
Master-Level Questions in Data Science
Most of the data science interview preparation questions you can find online are introductory-level questions and do not necessarily resemble the questions you will get in a real job interview.
This article provides you with 10 multiple-choice questions (MCQs) in various topics in data science that are at the same level I expect my graduate students to have at the end of their studies.
Note that there may be more than one correct answer for each question (but there is always at least one correct answer).
- The correct order for data preprocessing is: a) Feature scaling → imputation → discretization → one-hot encoding b) One-hot encoding → imputation → discretization → feature scaling c) Imputation → one-hot encoding → discretization → feature scaling d) Imputation → discretization → one-hot encoding → feature scaling
- Which of the following is an advantage of K-Nearest Neighbors (KNN) over other classifiers? a) Easy to implement b) Fast prediction time c) Can be used both for classification and regression d) Works well with high-dimensional data
- Which of the following statements is true about AdaBoost: a) The prediction of AdaBoost is based on a weighted sum of predictions. b) In every iteration of AdaBoost, the weight of each data point is increased in proportion to the number of weak learners that misclassified it. c) If we train enough weak learners and each learner gets at least 51% accuracy on the training set, then AdaBoost can always achieve 100% accuracy on the training set. d) Increasing the number of weak learners reduces overfitting.
- We trained a linear SVM on a binary classification problem and got a weight vector w = (1, 2, 3). We also know that x = (4, 2, 1) is a support vector and is classified by the SVM as -1. What is the value of b in the classification equation of the SVM? a) -12 b) -10 c) 1 d) 0 e) 7
- You are training a neural network, but the training error is high. Which of the following may reduce the training error? a) Add L2 regularization b) Normalize the input features c) Use early stopping d) Add more hidden layers e) Add momentum
- Which of the following models is affected by normalizing the input features? a) Linear regression b) Ridge regression c) Decision trees d) Neural networks e) Soft-margin SVMs
- Which of the following statements is true about principal component analysis (PCA)? a) The principal components are the right singular vectors of the centered data matrix. b) The principal components are eigenvectors of the sample covariance matrix. c) The i-th principal component is the direction that is orthogonal to the (i-1)-th principal component and maximizes the remaining variance. d) The principal component with the largest eigenvalue maximizes the reconstruction error.
- Given an input image of shape (32, 32, 3), you build a convolutional layer with 8 filters of size 5 × 5 (with biases) with zero padding and a stride of 2. What is the number of trainable parameters in this layer? a) 300 parameters b) 304 parameters c) 600 parameters d) 608 parameters
- Which of the following classifiers could have generated the following decision boundary?
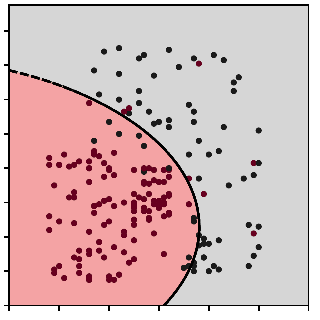
a) Perceptron b) KNN c) Gaussian Naive Bayes d) AdaBoost e) Logistic regression
10. We want to cluster the following data points into two clusters. Which of the following algorithms would work well?
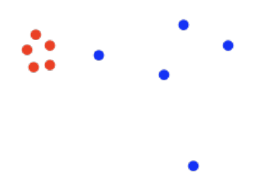
a) K-means b) GMM c) DBSCAN d) Spectral clustering
You can find the solutions to these questions here (try to solve them yourself first!)





