
November 2021- State of the Art: Transformers
Power to the Pixel
DEMO: Turing Bletchley

Turing Bletchley, this model can interpret pictures in a groundbreaking way. Microsoft moves beyond language for AI with the introduction of T-Bletchley, a model that can perform image-language tasks in 94 languages.
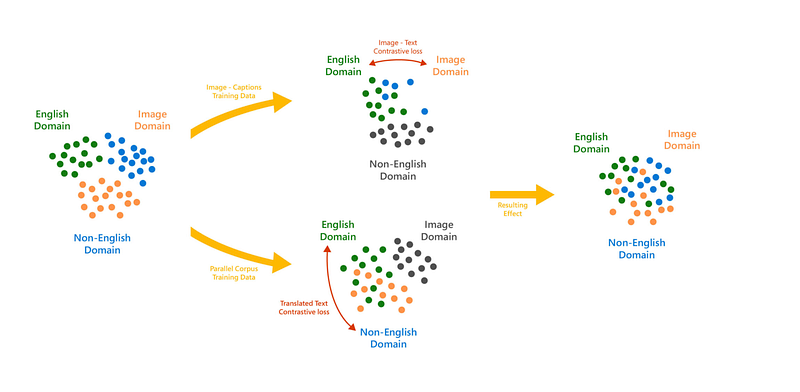
TL;DR The model was trained on billions of publicly available words and images. For this purpose, Data scientists at Microsoft’s Project Turing used a large dataset containing sentences chosen randomly from the web. They built a language-agnostic vector representation for each sentence and then applied a contrastive loss on those vectors. The model was then trained using the ZeRO optimizer and the DeepSpeed library for PyTorch. The final result is a state-of-the-art image understanding model with universal capabilities but significantly better performance than previous architectures.
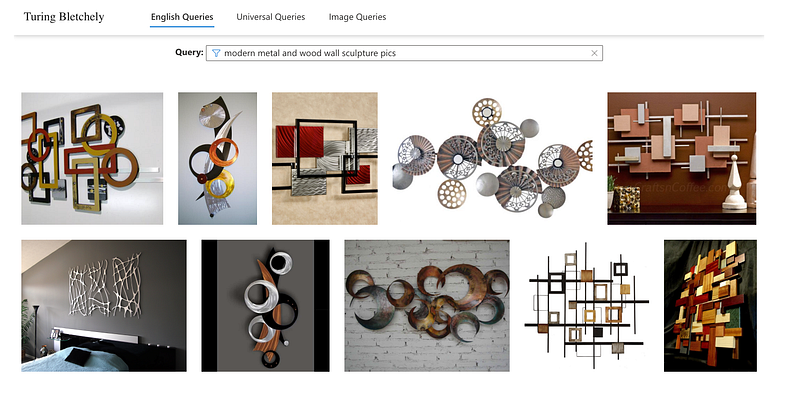
Are there any art exhibitions worthy of a photo coming up? Do you want your memories to last a lifetime? This model has been trained to understand text and images as seamlessly as humans do. The first version of T-Bletchley represents a significant breakthrough in this mission. This latest release from Microsoft is the only one that can handle a wide variety of images effortlessly. T-Bletchley can also be used for image captioning, image translation, and object tagging applications.
T-Bletchley does a remarkable job of encoding images and text into vector representations that map with each other. This allows for semantically similar pictures and texts to align, leading to breakthroughs in image language understanding. An image with text is represented as a vector of parameters, denoting the presence or absence of content in different parts of the picture. This enables the model to quickly encode thousands of other images while maintaining high accuracy. Models need to account for the underlying data in a language-specific process to create a system that can perform better than human experts. This is a top-down approach that requires an understanding of language and complex knowledge representations. In contrast, T-Bletchley works over image analysis and deep learning with less reliance on grammatical rules and experience from experts. This bottom-up approach requires minimal understanding of the grammar and relies more on the computational analysis of visual data.
T-Bletchley brings together two different AI systems: (1) deep learning over images (e.g., image captioning, object recognition) and (2) hierarchical/graph-based probabilistic models for language processing (e.g., neural machine translation, syntactic parsing). T-Bletchley is general purpose and can be applied to a wide variety of tasks. Microsoft’s tool is a component for a bigger picture that considers the various modalities of language and their representation in images instead of or in addition to text. In T-Bletchley, language is extracted from images using a fundamental feature transform from image pixel values to vector elements specifically designed for image-to-language modeling.
OpenAI’s CLIP model has been the gold standard in zero-shot image classification. Still, this latest release from Microsoft is poised to revolutionize Artificial Intelligence because it can understand a wide variety of objects, actions, and many other concepts (dancing, programming, racing) in the real world. Today, image retrieval relies heavily on metadata that comes with images. For example, the text in the caption or link to the photo could be enough to find it in an extensive database. T-Bletchley is unique because it can actually understand this image and place a greater weight on the image itself. Image understanding can improve current retrieval systems to place a greater weight on the image itself. The T-Bletchley model was trained using billions of image-caption pairs drawn from the web. A large, diverse training dataset resulted in a robust model that can handle various images.
Model architecture
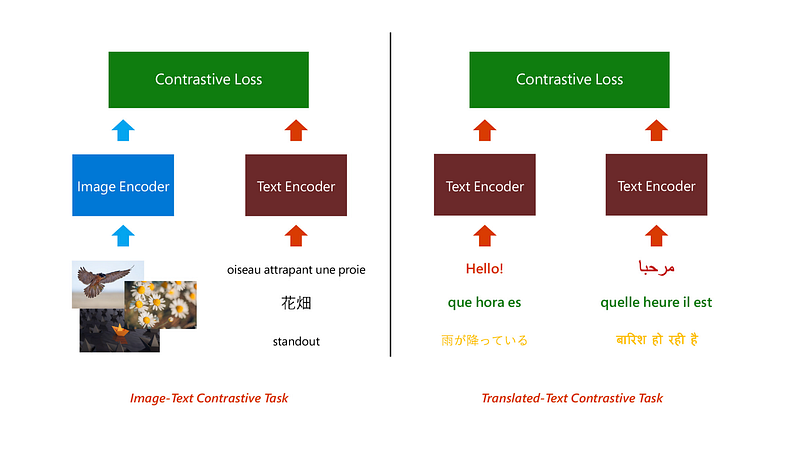
The T-Bletchley architecture is composed of transformers that perform image and text encodings. It’s similar to the BERT architecture in that sense but also includes powerful focus-based interactions between models. Like BERT, T-Bletchley can perceive multiple objects across far apart images. It is also able to see the commonalities between images and captions. Like most modern deep learning models, T-Bletchley can be fine-tuned to learn subtler shifts in image content. For example, the model is sensitive to facial expressions in images and can therefore infer emotions or intent with greater precision than published models.
T-Bletchley models are sensitive to facial expressions in images and can therefore infer emotions or intent with greater precision than published models. AI art depends on this subtlety. If the AI art model can understand and represent the subtlest elements of human behavior and motivation, it can create beautiful and meaningful art. I think we will see an AI art movement with T-Bletchley as its primary model.
AI Artists will be able to explore new creative possibilities beyond human intuition.
The T-Bletchley model was trained with a large, diverse dataset that resulted in a robust system that can handle images from all kinds of the web.
DEMO: https://turing.microsoft.com/bletchley
I’m curious about your opinion
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab





