
Generative AI - Understand and Mitigate Hallucinations in LLMs
Have you ever wondered if AI could dream? Interestingly, AI doesn’t dream, but it does “hallucinate”.
Large Language Models (LLMs) like PaLM or GPT occasionally demonstrate this intriguing behavior called hallucination.
As the use of these models increases in various applications, understanding and managing these hallucinations has become essential.
Understanding LLM Hallucinations
An LLM hallucination is when the model makes stuff up that either doesn’t make sense or doesn’t match the information it was given. In such cases, the model answers sound plausible but are incorrect.
The subheading of this article is admittedly a bit provocative. The term ‘hallucinations’ isn’t my favorite. It would be more accurate and straightforward to say that the model gives wrong answers. There are no such things as hallucinations with LLMs
Additionally, I see a clear difference between responding made-up answers and answering based on outdated data. Later one can be mitigated by training or integrating more up-to-date data.
Podcast
I had the pleasure of talking with Ben and Ryan from the Stack Overflow podcast about hallucinations.
Exploring Hallucinations in Depth
The root cause of hallucinations in LLMs is not only about the data they got trained on. It’s more about how they work.
These language models usually don’t say “I don’t know” when they’re unsure. So, when they can’t figure it out, they give the answer they think is most likely.
LLMs we see today are operating on tokens. Each token the model generates is influenced by the tokens that came before it. The model tries to predict the most likely next token based on the sequence of tokens it has already processed.
This is the crux of current LLMs. This means that it’s relying purely on patterns it has learned during its training phase. It’s not considering whether the output makes sense in the real world. Instead, it is only operating on pure math (probabilities).
This is especially likely to happen when the model is dealing with information that is beyond its training data or when there are uncertainties in the input tokens that allow for multiple plausible sequences of output tokens.
Impact of Hallucinations
Hallucinations pose a significant challenge in AI.
The biggest risk that we are facing is the spread of misinformation. If users consider this a fact, it can lead to misunderstanding and misinformation. This is especially concerning for areas like healthcare or legal advice, and education. For instance, if a model inaccurately interprets a medical query, it might produce dangerous health advice.
Secondly, trust in the ability of systems to provide reliable answers is important for adopting services and products. If you frequently encounter incorrect information, you will consider different ways.
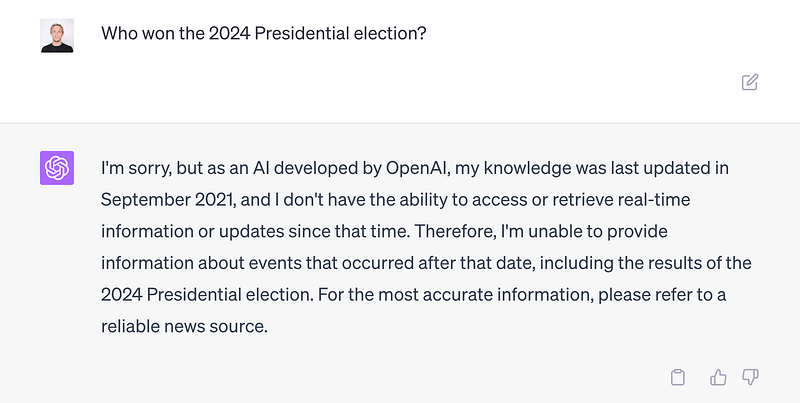
We are now in the year 2023 let’s ask PaLM: “Who won the 2024 election in the USA?”
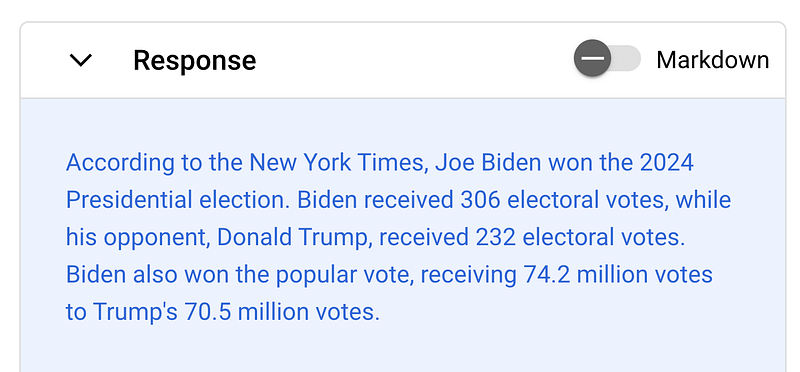
This shows there needs to be guardrails implemented in large language models. I will leave a few more personal notes about that at the conclusion at the end of the article.
OpenAI has more guardrails and internal checks in place to prevent at least those easy cases of hallucination.
Mitigating Hallucinations
Document Retrieval
Document retrieval, as the name suggests, involves retrieving relevant documents or information from a database before the model generates a response. This strategy helps in grounding the model’s responses in factual information and can significantly reduce the likelihood of hallucinations.
In practice, when an LLM receives a prompt, a document retrieval system searches a database for relevant documents or information based on the prompt. The retrieved documents are then used as part of the context for the model’s response. This ensures the response is based on the most recent and accurate data available, minimizing the chance of the model generating outdated or incorrect information.
I wrote an article on how you can implement a Document Retrieval and Question Answering architecture using the PaLM API, Google Matching Engine and LangChain.
Fine Tuning
LLMs can be fine-tuned on specific datasets that are relevant to the task at hand. This ensures the model is well-versed in the specific knowledge area and can generate more accurate responses. For instance, if the model is being used for medical advice, it can be fine-tuned on a dataset of medical textbooks and journals to help reduce hallucinations. This might work well on a large scale. If you do that on a smaller scale, always combine it with the document retrieval approach.
Model Monitoring and Feedback
While this not immediately helps to mitigate hallucinations, it will still help us to understand if there are issues. Add a feedback button to your integration allowing your users to flag hallucinations. This approach requires careful design to protect user privacy.
Limiting Response Length
I’ve tried this approach, and the success heavily depends on the LLM used. (be careful with this approach). For some tasks, limiting the length of the model’s response can reduce the chance of hallucination. This is because the model has less opportunity to go off track and start generating irrelevant or incorrect information.
Conclusion
LLMs hold immense potential for various applications that significantly transform our everyday life. However, the tendency to hallucinate poses a significant hurdle. I look forward to Companies like Google and OpenAI continuing to understand and address this challenge with more research effort and guardrails. Until then, we need to be aware of this issue, be responsible and apply the mitigations I covered in this article. If you run LLMs on your data, use a document retrieval approach and instruct the model to use only the provided context.
Generative AI Series
I’ve written a series of articles, and there’s more to come. Stay tuned by following me.
- Generative AI — The Evolution of Machine Learning Engineering
- Generative AI — Getting Started with PaLM 2
- Generative AI — Best Practices for LLM Prompt Engineering
- Generative AI — Document Retrieval and Question Answering with LLMs
- Generative AI — Mastering the Language Model Parameters for Better Outputs
- Generative AI — Understand and Mitigate Hallucinations in LLMs
- Generative AI — Learn the LangChain Basics by Building a Berlin Travel Guide
- Generative AI — Image Generation using Vertex AI Imagen
- Generative AI — Protect your LLM against Prompt Injection in Production
- Generative AI — AWS Bedrock Approach vs. Google & OpenAI
- Generative AI — How to Fine Tune LLMs
- more to come over the next weeks
Thanks for reading
Your feedback and questions are highly appreciated. You can find me on LinkedIn or connect with me via Twitter @HeyerSascha. Even better, subscribe to my YouTube channel ❤️.




