
Two minutes NLP — Visualizing Global vs Local Attention
Seq2seq, Global Attention, Local Attention, Monotonic Alignment, and Predictive Alignment

Under the hood, seq2seq models are often composed of an encoder and a decoder. Without Attention mechanisms, the encoder processes each item in the input sequence and encloses the information it captures into a vector, called context vector. After processing the entire input, the encoder sends the context vector over to the decoder, which begins producing the output sequence item by item.
Seq2seq with Attention
Empirical experience shows that a fixed-length context vector is not able to remember long input sequences, as it tends to forget the earlier parts of the sequence. The attention mechanism was born to resolve this problem.
Consider the example sentence “Where is Wally” which should be translated to its Italian counterpart “Dove è Wally”. Here is how the encoder processes the input word by word, producing three different hidden states.
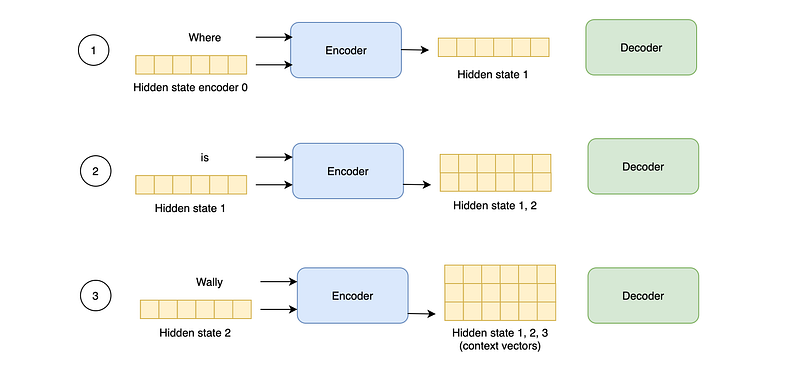
With Attention, the encoder passes all its hidden states to the decoder instead of passing only the final hidden state.
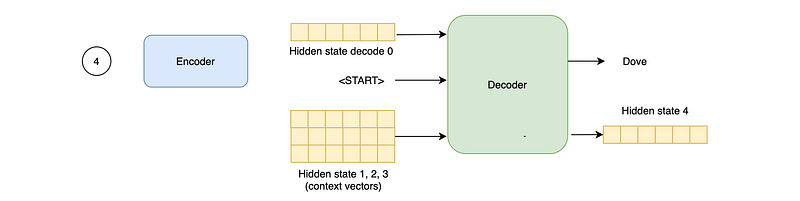
How does the decoder use the encoder hidden states, as their amount depends on the length of the input sequence? With an Attention mechanism.
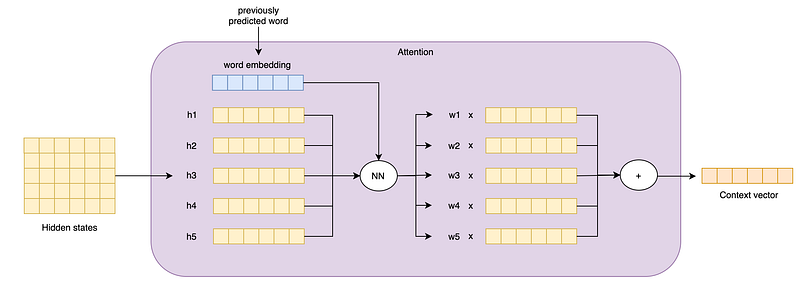
Attention produces a single fixed-size context vector from all the encoder hidden states (often with a weighted sum). The weight of each hidden state depends on the input word that the decoder is accepting at the moment, and represents the “attention” that must be given to that context when processing such input word.
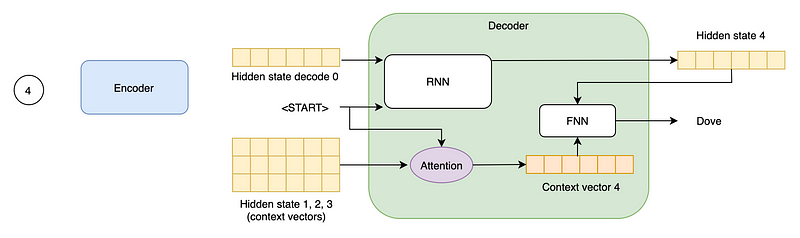
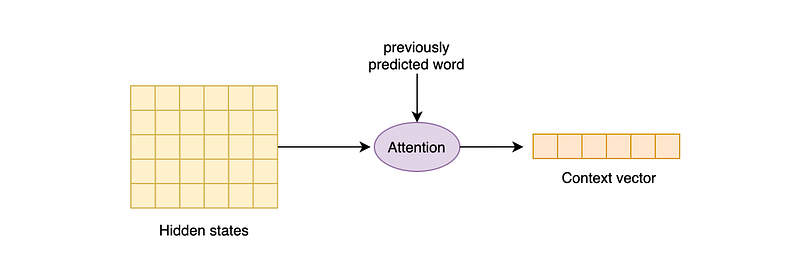
Abstracting from the encoder-decoder architecture, an Attention mechanism tries to condense a list of hidden states into a single context vector, also taking into account what word is the model translating at the moment.
Seq2seq with Global Attention
Global Attention is an Attention mechanism that considers all the hidden states in creating the context vector.
It does so by performing a weighted sum, where each specific weight is computed by a feedforward NN taking into account its specific hidden state and what word is the model translating at the moment.
Seq2seq with Local Attention
When Global Attention is applied, a lot of computation occurs. This is because all the hidden states must be taken into consideration, concatenated into a matrix, and processed by a NN to compute their weights.
Can we reduce the number of computations, without sacrificing quality? Yes, with Local Attention!
Local Attention is an Attention mechanism that considers only a subset of all the hidden states in creating the context vector. The subset can be obtained in many different ways, such as with Monotonic Alignment and Predictive Alignment.
Seq2seq with Monotonic Alignment Local Attention
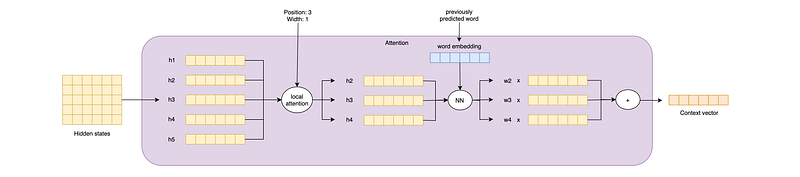
Monotonic Alignment Local Attention selects the subset of hidden states by keeping only the hidden states closer to the current translation step.
For example, if we are translating a five-word sentence like “Where is the red car”, at the third translation step we may consider only the hidden states produced when the encoder processed words from the second to the fourth.
Seq2seq with Predictive Alignment Local Attention
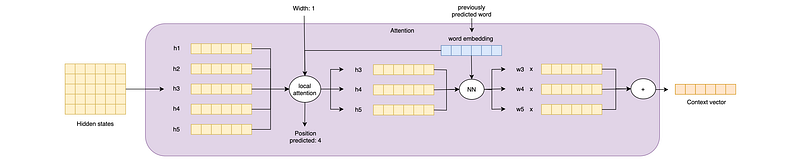
Predictive Alignment Local Attention selects the subset of hidden states by keeping only the hidden states closer to a predicted position, taking into account what word is the model translating at the moment.
For example, if we are translating a five-word sentence like “Where is the red car”, at the third translation step we may consider only the hidden states produced when the encoder processed words from the third to the fifth, because a NN predicted that the hidden states near the fourth may be important.
Attention matrices of different types of Attention mechanisms
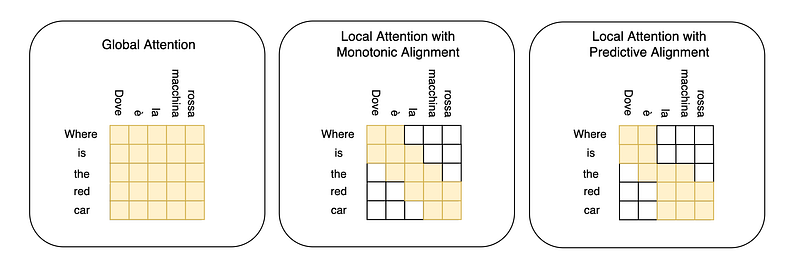
The hidden states considered at each translation step can be visualized with matrices, where a cell is colored if the hidden state produced when processing the word on the left has been used when decoding the word on the top.
Note that:
- Global Attention considers all the hidden states at each translation step.
- Local Attention with Monotonic Alignment is similar to a diagonal matrix, without irregularities.
- Local Attention with Predictive Alignment is often similar to a diagonal matrix but presents some irregularities as important hidden states are predicted at each translation step.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts




