
Transfer Learning for Text Classification Using Hugging Face Transformers Trainer
Fine-tuning a pretrained transformer BERT model for customized sentiment analysis using transformer PyTorch Trainer from Hugging Face

Hugging Face provides three ways to fine-tune a pretrained text classification model: Tensorflow Keras, PyTorch, and transformer trainer. Transformer trainer is an API for feature-complete training in PyTorch without writing all the loops. This tutorial will use the transformer trainer to fine-tune a text classification model. We will talk about the following:
- How does transfer learning work?
- How to convert a pandas dataframe into a Hugging Face Dataset?
- How to tokenize text, load a pretrained model, set training arguments, and train a transfer learning model?
- How to make predictions and evaluate the model performance of a fine-tuned transfer learning model for text classification?
- How to save the model and re-load the model?
Resources for this post:
- Video tutorial for this post on YouTube
- Click here for the Colab notebook
- More video tutorials on NLP
- More blog posts on NLP
Let’s get started!
Step 0: Transfer Learning Algorithms
In step 0, we will talk about how transfer learning works.
Transfer learning is a machine learning technique that reuses a pretrained large deep learning model on a new task. It usually includes the following steps:
- Select a pretrained model that is suitable for the new task. For example, if the new task includes text from different languages, a multi-language pretrained model needs to be selected.
- Keep all the weights and biases from the pretrained model except for the output layer. This is because the output layer for the pretrained model is for the pretrained tasks and it needs to be replaced with the new task.
- Feed randomly initialize weights and biases into the new head of the new task. For a sentiment analysis transfer learning (aka fine-tuning) model on a pretrained BERT model, we will remove the head that classifies mask words, and replace it with the two sentiment analysis labels, positive and negative.
- Retrain the model for the new task with the new data, utilizing the pretrained weights and biases. Because the weights and biases store the knowledge learned from the pretrained model, the fine-tuned transfer learning model can build on that knowledge and does not need to learn from scratch.
Step 1: Install And Import Python Libraries
In step 1, we will install and import python libraries.
Firstly, let’s install transformers, datasets, and evaluate.
# Install libraries
!pip install transformers datasets evaluateAfter installing the python packages, we will import the python libraries.
pandasandnumpyare imported for data processing.tensorflowandtransformersare imported for modeling.Datasetis imported for the Hugging Face dataset format.evaluateis imported for model performance evaluation.
# Data processing
import pandas as pd
import numpy as np
# Modeling
import tensorflow as tf
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, EarlyStoppingCallback, TextClassificationPipeline
# Hugging Face Dataset
from datasets import Dataset
# Model performance evaluation
import evaluateStep 2: Download And Read Data
The second step is to download and read the dataset.
The UCI Machine Learning Repository has the review data from three websites: imdb.com, amazon.com, and yelp.com. We will use the review data from amazon.com for this tutorial. Please follow these steps to download the data.
- Go to: https://archive.ics.uci.edu/ml/datasets/Sentiment+Labelled+Sentences
- Click “Data Folder”
- Download “sentiment labeled sentences.zip”
- Unzip “sentiment labeled sentences.zip”
- Copy the file “amazon_cells_labelled.txt” to your project folder
Those who are using Google Colab for this analysis need to mount Google Drive to read the dataset. You can ignore the code below if you are not using Google Colab.
drive.mountis used to mount to the Google drive so the colab notebook can access the data on the Google drive.os.chdiris used to change the default directory on Google drive. I set the default directory to the folder where the review dataset is saved.!pwdis used to print the current working directory.
Please check out Google Colab Tutorial for Beginners for details about using Google Colab for data science projects.
# Mount Google Drive
from google.colab import drive
drive.mount('/content/drive')
# Change directory
import os
os.chdir("drive/My Drive/contents/nlp")
# Print out the current directory
!pwdNow let’s read the data into a pandas dataframe and see what the dataset looks like.
The dataset has two columns. One column contains the reviews and the other column contains the sentiment label for the review.
# Read in data
amz_review = pd.read_csv('sentiment labelled sentences/amazon_cells_labelled.txt', sep='\t', names=['review', 'label'])
# Take a look at the data
amz_review.head()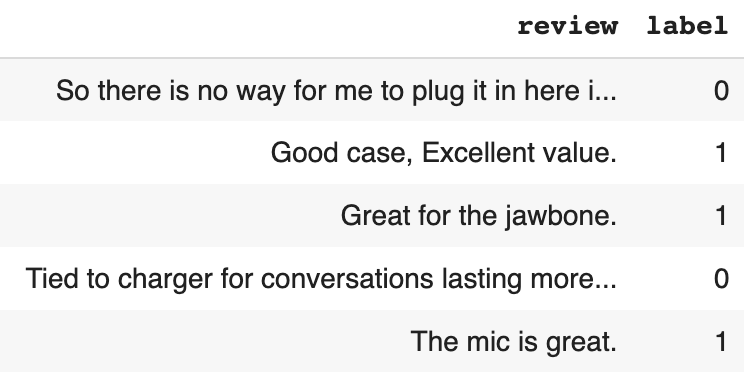
.info helps us to get information about the dataset.
# Get the dataset information
amz_review.info()From the output, we can see that this data set has 1000 records and no missing data. The review column is the object type and the label column is the int64 type.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 review 1000 non-null object
1 label 1000 non-null int64
dtypes: int64(1), object(1)
memory usage: 15.8+ KBThe label value of 0 represents negative reviews and the label value of 1 represents positive reviews. The dataset has 500 positive reviews and 500 negative reviews. It is well-balanced, so we can use accuracy as the metric to evaluate the model performance.
# Check the label distribution
amz_review['label'].value_counts()Output:
0 500
1 500
Name: label, dtype: int64Step 3: Train Test Split
In step 3, we will split the dataset and have 80% as the training dataset and 20% as the testing dataset.
Using the sample method, we set frac=0.8, which randomly samples 80% of the data. random_state=42 ensures that the sampling result is reproducible.
Dropping the train_data from the review dataset gives us the rest 20% of the data, which is our testing dataset.
# Training dataset
train_data = amz_review.sample(frac=0.8, random_state=42)
# Testing dataset
test_data = amz_review.drop(train_data.index)
# Check the number of records in training and testing dataset.
print(f'The training dataset has {len(train_data)} records.')
print(f'The testing dataset has {len(test_data)} records.')After the train test split, there are 800 reviews in the training dataset and 200 reviews in the testing dataset.
The training dataset has 800 records.
The testing dataset has 200 records.Step 4: Convert Pandas Dataframe to Hugging Face Dataset
In step 4, the training and the testing datasets will be converted from pandas dataframe to Hugging Face Dataset format.
Hugging Face Dataset objects are memory-mapped on drive, so they are not limited by RAM memory, which is very helpful for processing large datasets.
We use Dataset.from_pandas to convert a pandas dataframe to a Hugging Face Dataset.
# Convert pyhton dataframe to Hugging Face arrow dataset
hg_train_data = Dataset.from_pandas(train_data)
hg_test_data = Dataset.from_pandas(test_data)The length of the Hugging Face Dataset is the same as the number of records in the pandas dataframe. For example, there are 800 records in the pandas dataframe for the training dataset, and the length of the converted Hugging Face Dataset for the training dataset is 800 too.
hg_train_data[0] gives us the first record in the Hugging Face Dataset. It is a dictionary with three keys, review, label, and __index_level_0__.
reviewis the variable name for the review text. The name is inherited from the column name of the pandas dataframe.labelis the variable name for the sentiment of the review text. The name is inherited from the column name of the pandas dataframe too.__index_level_0__is an automatically generated field from the pandas dataframe. It stores the index of the corresponding record.
# Length of the Dataset
print(f'The length of hg_train_data is {len(hg_train_data)}.\n')
# Check one review
hg_train_data[0]In this example, we can see that the review is Thanks again to Amazon for having the things I need for a good price!, the sentiment for the review is positive/1, and the index of this record is 521 in the pandas dataframe.
The length of hg_train_data is 800.
{'review': 'Thanks again to Amazon for having the things I need for a good price!',
'label': 1,
'__index_level_0__': 521}Checking the index 521 in the pandas dataframe confirms the same information with Hugging Face Dataset.
# Validate the record in pandas dataframe
amz_review.iloc[[521]]
Step 5: Tokenize Text
In step 5, we will tokenize the review text using a tokenizer.
A tokenizer converts text into numbers to use as the input of the NLP (Natural Language Processing) models. Each number represents a token, which can be a word, part of a word, punctuation, or special tokens. How the text is tokenized is determined by the pretrained model. AutoTokenizer.from_pretrained("bert-base-cased") is used to download vocabulary from the pretrained bert-base-cased model, meaning that the text will be tokenized like a BERT model.
# Tokenizer from a pretrained model
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# Take a look at the tokenizer
tokenizerWe can see that the tokenizer contains information such as model name, vocabulary size, max length, padding position, truncation position, and special tokens.
There are five special tokens for the BERT model. Other models may have different special tokens.
- The tokens that are not part of the BERT model training dataset are unknown tokens. The unknown token is [UNK] and the ID for the unknown token is 100.
- The separator token is [SEP] and the ID for the separator token is 102.
- The pad token is [PAD] and the ID for the pad token is 0.
- The sentence level classification token is [CLS] and the ID for the classification token is 101.
- The mask token is [MASK] and the ID for the mask token is 103.
# Mapping between special tokens and their IDs.
print(f'The unknown token is {tokenizer.unk_token} and the ID for the unkown token is {tokenizer.unk_token_id}.')
print(f'The seperator token is {tokenizer.sep_token} and the ID for the seperator token is {tokenizer.sep_token_id}.')
print(f'The pad token is {tokenizer.pad_token} and the ID for the pad token is {tokenizer.pad_token_id}.')
print(f'The sentence level classification token is {tokenizer.cls_token} and the ID for the classification token is {tokenizer.cls_token_id}.')
print(f'The mask token is {tokenizer.mask_token} and the ID for the mask token is {tokenizer.mask_token_id}.')Output:
The unknown token is [UNK] and the ID for the unkown token is 100.
The seperator token is [SEP] and the ID for the seperator token is 102.
The pad token is [PAD] and the ID for the pad token is 0.
The sentence level classification token is [CLS] and the ID for the classification token is 101.
The mask token is [MASK] and the ID for the mask token is 103.After downloading the model vocabulary, the method tokenizer is used to tokenize the review corpus.
max_lengthindicates the maximum number of tokens kept for each document.
- If the document has more tokens than the
max_length, it will be truncated. - If the document has less tokens than the
max_length, it will be padded with zeros. - If
max_lengthis unset or set toNone, the maximum length from the pretrained model will be used. If the pretrained model does not have a maximum length parameter,max_lengthwill be deactivated.
truncationcontrols how the token truncation is implemented.truncation=Trueindicates that the truncation length is the length specified bymax_length. Ifmax_lengthis not specified, the max_length of the pretrained model is used.paddingmeans adding zeros to shorter reviews in the dataset. Thepaddingargument controls howpaddingis conducted.
padding=Trueis the same aspadding='longest'. It checks the longest sequence in the batch and pads zeros to that length. There is no padding if only one text document is provided.padding='max_length'pads tomax_lengthif it is specified, otherwise, it pads to the maximum acceptable input length for the model.padding=Falseis the same aspadding='do_not_pad'. It is the default, indicating that no padding is applied, so it can output a batch with sequences of different lengths.
# Funtion to tokenize data
def tokenize_dataset(data):
return tokenizer(data["review"],
max_length=32,
truncation=True,
padding="max_length")
# Tokenize the dataset
dataset_train = hg_train_data.map(tokenize_dataset)
dataset_test = hg_test_data.map(tokenize_dataset)After tokenization, we can see that both the training and the testing Dataset have 6 features, 'review', 'label', '__index_level_0__', 'input_ids', 'token_type_ids', and 'attention_mask'. The number of rows is stored with num_rows.
# Take a look at the data
print(dataset_train)
print(dataset_test)Output:
Dataset({
features: ['review', 'label', '__index_level_0__', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 800
})
Dataset({
features: ['review', 'label', '__index_level_0__', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 200
})dataset_train[0] gives us the content for the first record in the training dataset in a dictionary format.
'review'has the review text. The first review of the training dataset is'Thanks again to Amazon for having the things I need for a good price!'.'label'is the label of the classification. The first record is a positive review, so the label is 1.'__index_level_0__'is the index of the record. 521 means that the first record in the training dataset has the index 521 in the original pandas dataframe.'input_ids'are the IDs for the tokens. There are 32 token IDs because themax_lengthis 32 for the tokenization.'token_type_ids'is also called segment IDs.
- BERT was trained on two tasks, Masked Language Modeling and Next Sentence Prediction.
'token_type_ids'is for the Next Sentence Prediction, where two sentences are used to predict whether the second sentence is the next sentence for the first one. - The first sentence has all the tokens represented by zeros, and the second sentence has all the tokens represented by ones.
- Because our classification task does not have a second sentence, all the values for
'token_type_ids'are zeros.
'attention_mask'indicates which token ID should get attention from the model, so the padding tokens are all zeros and other tokens are 1s.
# Check the first record
dataset_train[0]Output:
{'review': 'Thanks again to Amazon for having the things I need for a good price!',
'label': 1,
'__index_level_0__': 521,
'input_ids': [101,
5749,
1254,
1106,
9786,
1111,
1515,
1103,
1614,
146,
1444,
1111,
170,
1363,
3945,
106,
102,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0],
'token_type_ids': [0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0],
'attention_mask': [1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0]}Step 6: Load Pretrained Model
In step 6, we will load the pretrained model for sentiment analysis.
AutoModelForSequenceClassificationloads the BERT model without the sequence classification head.- The method
from_pretrained()loads the weights from the pretrained model into the new model, so the weights in the new model are not randomly initialized. Note that the new weights for the new sequence classification head are going to be randomly initialized. bert-base-casedis the name of the pretrained model. We can change it to a different model based on the nature of the project.num_labelsindicates the number of classes. Our dataset has two classes, positive and negative, sonum_labels=2.
# Load model
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2)Step 7: Set Training Argument
In step 7, we will set the training arguments for the model.
Hugging Face has 96 parameters for TrainingArguments, which provides a lot of flexibility in fine-tuning the transfer learning model.
output_diris the directory to write the model checkpoints and model predictions.logging_diris the directory for saving logs.logging_strategyis the strategy for logging the training information.
'no'means no logging for the training.'epoch'means logging at the end of each epoch.'steps'means logging at the end of eachlogging_steps.
logging_stepsis the number of steps between two logs. The default is 500.num_train_epochsis the total number of training epochs. The default value is 3.per_device_train_batch_sizeis the batch size per GPU/TPU core/CPU for training. The default value is 8.per_device_eval_batch_sizeis the batch size per GPU/TPU core/CPU for evaluation. The default value is 8.learning_rateis the initial learning rate for AdamW optimizer. The default value is 5e-5.seedis for reproducibility.save_strategyis the strategy for saving the checkpoint during training.
'no'means do not save during training.'epoch'means saving at the end of each epoch.'steps'means saving at the end of eachsave_steps.'steps'is the default value.
save_stepsis the number of steps before two checkpoint saves. The default value is 500.evaluation_strategyis the strategy for evaluation during training. It's helpful for us to monitor the model performance during model fine-tuning.
'no'means no evaluation during training.'epoch'means evaluating at the end of each epoch and the evaluation results will be printed out at the end of each epoch.'steps'means evaluating and reporting at the end of eacheval_steps.'no'is the default value.
eval_stepsis the number of steps between two evaluations ifevaluation_strategy='steps'. It defaults to the same value aslogging_stepsif not set.load_best_model_at_end=Trueindicates that the best model will be loaded at the end of the training. The default isFalse. When it is set toTrue, thesave_strategyandevaluation_strategymust be the same. When both arguments are'steps', the value ofsave_stepsneeds to be a round multiple of the value ofeval_steps.
# Set up training arguments
training_args = TrainingArguments(
output_dir="./sentiment_transfer_learning_transformer/",
logging_dir='./sentiment_transfer_learning_transformer/logs',
logging_strategy='epoch',
logging_steps=100,
num_train_epochs=2,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
learning_rate=5e-6,
seed=42,
save_strategy='epoch',
save_steps=100,
evaluation_strategy='epoch',
eval_steps=100,
load_best_model_at_end=True
)Step 8: Set Evaluation Metrics
In step 8, we will set the evaluation metric because Hugging Face Trainer does not evaluate the model performance automatically during the training process.
Hugging Face has an evaluate library with over 100 evaluation modules. We can see the list of all the modules using evaluate.list_evaluation_modules().
# Number of evaluation modules
print(f'There are {len(evaluate.list_evaluation_modules())} evaluation models in Hugging Face.\n')
# List all evaluation metrics
evaluate.list_evaluation_modules()Output:
'lvwerra/test',
'precision',
'code_eval',
'roc_auc',
'cuad',
'xnli',
'rouge',
'pearsonr',
'mse',
'super_glue',
'comet',
'cer',
'sacrebleu',
'mahalanobis',
'wer',
'competition_math',
'f1',
'recall',
'coval',
'mauve',
'xtreme_s',
'bleurt',
'ter',
'accuracy',
'exact_match',
'indic_glue',
'spearmanr',
'mae',
'squad',
'chrf',
'glue',
'perplexity',
'mean_iou',
'squad_v2',
'meteor',
'bleu',
'wiki_split',
'sari',
'frugalscore',
'google_bleu',
'bertscore',
'matthews_correlation',
'seqeval',
'trec_eval',
'rl_reliability',
'jordyvl/ece',
'angelina-wang/directional_bias_amplification',
'cpllab/syntaxgym',
'lvwerra/bary_score',
'kaggle/amex',
'kaggle/ai4code',
'hack/test_metric',
'yzha/ctc_eval',
'codeparrot/apps_metric',
'mfumanelli/geometric_mean',
'daiyizheng/valid',
'poseval',
'erntkn/dice_coefficient',
'mgfrantz/roc_auc_macro',
'Vlasta/pr_auc',
'gorkaartola/metric_for_tp_fp_samples',
'idsedykh/metric',
'idsedykh/codebleu2',
'idsedykh/codebleu',
'idsedykh/megaglue',
'kasmith/woodscore',
'cakiki/ndcg',
'brier_score',
'Vertaix/vendiscore',
'GMFTBY/dailydialogevaluate',
'GMFTBY/dailydialog_evaluate',
'jzm-mailchimp/joshs_second_test_metric',
'ola13/precision_at_k',
'yulong-me/yl_metric',
'abidlabs/mean_iou',
'abidlabs/mean_iou2',
'KevinSpaghetti/accuracyk',
'Felipehonorato/my_metric',
'NimaBoscarino/weat',
'ronaldahmed/nwentfaithfulness',
'Viona/infolm',
'kyokote/my_metric2',
'kashif/mape',
'Ochiroo/rouge_mn',
'giulio98/code_eval_outputs',
'leslyarun/fbeta_score',
'giulio98/codebleu',
'anz2/iliauniiccocrevaluation',
'zbeloki/m2',
'xu1998hz/sescore',
'mase',
'mape',
'smape',
'dvitel/codebleu',
'NCSOFT/harim_plus',
'JP-SystemsX/nDCG',
'sportlosos/sescore',
'Drunper/metrica_tesi',
'jpxkqx/peak_signal_to_noise_ratio',
'jpxkqx/signal_to_reconstrution_error',
'hpi-dhc/FairEval',
'nist_mt',
'lvwerra/accuracy_score',
'character',
'charcut_mt',
'fengyuli2002/clip_score',
'ybelkada/cocoevaluate',
'harshhpareek/bertscore',
'posicube/mean_reciprocal_rank',
'bstrai/classification_report',
'omidf/squad_precision_recall',
'mcnemar',
'exact_match',
'wilcoxon',
'ncoop57/levenshtein_distance',
'kaleidophon/almost_stochastic_order',
'word_length',
'lvwerra/element_count',
'word_count',
'text_duplicates',
'perplexity',
'label_distribution',
'toxicity',
'prb977/cooccurrence_count',
'regard',
'honest',
'NimaBoscarino/pseudo_perplexity']Since our dataset is highly balanced, we will use accuracy as the evaluation metric. It can be loaded using evaluate.load("accuracy"). After getting predictions from the model, the metric is computed using metric.compute.
# Function to compute the metric
def compute_metrics(eval_pred):
metric = evaluate.load("accuracy")
logits, labels = eval_pred
# probabilities = tf.nn.softmax(logits)
predictions = np.argmax(logits, axis=1)
return metric.compute(predictions=predictions, references=labels)Step 9: Train Model Using Transformer Trainer
In step 9, we will train the model using the transformer Trainer.
- model is the model for training, evaluation, or prediction by the
Trainer. argstakes the arguments for tweaking theTrainer. It defaults to the instance ofTrainingArguments.train_datasetis the training dataset name. If the dataset is inDatasetformat, the unused columns will be automatically ignored. In our training dataset,__index_level_0__andrevieware not used by the model, so they are ignored.eval_datasetis the evaluation dataset name. Similar to thetrain_dataset, the unused columns will be automatically ignored for theDatasetformat.compute_metricstakes the function for calculating evaluation metrics.callbackstakes a list of callbacks to customize the training loop.EarlyStoppingCallbackstops the training byearly_stopping_patiencefor the evaluation calls. There is no practical need to use early stopping because there are only two epochs for the model. It is included as an example code reference.
# Train the model
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset_train,
eval_dataset=dataset_test,
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback(early_stopping_patience=1)]
)
trainer.train()We can see that the accuracy is above 90 percent in just 2 epochs.
***** Running training *****
Num examples = 800
Num Epochs = 2
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 4
Gradient Accumulation steps = 1
Total optimization steps = 400
Number of trainable parameters = 108311810
[400/400 16:31, Epoch 2/2]
Epoch Training Loss Validation Loss Accuracy
1 0.628300 0.459848 0.895000
2 0.344500 0.284781 0.915000
The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: __index_level_0__, review. If __index_level_0__, review are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message.
***** Running Evaluation *****
Num examples = 200
Batch size = 4Step 10: Make Predictions for Text Classification
In step 10, we will talk about how to make predictions using the Hugging Face transformer Trainer model.
Passing the tokenized Dataset to the .predict method, we get the predictions for the customized transfer learning sentiment model. We can see that the prediction results contain multiple pieces of information.
Num examples = 200indicates that there are 200 reviews in the testing dataset.Batch size = 4means that 4 reviews are processed each time.- Under
PredictionOutput,predictionshas the logits for each class. logit is the last layer of the neural network before softmax is applied.label_idshas the actual labels. Please note that it is not predicted labels although it is under thePredictionOutput. We need to calculate the predicted labels based on the logit values. - Under
metricsthere is information about the testing predictions.
test_lossis the loss for the testing dataset.test_accuracyis the percentage of correct predictions.test_runtimeis the runtime for testing.test_samples_per_secondis the number of samples the model can process in one second.test_steps_per_secondis the number of steps the model can process in one second.
# Predictions
y_test_predict = trainer.predict(dataset_test)
# Take a look at the predictions
y_test_predictOutput:
***** Running Prediction *****
Num examples = 200
Batch size = 4
PredictionOutput(predictions=array([[-1.6814244 , 1.7357779 ],
[-1.6375449 , 1.728564 ],
[-1.6073432 , 1.5392544 ],
[ 0.61753124, -0.5985209 ],
[ 0.7399963 , -0.51081836],
[-1.3382138 , 1.3751312 ],
.........
[ 0.69749063, -0.61940485]], dtype=float32),
label_ids=array([1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1,
1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1,
.........
0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0,
0, 0]),
metrics={'test_loss': 0.28478118777275085,
'test_accuracy': 0.915,
'test_runtime': 25.4845,
'test_samples_per_second': 7.848,
'test_steps_per_second': 1.962})The predicted logits for the transfer learning text classification model can be extracted using .predictions.
# Predicted logits
y_test_logits = y_test_predict.predictions
# First 5 predicted probabilities
y_test_logits[:5]We can see that the prediction has two columns. The first column is the predicted logit for label 0 and the second column is the predicted logit for label 1. logit values do not sum up to 1.
array([[-1.6814244 , 1.7357779 ],
[-1.6375449 , 1.728564 ],
[-1.6073432 , 1.5392544 ],
[ 0.61753124, -0.5985209 ],
[ 0.7399963 , -0.51081836]], dtype=float32)To get the predicted probabilities, we need to apply softmax on the predicted logit values.
# Predicted probabilities
y_test_probabilities = tf.nn.softmax(y_test_logits)
# First 5 predicted logits
y_test_probabilities[:5]After applying softmax, we can see that the predicted probability for each review sums up to 1.
<tf.Tensor: shape=(5, 2), dtype=float32, numpy=
array([[0.03176216, 0.96823776],
[0.0333716 , 0.9666284 ],
[0.04122555, 0.9587744 ],
[0.771368 , 0.22863196],
[0.77744085, 0.22255914]], dtype=float32)>To get the predicted labels, argmax is used to return the index of the maximum probability for each review, which corresponds to the labels of zeros and ones.
# Predicted labels
y_test_pred_labels = np.argmax(y_test_probabilities, axis=1)
# First 5 predicted probabilities
y_test_pred_labels[:5]Output:
array([1, 1, 1, 0, 0])The actual labels can be extracted using y_test_predict.label_ids.
# Actual labels
y_test_actual_labels = y_test_predict.label_ids
# First 5 predicted probabilities
y_test_actual_labels[:5]Output:
array([1, 1, 1, 0, 0])Step 11: Model Performance Evaluation
In step 11, we will make the transfer learning text classification model performance evaluation.
trainer.evaluate is a quick way to get the loss and the accuracy of the testing dataset.
# Trainer evaluate
trainer.evaluate(dataset_test)We can see that the model has a loss of 0.28 and an accuracy of 91.5%.
***** Running Evaluation *****
Num examples = 200
Batch size = 4
[50/50 00:21]
{'eval_loss': 0.28478118777275085,
'eval_accuracy': 0.915,
'eval_runtime': 23.3302,
'eval_samples_per_second': 8.573,
'eval_steps_per_second': 2.143,
'epoch': 2.0}To calculate more model performance metrics, we can use evaluate.load to load the metrics of interest.
# Load f1 metric
metric_f1 = evaluate.load("f1")
# Compute f1 metric
metric_f1.compute(predictions=y_test_pred_labels, references=y_test_actual_labels)
# Load recall metric
metric_recall = evaluate.load("recall")
# Compute recall metric
metric_recall.compute(predictions=y_test_pred_labels, references=y_test_actual_labels)Output:
{'f1': 0.9109947643979057}
{'recall': 0.8877551020408163}Step 12: Save and Load Model
In step 12, we will talk about how to save the model and reload it for prediction.
tokenizer.save_pretrained saves the tokenizer information to the drive and model.save_model saves the model to the drive.
# Save tokenizer
tokenizer.save_pretrained('./sentiment_transfer_learning_transformer/')
# Save model
trainer.save_model('./sentiment_transfer_learning_transformer/')We can load the saved tokenizer later using AutoTokenizer.from_pretrained() and load the saved model using AutoModelForSequenceClassification.from_pretrained().
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("./sentiment_transfer_learning_transformer/")
# Load model
loaded_model = AutoModelForSequenceClassification.from_pretrained('./sentiment_transfer_learning_transformer/')More tutorials are available on GrabNGoInfo YouTube Channel, GrabNGoInfo.com, and LinkedIn.
Recommended Tutorials
- GrabNGoInfo Machine Learning Tutorials Inventory
- Customized Sentiment Analysis: Transfer Learning Using Tensorflow with Hugging Face
- Sentiment Analysis: Hugging Face Zero-shot Model vs Flair Pre-trained Model
- Zero-shot Topic Modeling with Deep Learning Using Python
- Topic Modeling with Deep Learning Using Python BERTopic
- Google Colab Tutorial for Beginners
- TextBlob vs. VADER for Sentiment Analysis Using Python
- Five Ways To Create Tables In Databricks
- Time Series Anomaly Detection Using Prophet in Python
- Multivariate Time Series Forecasting with Seasonality and Holiday Effect Using Prophet in Python
- Time Series Causal Impact Analysis in Python
- 3 Ways for Multiple Time Series Forecasting Using Prophet in Python
References
- Hugging Face documentation on fine-tuning a pretrained model
- Hugging Face notebook on fine-tuning a pretrained model
- Hugging Face documentation on tokenizer
- Deeplearning.AI transfer learning video from Andrew Ng
- Hugging Face TensorFlow predictions and metrics video
- Hugging Face documentation on prepare_tf_dataset()
- Hugging Face documentation on transformers.Trainer
- Hugging Face documentation on Datasets



