
Machine Learning Project 12 — Using Support Vector Classification

Today, let’s cover a new type of classification algorithm — “Support Vector Machine (SVM)”. The Math behind that is pretty complex so I will not be getting into that. I will try to explain the concept behind how the SVM classification algorithm works.
#100DaysOfMLCode #100ProjectsInML
I went through many tutorials to understand SVM — but the simplest explanation I found was from the A-Z Machine Learning course on Udemy. So I’ll be using the examples from that tutorial.
Understanding SVM
- Let’s look at the sample dataset below. We have some observations — some are red and some are green. We have already classified these points.
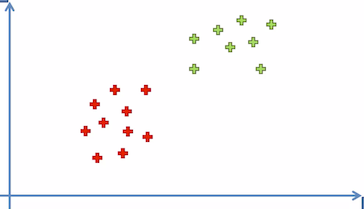
- We will use SVM to separates these 2 categories. Let us assume the line below is drawn by the SVM algorithm to separate the 2 categories and at the same time it has the maximum margin.
- By margin we mean, there will never be any data point inside the margin.
- This line is drawn equal distance from both the red and green points.
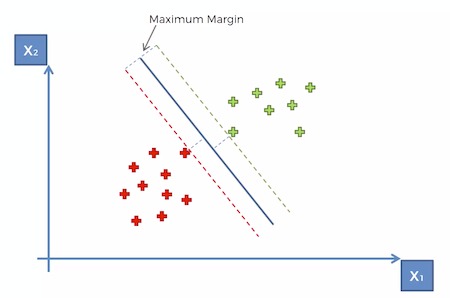
- The 2 points below are called the support vectors. These 2 points are supporting the algorithm — even if you get rid of the other points — nothing will change. The algorithm will be exactly the same. The other points do not contribute to the result of the algorithm. Only these 2 points highlighted contribute and hence are called the support vectors.
- You can call them support points in a 2 dimensional space but in reality they are vectors because in a multidimensional space when you have more than 2 variables — maybe 10 or 50 variables — each point is no longer a point because we cannot visualize it in a two dimensional space and therefore each of those points is actually a vector in a multidimensional space.
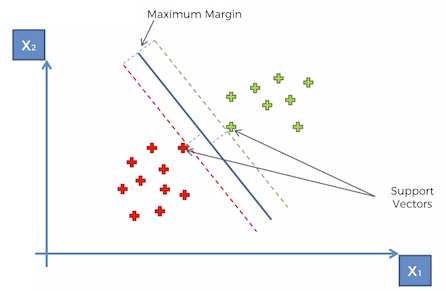
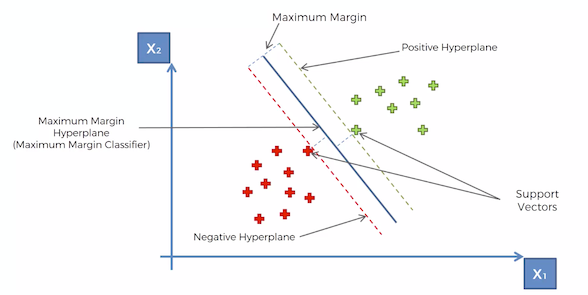
- The line in the middle is called the Maximum Margin Hyperplane in a multidimensional space or Maximum Margin Classifier in a two dimensional space.
- The green dotted line is called the positive hyperplane.
- The red dotted line is called negative hyperplane. It doesn’t matter in which order you name them — its just that one is positive and the other is negative.
What is special about SVMs?
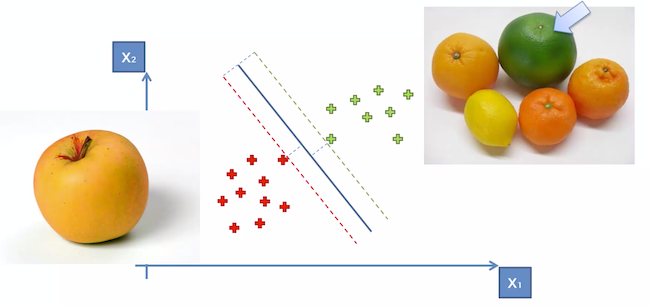
Let’s say you are building an algorithm to identify apple’s and oranges. What most machine learning algorithms would do is they they would look at the most common looking types of apples and most common looking type of oranges to learn and train themselves. So based on that — they will identify new samples as either apple or orange.
But in case of Support Vector Machine — instead of looking at most common types of apples and oranges — the SVM would look at apples that are very much like an orange and similarly oranges that resemble an apple.
If you look at the image below — the SVM would pick the apple on the left that looks very similar to an orange and would pick the the green orange on the right that looks very similar to a green apple. So these 2 points would represent the support vectors and are very close the boundary. So the SVM is a very different type of algorithm as it picks the extreme case which is close to the boundary and it uses that to construct its analysis. That’s why in certain cases, the SVM performs better than other classification algorithms.
Project Objective
We will use the same problem that we used in Project 10. Let’s see if we get a better accuracy with SVM compared to Logistic Regression and KNN.
We have a dataset that shows which users have purchased an iPhone. Our goal in this project is to predict if the customer will purchase an iPhone or not given their gender, age and salary.
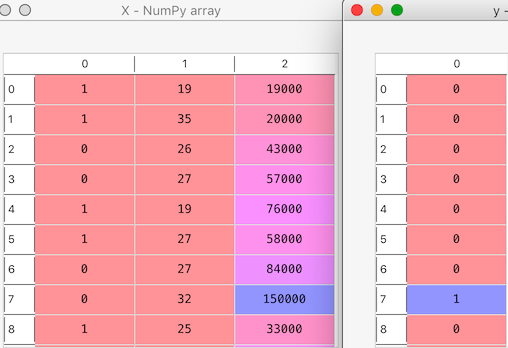
The sample rows are shown below. The full dataset can be accessed here.
Step 1: Load the dataset
X will contain all 3 independent variables “Gender” , “Age” and “Salary”
y will contain the dependent variable “Purchased iPhone”.
Step 2: Convert Gender to Number
In Support Vector Machine algorithm, we need to convert all categorical data to numbers. Here we have a Gender variable that we will convert to numerical format.
We will use the class LabelEncoder to convert Gender to number.
Let’s take a peek at our X and y variables.
Step 3: Split data into training and test set
We will use 25% of dataset as test sample and 75% as training sample.
Step 4: Feature Scaling
Support Vector Machine algorithm also requires us to do feature scaling. We will use Standard Scaler for this purpose.
Step 5: Fit SVM Classifier
In this step we will train the SVM model on the training set. First we have to create an object of the SVC classifier and then call the fit method passing the X_train and y_train.
The SVC class is part of the sklearn.svm library. When creating an object of this class, we have to specify the kernel type to be used in the algorithm. There are several that we can choose from like
- linear
- rbf
- poly
- sigmoid
Since this is a basic SVM that we are building, we will use the linear kernel. We will explore the other types in the upcoming projects.
Step 6: Make Predictions
Let’s make some predictions using the test data set.
Step 7: Check Accuracy of the Predictions
Let’s evaluate our model by examining the confusion matrix. We will also look at the accuracy score, precision score and recall score.
You can read in detail about the confusion matrix in Project 10.
[[66 2]
[ 9 23]]
Accuracy score: 0.89
Precision score: 0.92
Recall score: 0.71875We have got an accuracy of 89% and the SVM model has made 11 (2+9) incorrect predictions.
Conclusion
Let’s compare the results with Logistic Regression and KNN classifiers.
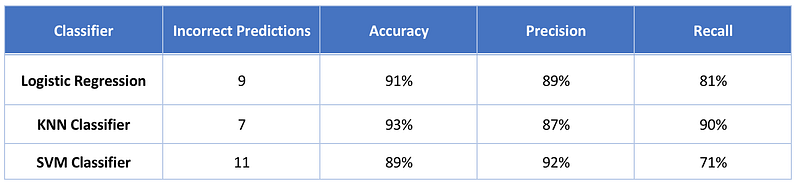
We can see that the SVM classifier has not performed well in this case compared to the other two classifiers that we tried earlier.
You can find the full source code here.




