
Generative AI - Mastering the Language Model Parameters for Better Outputs
Parameters in large language models are crucial because they help control the model's behavior.
PaLM 2 and GPT provide parameters for temperature, token limit, top-k, and top-p. This Article explains those parameters with everyday language and relatable examples.
Before we dive into the parameters, it's crucial to understand the concept of tokens.
The Language of Tokens
In the world of large language models, a token can be as short as one character or as long as one word, depending on the language and the specific word. For instance, in English, a is one token, apple is another, and apples is yet another.
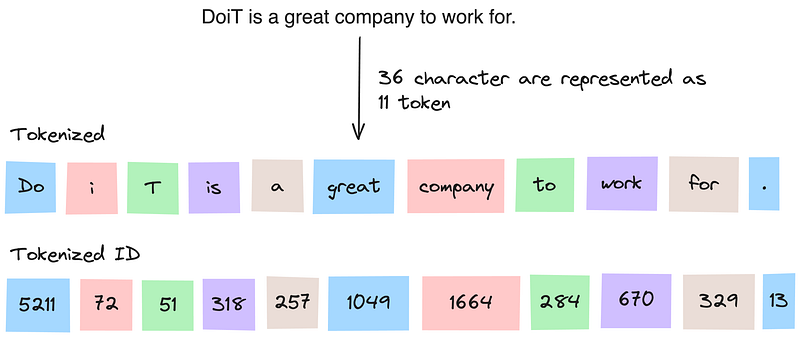
When you give a prompt to the model, it doesn't read the whole sentence at once. Instead, it breaks down your input into these tokens. It then analyzes the tokens, understands their sequence, and uses this understanding to generate a response.
The model also uses tokens not only as input but also as output to generate responses. It doesn't write whole sentences at once. It generates one token at a time based on the previous token and the input token it has read.
What are these parameters?
Before we dive into each parameter, let's start with a simple analogy. Picture the process of generating text as if the model were a chef cooking up a meal from a recipe.
The recipe is your prompt (the text input you give to the model), and the parameters are like the spices and cooking techniques the chef uses to create the final dish. Each parameter will add a different flavor or texture to the dish, and adjusting these parameters will change the meal's outcome.
Temperature
Imagine you're baking a cake. You know that the temperature of your oven will affect how your cake turns out. Too high, and your cake might burn. Too low, and it might not cook properly. In the world of language models, the temperature parameter plays a similar role.
The temperature parameter influences the randomness of the model's responses. A high temperature (closer to 1) makes the model's output more diverse and creative but also more unpredictable.
For example, consider a scenario where you're using PaLM 2 or GPT to generate dialogue for an NPC in a game. You want the dialogue to be unpredictable, colorful, and full of surprises to keep the audience engaged. In this case, you could set the temperature to a high value, say 1.0.
Contrarily, a lower temperature (closer to 0) makes the model's output more deterministic and focused but possibly less creative. It's like lowering the heat — you'll likely get a reliable result, but it might lack some originality.
For example, imagine you want to create a list of frequently asked questions (FAQs) for a website. A lower temperature setting can help keep the answers concise, clear, and directly relevant to the questions.
- Temperature
0.1(more deterministic): "Our return policy allows customers to return items within 30 days of purchase. Items must be in their original condition and packaging. Please contact our customer service for further assistance." - Temperature
0.5(balance of unpredictability and coherence): "We're committed to ensuring your satisfaction. Our return policy gives you 30 days to return an item, as long as it's in its original condition and packaging. If you need to make a return, just contact our customer service team — they're here to help!" - Temperature
1.0(more diverse, potentially less relevant): "In the realm of commerce, we believe in flexibility and customer satisfaction. Thus, we provide a 30-day window from the date of purchase for returns. The merchandise should be untouched, nestled in its original packaging. For guidance through the return process, our customer service team stands ready to navigate you through the sea of commerce."
Token Limit
In language models, as we discussed at the beginning of the article, the term token refers to a chunk of text, which could be as small as one character or as large as one word. The token limit parameter determines how much text the model can process or generate at a time.
Think of it as the size of the mixing bowl you use when baking. A larger bowl allows you to mix more ingredients at once, while a smaller one limits the quantity you can handle. Similarly, a larger token limit lets the model handle longer pieces of text, while a smaller limit restricts it to shorter texts.
Top-k
When generating text, a language model considers many possible words to follow the current one. Top-k sampling is a method that restricts the model's next-word choices to the k-most most likely options.
Imagine a chef who wants to create a new recipe. They have a kitchen full of different ingredients.
Let us assume the chef sets top-k k to 10. The chef will first consider the 10 ingredients that, based on their culinary experience, are most likely to create a tasty soup. From these 10 ingredients, the chef will randomly select a few to include in the recipe.
A smaller k-parameter value will make the text more predictable, while a larger value will make it more diverse.
Top-p
Imagine the chef is now planning a special dinner menu and wants to include a variety of dishes. However, they want to ensure the menu is balanced and doesn't heavily favor one type of cuisine.
In this scenario, the chef decides to use a top-p strategy (the p here stands for probability).
Let's say the chef sets top-p to 0.9 (90% probability). This means the chef will consider all the dishes they could cook, rank them by the likelihood of pleasing their guests (based on their knowledge and experience), and then add dishes from the top of this ranked list to the menu until the cumulative probability reaches 90%.
For example, if the chef's specialty is Italian food, the top of the ranked list might be filled with Italian dishes. However, to reach the cumulative probability of 90%, the chef might need to include dishes from French, Spanish, or other cuisines, ensuring a variety in the menu.
In the context of a language model, the top-p parameter controls the diversity of the output. The model ranks all possible next words by their likelihood and keeps considering words until the total probability reaches the top-p value. This means that, instead of just looking at the top few most likely words, the model could also consider less likely words if they collectively reach the top-p probability, leading to a more diverse output.
Conclusion
In conclusion, these parameters: temperature, token limit, top-k, and top-p play key roles in guiding the behavior of large language models. By adjusting these parameters, we can influence the model's creativity, the length of its responses, and its choice of words. However, like all tools, these parameters require practice and experimentation to master.
Generative AI Series
I've written a series of articles, and there's more to come. Stay tuned by following me.
- Generative AI — The Evolution of Machine Learning Engineering
- Generative AI — Getting Started with PaLM 2
- Generative AI — Best Practices for LLM Prompt Engineering
- Generative AI — Document Retrieval and Question Answering with LLMs
- Generative AI — Mastering the Language Model Parameters for Better Outputs
- Generative AI — Understand and Mitigate Hallucinations in LLMs
- Generative AI — Learn the LangChain Basics by Building a Berlin Travel Guide
- Generative AI — Image Generation using Vertex AI Imagen
- Generative AI — Protect your LLM against Prompt Injection in Production
- Generative AI — AWS Bedrock Approach vs. Google & OpenAI
- Generative AI — How to Fine Tune LLMs
- more to come over the next weeks
Thanks for reading
Your feedback and questions are highly appreciated. You can find me on LinkedIn or connect with me via Twitter @HeyerSascha. Even better, subscribe to my YouTube channel ❤️.





