
How Apache Kafka works internally?
Understanding the Inner Workings of Apache Kafka Architecture: Data Storage, Partitioning, Transactions, and Data Integrity
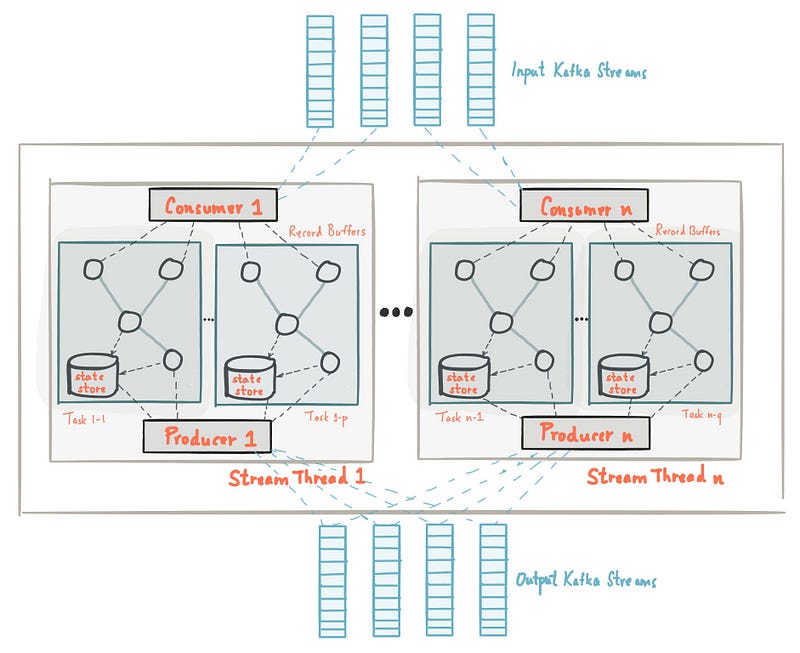
Hello guys, In the realm of distributed systems, Apache Kafka has emerged as a robust and scalable messaging platform. With its ability to handle high volumes of data in real-time, Kafka has become a popular choice for building data pipelines, stream processing applications, and event-driven architectures.
Kafka is also quite important from interview point of view and that’s why I shared difference between Apache Kafka, and RabbitMQ in my last article and in this article, we will delve into the inner workings of Apache Kafka, exploring how it stores data, manages partitions, transactions, and maintains data integrity.
By the way, if you are not a Medium member then I highly recommend you to join Medium and read great stories from great authors from real field without interruptions. You can join Medium here
How Apache Kafka works?
Now, let’s deep dive into Apache Kafka architecture and try to understand how does it work? How it can handle trillions of messages and still ensures data integrity and speed. We will deep dive into how Apache Kafka stores its data, how it manages transaction, how does it work with partitions and most importantly how it ensures data integrity.
1. Data Storage in Apache Kafka
At its core, Apache Kafka is designed to persist and distribute streams of records, known as topics, across a cluster of servers. Kafka stores these records in a distributed, fault-tolerant, and append-only manner.
Instead of relying on a traditional file system, Kafka utilizes its own storage abstraction called “log.” A log is an ordered sequence of records where each record represents a key-value pair, along with additional metadata.
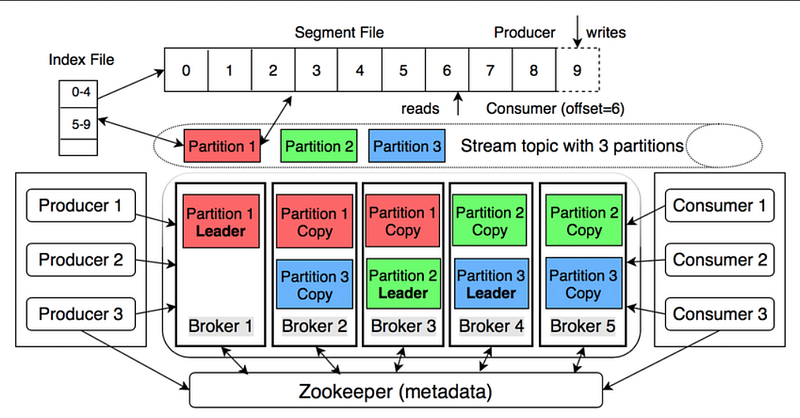
The log is divided into partitions, which are the fundamental unit of parallelism in Kafka. Each partition is an ordered, immutable sequence of records. Kafka ensures that the order of records within a partition is preserved, which allows for sequential processing and ensures data consistency.
2. Partition Management
Partitions play a crucial role in Kafka’s scalability and fault-tolerance. They allow Kafka to distribute the load across multiple brokers and enable data parallelism. When a topic is created, the user specifies the number of partitions, which determines the level of parallelism for consuming and producing data.
Each partition is hosted by a single broker within the Kafka cluster. The broker acts as the leader for that partition and handles all read and write requests for that partition.
Additionally, Kafka replicates each partition across multiple brokers to provide fault-tolerance. These replicas, known as followers, passively replicate data from the leader and can take over as the leader if the current leader fails.
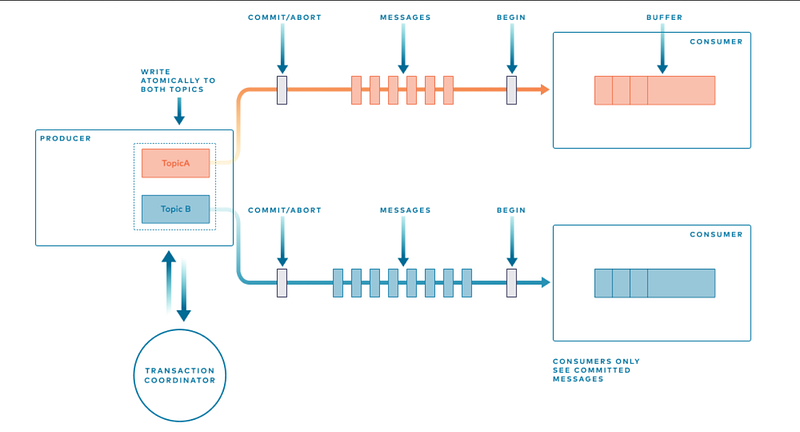
3. Transactions in Kafka
Apache Kafka introduced transactional support in version 0.11, providing atomicity and isolation guarantees for groups of records. Transactions allow producers to write multiple records to multiple partitions atomically, ensuring that either all the records are written successfully, or none of them are.
This is particularly useful when maintaining data integrity across different systems or when processing events with dependencies.
To enable transactions, Kafka uses a combination of a transaction log and transaction markers within the log. Producers interact with the transaction coordinator to initiate and commit transactions.
The transaction coordinator assigns transactional IDs to producers and ensures that the transactional guarantees are maintained.
4. Data Integrity
Data integrity is a critical aspect of any messaging system, and Kafka employs various mechanisms to ensure the reliability of data. Firstly, Kafka replicates data across multiple brokers to provide fault-tolerance. This replication factor can be configured to tolerate a specific number of broker failures.
Additionally, Kafka allows producers to specify the durability level for each record. Producers can choose to write records with different durability requirements, ranging from writing to disk on the leader broker to replicating to multiple followers.
By configuring durability levels, Kafka enables developers to make trade-offs between performance and data safety based on their specific use cases. In Confluent, more than 8 trillion message are audited daily which means it ensures data integrity issues on well over 8 trillion Kafka messages per day in Confluent Cloud.
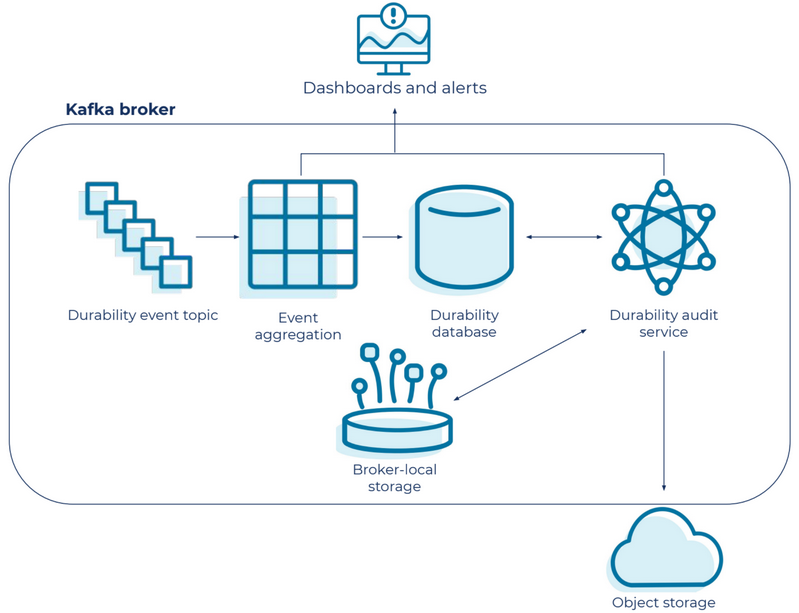
Conclusion
That’s all about how Apache Kafka works internally. Apache Kafka’s architecture and design make it a powerful and reliable messaging platform for handling real-time data streams.
By understanding how Kafka stores data, manages partitions, handles transactions, and maintains data integrity, developers can leverage its capabilities effectively.
Whether it’s building scalable data pipelines or developing event-driven applications, Apache Kafka provides a robust foundation for managing and processing streams of data in distributed environments.
Kafka is also very important topic for interviews. If you are preparing for interviews then you can also prepare questions like difference between API Gateway and Load Balancer, SAGA Pattern, how to manage transactions in Microservices, and difference between SAGA and CQRS Pattern, they are quite popular on interviews.
And, if you are not a Medium member then I highly recommend you to join Medium and read great stories from great authors from real field. You can join Medium here





