
Solutions to Master-Level Questions in Data Science
This article presents and discusses the solutions to the master-level questions in data science published in this post.
- The correct order for data preprocessing is: a) Feature scaling → imputation → discretization → one-hot encoding b) One-hot encoding → imputation → discretization → feature scaling c) Imputation → one-hot encoding → discretization → feature scaling d) Imputation → discretization → one-hot encoding → feature scaling
The correct answer is (d).
We need to impute the missing values before doing other operations that assume no missing values. One-hot encoding should be done after discretization, because discretization creates new categories that may need to be encoded into numeric values as well. Feature scaling should be performed as the last step after converting all the features to numerical.
Learn more about data preprocessing in this article:
2. Which of the following is an advantage of K-Nearest Neighbors (KNN) over other classifiers? a) Easy to implement b) Fast prediction time c) Can be used both for classification and regression d) Works well with high-dimensional data
The correct answers are (a) and (c).
KNN is very easy to implement (can be written in a few lines of code in Python). It can also be used for classification and regression. For example, in Scikit-Learn there are two classes that implement this algorithm: KNeighborsClassifier and KNeighborsRegressor.
On the other hand, it is slow in prediction since it requires computing the distances between the new sample to all the training samples, i.e., the prediction time is O(nm) where n is the number of training samples and m is the number of features. Most other algorithms have a much lower prediction time.
In addition, KNN doesn’t work well with high-dimensional data as it suffers from the curse of dimensionality phenomena (where the data points become very far from each other when the number of dimension increases).
Learn more about the KNN algorithm in this article:
3. Which of the following statements is true about AdaBoost: a) The prediction of AdaBoost is based on a weighted sum of predictions. b) In every iteration of AdaBoost, the weight of each data point is increased in proportion to the number of weak learners that misclassified it. c) If we train enough weak learners and each learner gets at least 51% accuracy on the training set, then AdaBoost can always achieve 100% accuracy on the training set. d) Increasing the number of weak learners reduces overfitting.
The correct answers are (a) and (c).
(b) is incorrect since the change in weight of a data point is only determined by the most recent learner, not any of the previous learners. (d) is incorrect since adding more weak learners to the ensemble makes the final model more complex and thus can lead to overfitting.
For more information on AdaBoost, see this article:
4. We trained a linear SVM on a binary classification problem and got a weight vector w = (1, 2, 3). We also know that x = (4, 2, 1) is a support vector and is classified by the SVM as -1. What is the value of b in the classification equation of the SVM? a) -12 b) -10 c) 1 d) 0 e) 7
The correct answer is (a).
Every support vector satisfies the equation:
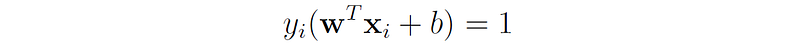
In our case, yᵢ = -1 and
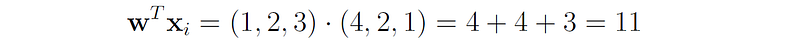
Therefore,
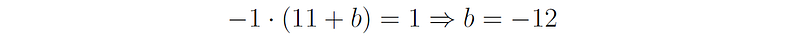
5. You are training a neural network, but the training error is high. Which of the following may reduce the training error? a) Add L2 regularization b) Normalize the input features c) Use early stopping d) Add more hidden layers e) Add momentum
The correct answers are (b) and (d).
Normalizing the input features help gradient descent converge faster to a local optimum, and leads to better performance on the training set.
Adding more hidden layers to the network allows it to capture more complex patterns in the data and therefore leads to better performance on the training set. However, adding too many layers may lead to overfitting.
Adding L2 regularization, early stopping and adding momentum help reduce the generalization error but tend to increase in the training error.
To learn more on neural networks, read my articles on perceptrons, multi-layer perceptrons, and deep learning.
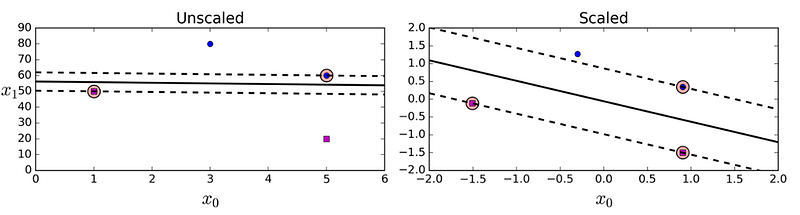
6. Which of the following models is affected by normalizing the input features? a) Linear regression b) Ridge regression c) Decision trees d) Neural networks e) Soft-margin SVMs
The correct answers are (b), (d) and (e).
Linear regression is not affected by data normalization, since it can adjust the size of each coefficient wᵢ to the range of its corresponding feature xᵢ. However, ridge regression is affected by normalization, since we multiply the weights (their squares) by the same regularization coefficient λ, therefore without normalization features with wider ranges will have a larger impact on the regularization.
Neural networks are affected by data normalization, since their training is based on gradient descent, which doesn’t work well when different features have different scales.
SVM is also sensitive to the ranges of the features, since features with larger ranges will have more impact on the margin:
7. Which of the following statements is true about principal component analysis (PCA)? a) The principal components are the right singular vectors of the centered data matrix. b) The principal components are eigenvectors of the sample covariance matrix. c) The i-th principal component is the direction that is orthogonal to the (i-1)-th principal component and maximizes the remaining variance. d) The principal component with the largest eigenvalue maximizes the reconstruction error.
The correct answers are (a) and (b).
The first two answers follow directly from the definitions of PCA. (c) is incorrect because the i-th principal component should be orthogonal to all the first (i-1) principal components. (d) is incorrect because the principal component with the largest eigenvalue captures the maximum amount of variance, which is equivalent to minimum construction error.
8. Given an input image of shape (32, 32, 3), you build a convolutional layer with 8 filters of size 5 × 5 (with biases) with zero padding and a stride of 2. What is the number of trainable parameters in this layer? a) 300 parameters b) 304 parameters c) 600 parameters d) 608 parameters
The correct answer is (d).
The convolutional layer has 8 filters of size 5 × 5, while the input image has 3 channels (RGB). Therefore, each of the 8 feature maps has 5 × 5 × 3 = 75 weights, plus a bias term. This means 76 parameters per feature map. Since we have 8 feature maps, the total number of parameters is 8 × 76 = 608.
9. Which of the following classifiers could have generated the following decision boundary?
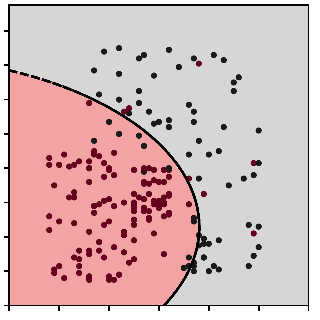
a) Perceptron b) KNN c) Gaussian Naive Bayes d) AdaBoost e) Logistic regression
The correct answer is (c).
The decision boundary depicted in the image has a quadratic (parabolic) shape. The only model from the list above that generates a quadratic decision boundary is Gaussian Naive Bayes. This is because Gaussian Naive Bayes assumes that the distribution of each class is a normal distribution:
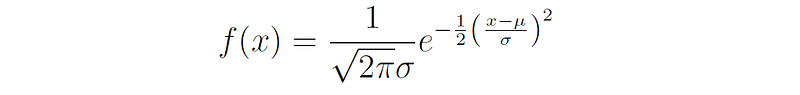
When two normal distributions intersect, the two exponents cancel each other, and we are left with an expression that depends on a quadratic form of x.
10. We want to cluster the following data points into two clusters. Which of the following algorithms would work well?
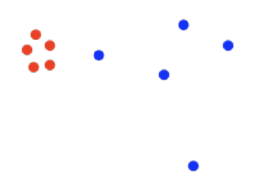
a) K-means b) GMM c) DBSCAN d) Spectral clustering
The correct answer is (b).
(a) K-means assigns each point to its closest centroid, and thus will not be able to correctly assign all the blue dots to their cluster. For example, the leftmost blue dot is closer to the centroid of the red cluster than the centroid of the blue cluster, thus it will be assigned to the red cluster. (b) GMM models the clusters as a mixture of normal distributions with different centers and standard deviations, therefore it can identify correctly the two clusters given in this example by modeling the distribution of the blue cluster as a normal distribution with a larger standard deviation then the red cluster. (c) DBSCAN is a density-based clustering algorithm, therefore it has difficulty in finding clusters with different densities as in this case.
I hope you enjoyed solving these questions.
Feel free to check out my other master-level questions:





