
Machine Learning Project 13 — Using Kernel Support Vector Machine
In my last post, we covered the Support Vector Machine (SVM) classification algorithm and how it works. Today, we are going to talk about Kernel Support Vector Machine.

#100DaysOfMLCode #100ProjectsInML
The SVM works well in cases when data is linearly separable. Like in the diagram below, it is easy for us to find support vectors and separate the data like we did in Project 12.
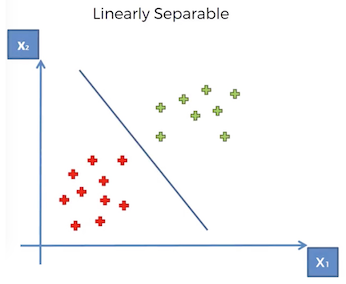
But what if our dataset contains points as shown below. We cannot draw a line to separate the data. No matter which way we draw the line, we cannot separate these points.
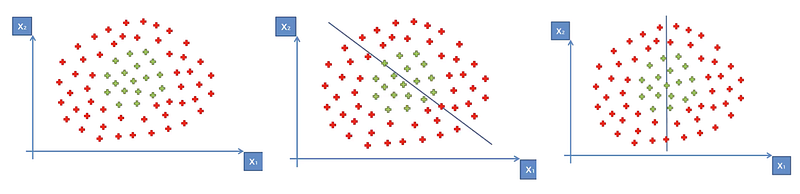
So in above case, we cannot separate the points using standard SVM. This is because the above data is not linearly separable. The SVM algorithm by default makes the assumption that the data is linearly separable. So if our data is not linearly separable like above, the SVM will not work.
Therefore in such cases, we have to use Kernel SVM.
If you recall in Project 12, when we created the object of SVC, we specified kernel as “linear”.
classifier = SVC(kernel = “linear”, random_state=0)Now, let’s look at the different types of kernel’s available that can be used for linear as well as non linear data.
- Gaussian RBF Kernel (Radial Basis Function)
- Sigmoid Kernel
- Polynomial Kernel
For our project, we will be using the Gaussian RBF Kernel and we can compare if we get better results than the “Linear” kernel.
Let’s get started.
Project Objective
We will use the same problem that we used in Project 10. Let’s see if we get a better accuracy with SVM kernel compared to Logistic Regression, KNN and SVM with linear kernel.
We have a dataset that shows which users have purchased an iPhone. Our goal in this project is to predict if the customer will purchase an iPhone or not given their gender, age and salary.
The sample rows are shown below. The full dataset can be accessed here.
Step 1: Load the dataset
From the dataset, we can see that we have 3 independent variables “Gender” , “Age” and “Salary”. All 3 are important and could play a role in prediction. So we will include all 3 and assign them to X.
y will contain the dependent variable “Purchased iPhone”.
Step 2: Convert Gender to Number
Most machine learning algorithm’s cannot handle categorical (text) data. So if our dataset contains and text data — it has to be converted into numbers. In our dataset, we have the Gender variable which is in String format. So we have to convert that to numerical format.
We will use the class LabelEncoder to convert Gender to number.
Here’s a snapshot of our X and y variables.
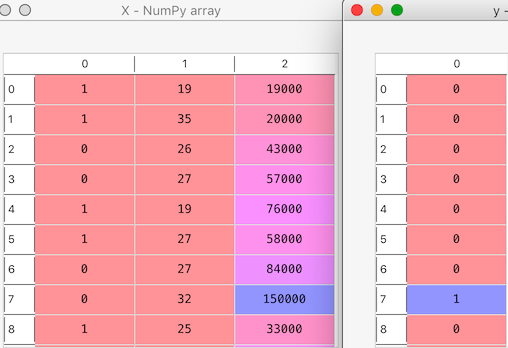
Step 3: Split data into training and test set
We have to split the data for training and testing purpose. We will use 25% of dataset as test sample and 75% as training sample.
Step 4: Feature Scaling
Since the independent variables are of different scale, it’s important to do feature scaling. For example, in our dataset, Gender is either 0 or 1, Age is a 2 digit number and Salary is a 5 digit number. So if we don’t scale, the algorithm might give more weightage to Salary variable as that is much bigger than age. To avoid this, we do feature scaling so all variables are in the same scale.
We will use Standard Scaler for this purpose.
Step 5: Fit SVM Classifier
We will be using the SVC classifier from the sklearn.svm library. When we create an object of the SVC class, we have to pass the kernel parameter. In Project 12, we used linear kernel.
But in this project, we will use rbf kernel — which is the Gaussian Radial Basis Function kernel.
Step 6: Make Predictions
Let’s make some predictions on the test data set.
Step 7: Evaluate Performance of the Model
Let’s check how well our model performed by looking at metrics. This will tell us the number of incorrect predictions, the accuracy score, the precision score and the recall score.
You can read in detail about how these scores are calculated in Project 10.
[[64 4]
[ 3 29]]
Accuracy score: 0.93
Precision score: 0.8787878787878788
Recall score: 0.90625Wow !!! — we have got only 7 (4+3)incorrect predictions and an accuracy score of 93%.
Conclusion
So far we have solved the same problem using Logistic Regression, KNN classifiers and SVM. Today we used Kernel SVM. Let’s compare the results from all classifiers.
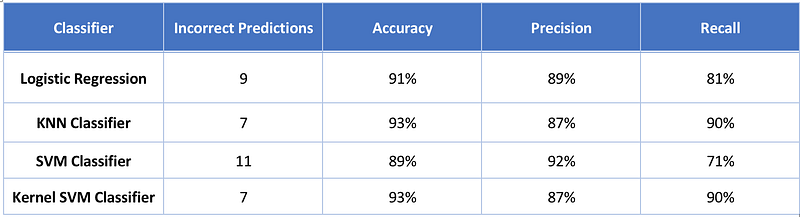
Well the Kernel SVM has performed much better than the linear SVM. But it’s results are almost identical to KNN Classifier.
Hope you are having fun building these classifiers and seeing whose performance is better.
The full source can be found here.




