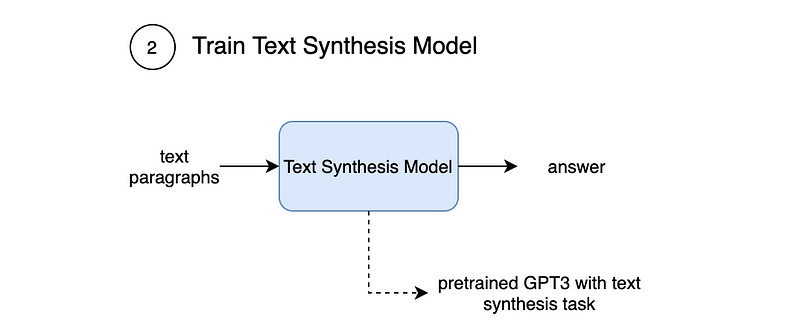
Second, a Text Synthesis Model is trained to put together several text paragraphs into a single coherent text. GPT3 is able to do this with some finetuning.
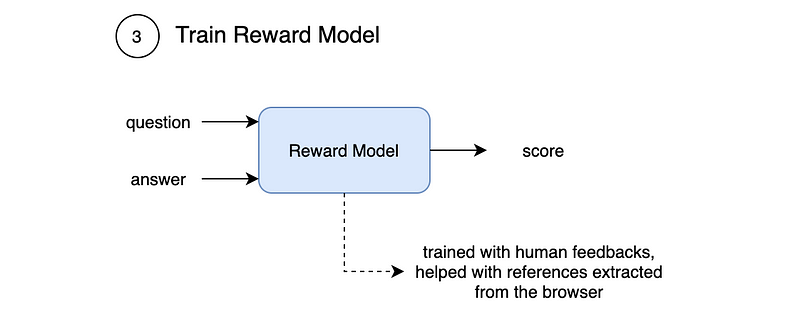
Third, we have a reward modeling step with a Reward Model that predicts a quality score from a question and an answer. It is trained with human feedbacks, where humans were helped by the references extracted by the Information Retrieval Model and the browser.
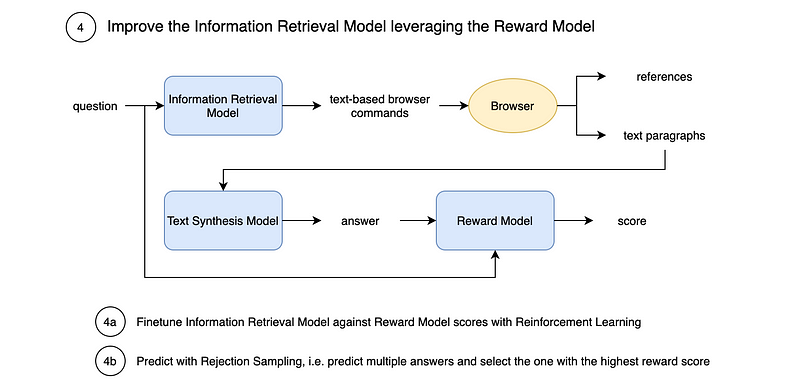
The last step is to put together the three models and improve the whole pipeline leveraging the Reward Model. This can be done in two ways:
- Finetuning the Information Retrieval Model against the Reward Model scores with Reinforcement Learning (specifically PPO) and some mitigations to avoid over-optimization on the Reward Model.
- Predicting with Rejection Sampling (best-of-n), i.e. predicting multiple answers and selecting the one with the highest reward score.
Why WebGPT
Language models like GPT-3 are useful for many different tasks, but have a tendency to invent information when performing tasks requiring vague real-world knowledge. To address this, WebGPT uses a text-based web browser to collect passages from web pages and then uses these to compose an answer and show relevant references.
Pay attention that answers with references are often perceived as having an air of authority, which can obscure the fact that the model still makes basic errors.
Model evaluation
The model is evaluated in three different ways:
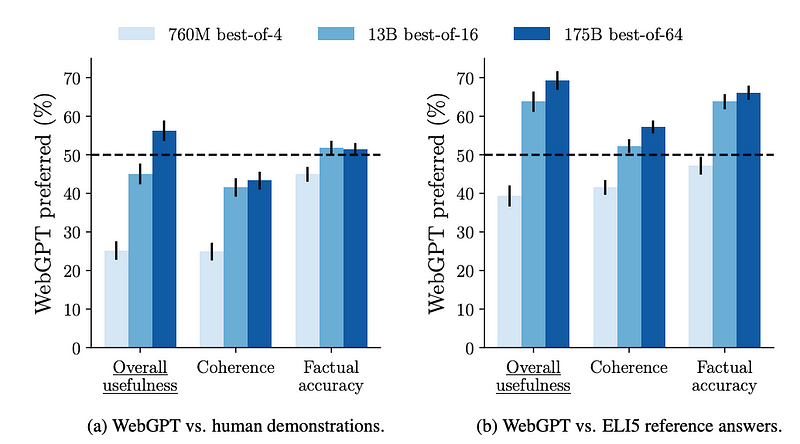
- Model’s answers are compared to answers written by human demonstrators on a held-out set of questions. The model’s answers are preferred 56% of the time, demonstrating human-level usage of the text-based browser.
- Model’s answers are compared to the highest-voted answer provided by the ELI5 dataset. The model’s answers are preferred 69% of the time.
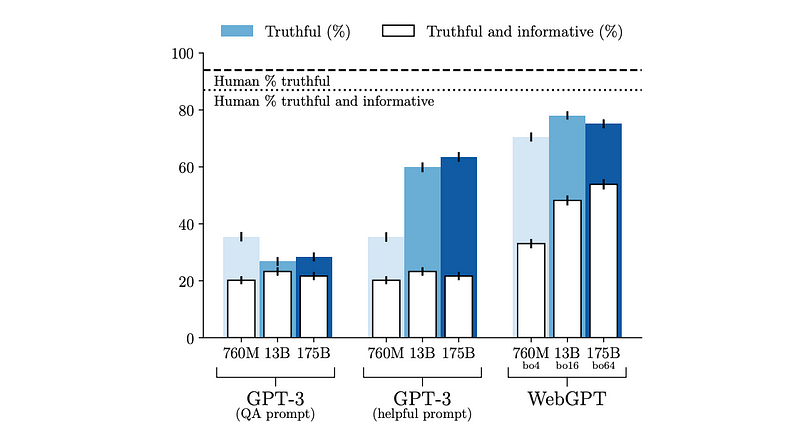
- The model is evaluated on TruthfulQA, an adversarial dataset of short-form questions. The model’s answers are true 75% of the time and are both true and informative 54% of the time, outperforming GPT-3, but falling short of human performance.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts