
Two minutes NLP — How the DeepMind RETRO model decouples reasoning and memorization
Language Models, Retrieval Databases, GPT-3, Jurassic-1, and the Pile

In recent years, significant performance gains in language modeling have been achieved by increasing the number of parameters in Transformer models. This has led to a huge increase in training energy costs and resulted in a generation of large Language Models with 100+ billion parameters. At the same time, large datasets containing trillions of words have been collected to train these models.
The benefits of increasing the number of parameters come from two factors:
- More reasoning capabilities in the form of computations at training and inference time.
- More memorization of the training data.
DeepMind is exploring how to decouple these aspects, i.e. how to efficiently augment language models with a massive-scale memory without significantly increasing computations. Specifically, DeepMind suggests retrieval from a large text database as a complementary path to scaling language models.
With this goal in mind, DeepMind introduced the Retrieval-Enhanced Transformer (RETRO) model: a language model that predicts the next words by conditioning on document chunks retrieved from a large corpus.
How RETRO works
Consider the sample query “The 2021 Women’s US Open was won”. A standard language model would predict a plausible continuation with the knowledge stored in the network parameters. RETRO, instead, looks for similar sequences in the Retrieval Database, withdraws their continuations, and conditions on them to predict a new plausible continuation.
The search for similar sentences is done with Nearest Neighbors on BERT embeddings pre-computed on all the sentences stored on the Retrieval Database.
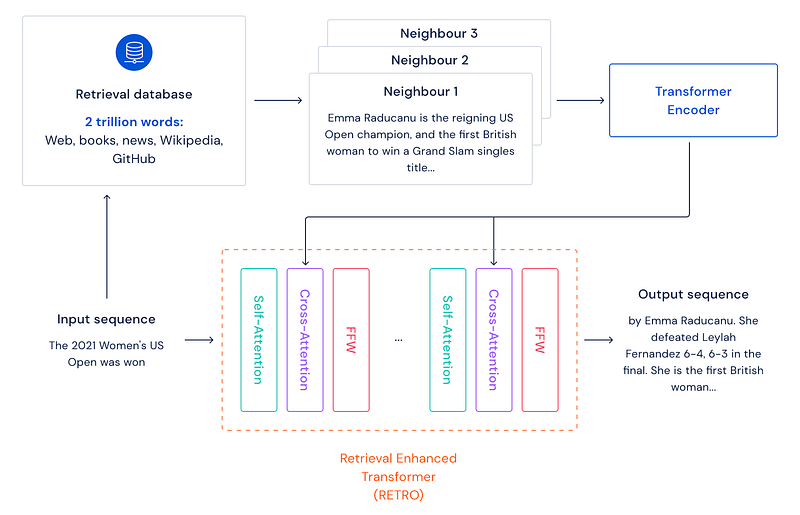
By working on texts extracted from the Retrieval Database, RETRO increases the interpretability of model predictions and provides a route for direct interventions to improve the safety of text continuation.
RETRO performance
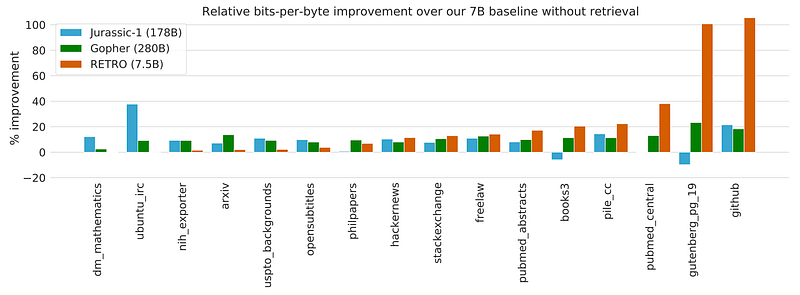
RETRO obtains comparable performance to GPT-3 and Jurassic-1 on the Pile dataset (a standard language modeling benchmark), despite using 25× fewer parameters.
Evaluating RETRO performance on the Pile dataset, a 7.5 billion parameter RETRO model outperforms the 175 billion parameter Jurassic-1 on 10 out of 16 datasets and outperforms the 280B Gopher on 9 out of 16 datasets, despite being over an order of magnitude smaller.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts