
How to Split Data in Machine Learning: 5 Simple Strategies and Python Examples
Data splitting isn’t just about using 80% for training and 20% for testing. Explore other important aspects.
Table of Contents
❗This article includes Chapter 4 of the All About Data Preprocessing in Machine Learning collection.
Chapter 4: Data Splitting: The Crucial Divide
- Random Split
- Stratified Split
- Time Series Split
- K-Fold Cross-Validation
- Leave-One-Out Cross-Validation
Introduction
Data Splitting is an important process in machine learning. This involves separating the data set into distinct subsets such as training set, validation set, and test set. This department is essential for training the model, tuning its parameters, and finally evaluating its performance. In this article, we dig into the importance of Data Splitting and explore some simple strategies, along with practical Python code examples to guide you through the process.

1. Random Split
The random split is a commonly used approach that randomly splits a dataset into a training set, validation set, and test set.

- Training Set: A training set is used to train a machine learning model. This is the core data set that the model learns from to understand patterns and relationships in the data.
- Validation set: Validation sets help you fine-tune your model. Tune hyperparameters and prevent overfitting by evaluating model performance during the training phase.
- Test set: The test set provides an unbiased assessment of the model’s performance on unseen data. This is used to evaluate the model’s ability to generalize to new and unknown data.
Below is a simple implementation in Python using the scikit-learn library:
from sklearn.model_selection import train_test_split
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)- This function splits the data into a training set (
X_train,y_train) and a temporary set (X_temp,y_temp), with 20% of the data allocated to the temporary set. - We then further split the temporary set into a validation set (X_val, y_val) and a test set (
X_test,y_test), with each set containing 50% of the data. - The
random_state=42 parameter makes random splits reproducible between different executions of the code. - The resulting dataset enables training, validation, and evaluation of machine learning models, facilitating the development of effective and reliable models.

2. Stratified Split
When a dataset is imbalanced, Stratified Split keeps the class distribution consistent across training, validation, and test sets. Here’s how to implement it in Python:
from sklearn.model_selection import train_test_split
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, stratify=y_temp, random_state=42)Let’s use a simple example to demonstrate stratified partitioning on a sample data set.
The following dataset is intentionally imbalanced to simulate a real-world scenario where one class is significantly more frequent than the other. In this synthetic dataset, 90% of the instances belong to class 0 and only 10% of the instances belong to class 1. This type of imbalance is common in various domains such as fraud detection, physician diagnosis, and anomaly detection. Apply a stratified split to ensure that the class distribution remains consistent across training, validation, and test sets.
import numpy as np
from sklearn.model_selection import train_test_split
# Creating a synthetic imbalanced dataset
np.random.seed(42)
X = np.random.rand(100, 2) # Features
y = np.random.choice([0, 1], 100, p=[0.9, 0.1]) # Imbalanced labels with 90% in class 0 and 10% in class 1
# Stratified split
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, stratify=y_temp, random_state=42)
# Printing the class distributions in the original dataset and the split sets
print("Original Class Distribution:")
print(f"Class 0: {np.sum(y == 0)}, Class 1: {np.sum(y == 1)}\n")
print("Training Set Class Distribution:")
print(f"Class 0: {np.sum(y_train == 0)}, Class 1: {np.sum(y_train == 1)}\n")
print("Validation Set Class Distribution:")
print(f"Class 0: {np.sum(y_val == 0)}, Class 1: {np.sum(y_val == 1)}\n")
print("Test Set Class Distribution:")
print(f"Class 0: {np.sum(y_test == 0)}, Class 1: {np.sum(y_test == 1)}\n")# OUTPUT:
Original Class Distribution:
Class 0: 90, Class 1: 10
Training Set Class Distribution:
Class 0: 63, Class 1: 7
Validation Set Class Distribution:
Class 0: 13, Class 1: 2
Test Set Class Distribution:
Class 0: 14, Class 1: 1You might want to check out my article titled “Credit Card Fraud Detection: A Hands-On Project” where I demonstrate this method of splitting data.
3. Time Series Split
For time-series data, the Time Series Split ensures that temporal order is maintained during Data Splitting.
Time Series Split is a method specifically designed to process time series data. Time series data is a set of observations recorded at different points in time, such as daily stock prices, monthly weather records, or hourly website traffic data. The only challenge with time series data is that the order in which the data points occur is important because the data points often depend on previous observations. In such cases, the Time Series Split is useful. Splitting the dataset into subsets for training, validation, and testing ensures that the temporal order of the data is preserved. How does it work:
- The Time Series Split method uses a specific approach, such as his
TimeSeriesSplitclass fromscikit-learn, to create subsets respecting the chronological order of the data. - Instead of randomizing the data as in traditional random splitting, it splits the data into segments, with each segment representing a different time period. For example, if you have daily data for a year, each segment corresponds to one week or one month.
- This Time Series Split is very important for time series data as it simulates real world scenarios where future predictions can only be made based on what happened in the past.
- By maintaining this temporal order, Time Series Split allows you to train the model using historical data and validate it using more recent data, mimicking the model’s performance in real-world setting.
The following Python code shows how to perform Time Series Split using scikit-learn.
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5)
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]Some related-topics for your reference:
- Gold Price Forecasting
- A Guide to Time Series Models in Machine Learning: Usage, Pros, and Cons
- Time Series in Machine Learning: Understanding and Applications
4. K-Fold Cross-Validation
K-Fold Cross-Validation splits the dataset into ‘k’ folds of equal size, allowing for multiple rounds of training and validation.
K-Fold Cross-Validation is a robust technique used to evaluate the performance and generalization ability of machine learning models. It address the challenge of effectively evaluating model performance with limited data by making the most of available samples.

Math Equation (Image generated by the Author):
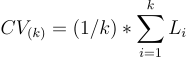
where:
- CV(k) represents the cross-validated performance estimate using k folds.
- Li represents the performance metric (e.g., accuracy, error rate) computed for each fold i.
- The symbol ∑ denotes the summation of the performance metrics across all k folds.
- The fraction (1/k) computes the average of the performance metrics across all k folds.
Here’s how it works:

- The K-Fold Cross-Validation method divides the dataset into ‘
k’ folds or subsets of equal size. Here ‘k’ represents the number of groups or segments into which the data is divided. - Then, perform ‘
k’ iterations using each fold as a validation set and the remaining folds as a training set. This process ensures that each fold is used for validation only once and that the model is trained and evaluated on different subsets of the data. - By performing multiple rounds of training and validation, K-Fold Cross-Validation provides a more reliable and accurate assessment of model performance compared to a single train-test split.
- This technique is particularly advantageous when datasets are limited, as it makes full use of the available data for both training and validation and allows for a more reliable estimate of the model’s predictive ability.
- After ‘
k’ iterations are completed, the evaluation results are averaged to provide a more stable and representative estimate of the model’s performance, thereby reducing the impact of data splitting on the overall evaluation.
A simple implementation in Python is:
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]5. Leave-One-Out Cross-Validation
Leave-One-Out Cross-Validation (LOOCV) is a comprehensive cross-validation method, especially suitable for small datasets. This involves leaving one data point for validation at each iteration.
Math Equation (Image generated by the Author):
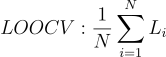
where:
- N denotes the total number of data points in the dataset.
- Li represents the performance metric (e.g., accuracy, error rate) computed for each iteration where one data point is left out for validation.
- The symbol ∑ denotes the summation of the performance metrics across all N iterations.
- The fraction 1/N computes the average of the performance metrics across all iterations, providing an overall evaluation of the model’s performance using the LOOCV method.

Here’s how you can implement it using scikit-learn:
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
for train_index, val_index in loo.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]LOOCV vs. K-Fold Cross-Validation Comparison looks familiar, let’s do some comparison:

Conclusion
Data Splitting serves as the cornerstone for building robust and accurate models. By understanding the various Data Splitting strategies and leveraging their implementations in Python, you can ensure an efficient and effective machine learning workflow. Choose the appropriate data splitting strategy based on your specific dataset and problem, and let it pave the way for successful model development and evaluation.
#MachineLearning #DataSplitting #PythonExamples #DataScience #ModelTraining




