
Machine Learning Art
Picture Realism like never before paired with a knowledge of words
Imagen, a text-to-image diffusion model. Imagen beats DALL-E 2

Multimodal learning has come into prominence recently. These models have transformed the research community and captured widespread public attention with creative image generation and editing applications.
- May 2022 — AI art tools update can be found ➡️ HERE ⬅️
This article summarizes the fast-growing field of multimodal learning, which is changing the way humans interact with AI art.
Imagen, a photorealistic text-to-image diffusion model with a profound knowledge of the language, is available for the first time ever. When it comes to creating high-fidelity images, Imagen relies on the strength of diffusion models, which are based on colossal transformer language models. There was a surprising discovery: generic large language models (e.g., T5) pretrained on text-only corpora surprisingly effectively encode text for image synthesis. Increasing both sample fidelity and image text alignment significantly more than increasing the size of the image diffusion model.
Project Page (scroll down)
The DALL·E 2 is dead, long live the Imagen!
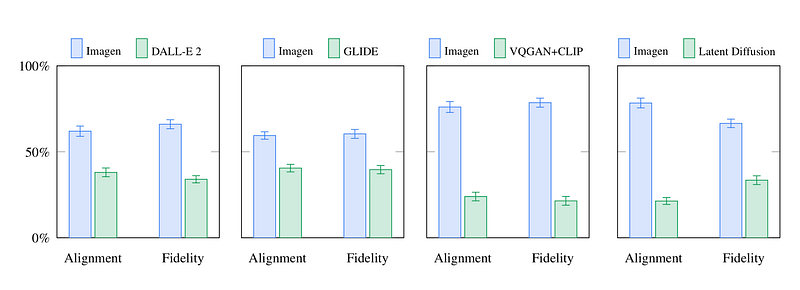
Imagen obtains a new state-of-the-art FID score of 7.27 in the COCO dataset without ever having trained on COCO, and human raters find that Imagen samples are on par with the COCO data itself in image-text alignment. GLIDE, DALL-E 2, and VQ-GAN+CLIP are just a few more modern approaches the authors’ test Imagen against. They find that human raters prefer Imagen in side-byside assessments, both in terms of quality of samples and alignment between images/text.

A comparison of Imagen’s user preference rates for image-text alignment and picture fidelity to those of DALL-E 2, GLIDE, VQ-GAN+CLIP, and Latent Diffusion on DrawBench is shown. (Image Below)
Analysis of the Imagen
Extensive use may be made of increasing the text encoder size. A continuous increase in picture-text alignment and image quality is observed when text encoders are scaled in size. Best results are achieved when trained with our biggest text encoder, T5-XXL (4.6B parameters).
The size of the text encoder should be increased rather than the U-Net. When it comes to sample quality, scaling the diffusion model U-size Net’s improves, but they discovered that scaling the text encoder’s size had a far greater influence.
Dynamic thresholding is essential. When high classifier-free guiding weights are present, dynamic thresholding leads in much greater photorealism and alignment with text than static or no thresholding. On DrawBench, human raters prefer T5-XXL over CLIP because of its larger size. On the COCO validation set, the CLIP and FID scores of models trained with T5-XXL and CLIP text encoders are nearly identical. They have found, however, that in all 11 categories, human raters favor T5-XXL over CLIP.
Enhancement of noise conditioning is essential. Using noise conditioning augmentation to train the super-resolution models results in superior CLIP and FID scores, according to the authors. In addition, we show that noise conditioning augmentation improves CLIP and FID scores at larger guiding weights when applied to the super-resolution model. As a result of adding noise during inference, and using high guiding weights, super-resolution models are able to provide different upsampled outputs while eliminating artifacts from the low-res picture.
The approach used to condition the text is crucial. For both sample fidelity and image-text alignment, conditioning with cross-attention over a succession of text embeddings outperforms simple mean or attention-based pooling. A well-functioning U-Net is a need. Faster convergence, greater sample quality, and a smaller memory footprint are just some of the advantages of their Efficient U-Net implementation.
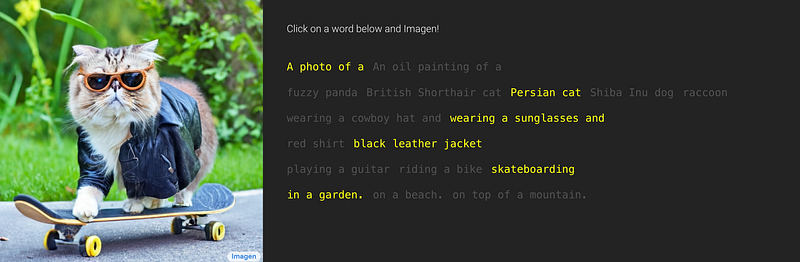
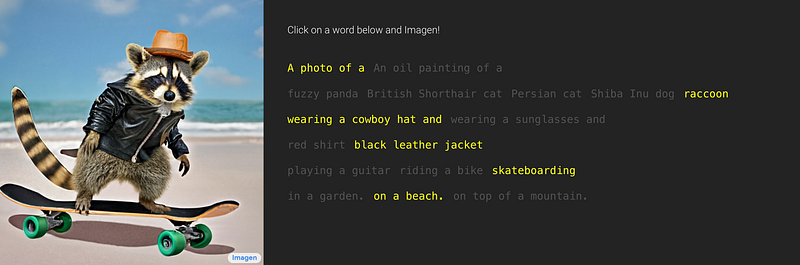
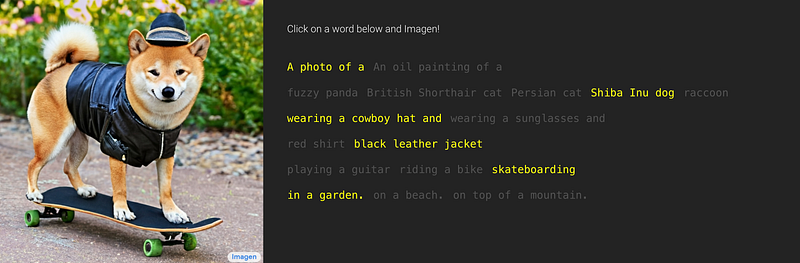
How Machine Learning is Changing the Way Humans Interact With AI art
In recent years, machine learning and neural net research have been increasingly interested in learning from multimodal data. Image-based “things” such as plants or humans are often constituted of numerous components (a head, a body, two limbs) that may necessitate distinct representations. This makes multimodal data increasingly frequent and difficult to interpret.
First and foremost, text-to-image models have a wide range of downstream applications that may have a wide-ranging social influence. Concerns about the possibility of abuse of open-source code and demonstrations have been raised. Second, text-to-image models need vast data, which has encouraged academics to depend extensively on web-scraped data. In recent years, this method has permitted significant algorithmic advancements; nonetheless, datasets of this form frequently represent societal preconceptions, repressive perspectives, and disparaging or otherwise negative linkages with oppressed identity groups of individuals.
As a result, Imagen has the social biases and limitations of big language models in its text encoders. This raises the possibility that Imagen contains damaging stereotypes and representations.
Compared to photos without humans, Imagen had much higher preference rates, suggesting a loss of visual integrity. Representations of persons with lighter skin tones are more likely to appear in Imagen, as is the propensity for images of various occupations to be aligned with Western gender norms. Images generated by Imagen contain a variety of social and cultural prejudices, according to early examination.
Data-Driven Fiction
AI art is often abstract in nature, devoid of a specific function in the world. However, many are still steeped in cultural connotations and prejudices that can be difficult to separate from the art itself. I believe that restricting access to these models is merely an attempt to shed responsibility. It is only a matter of time before we confront the results generated by the model. Synthetic data is our future. Check out Data-Driven Fiction. This topic is widely covered there.
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, digital art, SOTA, Imagen, neural networks, DALL-E 2, GLIDE, VQ-GAN+CLIP, text-to-image diffusion model, photorealistic,
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/evartology
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (11.5K+ ML-professionals)
- Twitter (4.8K+ followers)
- Instagram (2.2K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
Project Page:
https://gweb-research-imagen.appspot.com/
The authors do not release code or a public demo.
AuthorsChitwan Saharia, William Chan, Saurabh Saxena, Lala Li†, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David Fleet†, Mohammad Norouzi
Title: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding





