
Two minutes NLP — New DeepMind’s Gopher Language Model performance in a nutshell
Gopher, GPT-3, Jurassic-1, and Megatron-Turing NLG

In their new paper Scaling Language Models: Methods, Analysis & Insights from Training Gopher, DeepMind presents an analysis of Transformer-based language model performance across a wide range of model scales — from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority.
Gopher comparison with previous language model State of the Art
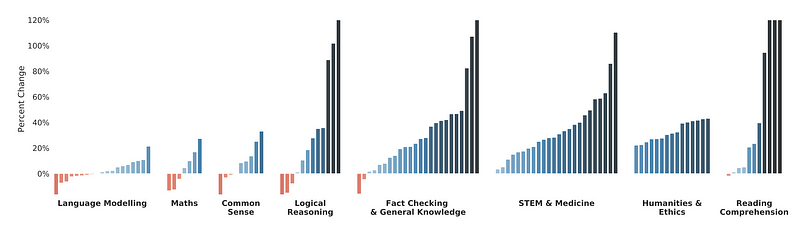
The figure shows the percentage change in performance metric (higher is better) of Gopher versus state-of-the-art language model performance across 124 tasks, where each bar represents a task. Gopher shows an improvement across roughly 80% of the tasks. The best-published results include (175B parameters) GPT-3, (178B parameters) Jurassic-1, and (530B parameters) Megatron-Turing NLG.
Gopher displays the most uniform improvement across reading comprehension, humanities, ethics, STEM, medicine, and fact-checking categories. For common sense reasoning, logical reasoning, and maths we see much smaller performance improvements and several tasks that have a deterioration in performance. The general trend is less improvement in reasoning-heavy tasks and a larger and more consistent improvement in knowledge-intensive tests.
Gopher performance across the 57 tasks in Massive Multitask Language Understanding (MMLU)

MMLU tasks consist of real-world human exams covering a range of academic subjects. Gopher improves over the prior supervised SOTA models by a considerable margin (>30%) however it is far from human expert.
Gopher is situated between the 2022 and 2023 forecast of average SOTA accuracy made by 73 expert human forecasters on the MMLU tasks.
Performance Improvements with Scale
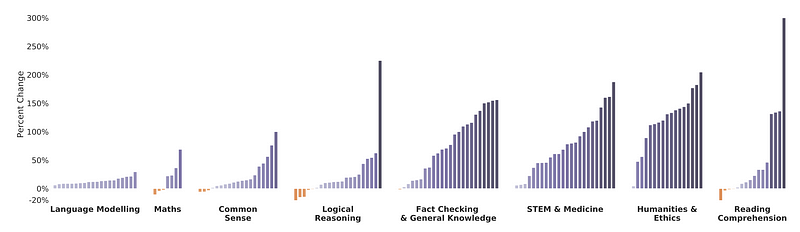
Follows a comparison of the performance of Gopher (280B parameters) to the best performance of the smaller models up to 7.1B. The figure shows the percentage change in performance metric (higher is better) across 124 tasks, where each bar represents a task.
In nearly every case, Gopher outperforms the best smaller model’s performance. Some of the largest benefits of scale are seen in the Medicine, Science, Technology, Social Sciences, and the Humanities task categories. These same categories are also where we see the greatest performance improvement over language model SOTA. On the other hand, scale has a reduced benefit for tasks in the Maths, Logical Reasoning, and Common Sense categories.
The results suggest that scalability alone is unlikely to lead to breakthroughs in performance for certain kinds of mathematical or logical reasoning tasks.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!
Two minutes NLP related posts