
Machine Learning Project 10 — Predict which customers bought an iPhone

We have completed 9 projects so far covering different types of Regressions.
#100DaysOfMLCode #100ProjectsInML
Regression involves predicting a continuous output variable or quantity.
Examples of Regression Predictive modeling include:
- Predicting the salary of an employee given his years of experience.
- Predicting the price of a house given the city and number of bedrooms.
- Predicting sales of a business given marketing budget.
Now, there are a different set of problems where we are required to classify the output variables into 2 or more labels or categories. We need to predict the label or category for a given observation.
These are called Classification Predictive modeling. Examples include:
- Marking an email as spam or not.
- Predicting whether a customer will make a purchase or not.
- Predicting whether a person will get diabetes or not.
The above are examples of Binary Classification problems.
We can also have multi label or multi class classification problems. In Multi class problems, the classes are mutually exclusive. The output variable can be classified into any one class. For example, a movie can be categorized as either PG 13 or Adult but not both.
In Multi Label problems, the output variable can be classified under multiple labels. Going back to our movie example, a movie can be classified as “Mystery” and “Romance”. We will discuss these topics in more detail in the future projects.
Let’s start with our first classification problem and we will use Logistic Regression for this. It’s called Logistic Regression because it separates the output into 2 categories by drawing a straight line as shown below
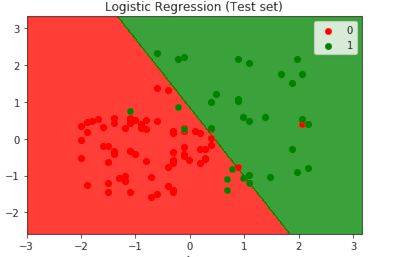
Project Objective
Let’s look at the dataset. To make it interesting, let’s assume these are records of customers who purchased or did not purchase an iPhone. The sample rows are shown below. The full dataset can be accessed here.
Our goal in this project is to predict if the customer will purchase an iPhone or not given their gender, age and salary.
Step 1: Load the dataset
X will contain all 3 independent variables “Gender” , “Age” and “Salary”
y will contain the dependent variable “Purchased iPhone”
Step 2: Convert Gender to Number
For most machine learning algorithms, we have to convert categorical variables to numbers. Here we have the field “Gender” that has to be converted.
We will use the class LabelEncoder to convert Gender to number
Let’s look at our X and y:
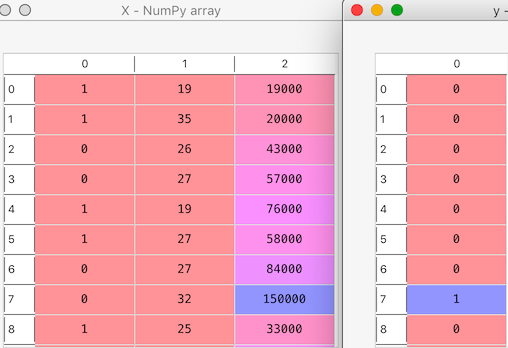
Step 3: Split data into training and test set
Step 4: Feature Scaling
For Logistic Regression algorithm we have to do feature scaling. We will use Standard Scaler for this purpose
Step 5: Fit Logistic Regression
We are going to use the LogisticRegression class from sklearn linear_model library. When we create an object of this class, it takes many parameters. One of them is the “solver” which specifies which Algorithm to use in the optimization problem.
The documentation states:
For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ and ‘saga’ are faster for large ones.
For multiclass problems, only ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ handle multinomial loss; ‘liblinear’ is limited to one-versus-rest schemes.
‘newton-cg’, ‘lbfgs’ and ‘sag’ only handle L2 penalty, whereas ‘liblinear’ and ‘saga’ handle L1 penalty.
Since this is a small dataset, I have chosen “liblinear”
Step 6: Make Predictions
Step 7: Check Accuracy of the Predictions
In classification problems, we can compare the predicted results with the actual results using the confusion matrix.
Confusion Matrix: It will tell us the number of correct and incorrect entries.
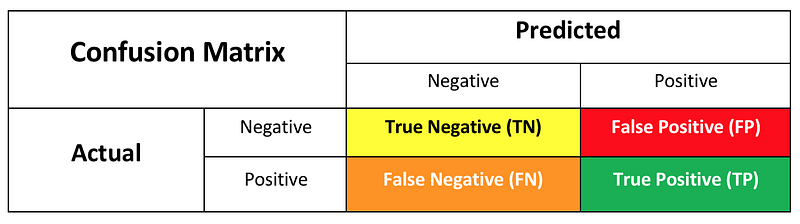
Let’s spend a minute analyzing this matrix. What does this tell us?
- If a person has not bought an iPhone and the predicted value also says they have not bought — it is True Negative (TN) i.e. Actual value is 0and Predicted Value is also 0.
- If a person has not bought an iPhone but the predicted value says they did buy — it is False Positive (FP) i.e. Actual Value is 0 and Predicted Value is 1.
- If a person has bought an iPhone but the predicted value says they did not buy — it is False Negative (FN) i.e. Actual Value is 1 and Predicted Value is 0.
- If a person has bought an iPhone and the predicted value also says they bought — it is True Positive (TP) i.e. Actual value is 1 and Predicted Value is also 1.
Accuracy Score: This is the most common metric that is used for checking the accuracy of the model. It is the percentage of total number of correct predictions by total number of predictions.
Accuracy Score = (TP + TN) / (TP + TN + FP + FN)
Recall Score: It is the percentage of positive events that we predicted correctly.
Recall Score = TP / (TP + FN)
Precision Score: It is the percentage of predicted positive events that are actually positive.
Precision = TP / (TP + FP)
[[65 3]
[ 6 26]]
Accuracy score: 0.91
Precision score: 0.896551724137931
Recall score: 0.8125We got an accuracy score of 91% which is pretty good.
Let’s manually calculate the scores based on the formulas above.
Confusion Matrix
- TN = 65
- FP = 3
- FN = 6
- TP = 26
We can see from the above matrix that we got only 9 incorrect predictions.
Accuracy Score = (TP + TN) / (TP + TN + FP + FN)Accuracy Score =(26 + 65)/ (26 + 65 + 3 + 6)Accuracy Score =91/100 = 0.91 = 91%Recall Score = TP / (TP + FN)Recall Score =26/ (26 + 6)Recall Score =26/32 = 0.8125 = 81.25%Precision = TP / (TP + FP)Precision = 26/ (26 + 3)Precision = 26/29 = 0.8965 = 89.65%Step 8: Make new Predictions
Can you make the following predictions — whether they will purchase iPhone or not?
- Male aged 21 making $40,000
- Male aged 21 making $80,000
- Female aged 21 making $40,000
- Female aged 21 making $80,000
- Male aged 41 making $40,000
- Male aged 41 making $80,000
- Female aged 41 making $40,000
- Female aged 41 making $80,000
Let me know what predictions you get. The full source code is here.
Hope you enjoyed the project — Good Luck



