
New 3D generation method — 2×faster
From 3DS max to 3D AI Designer
Diffusion models for 3D generation and inpainting
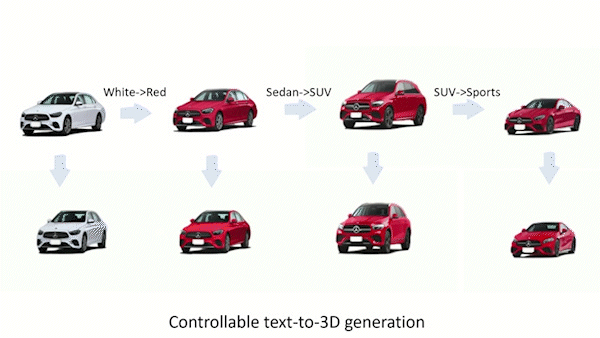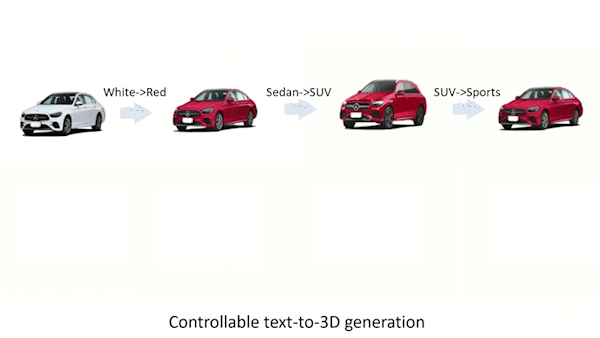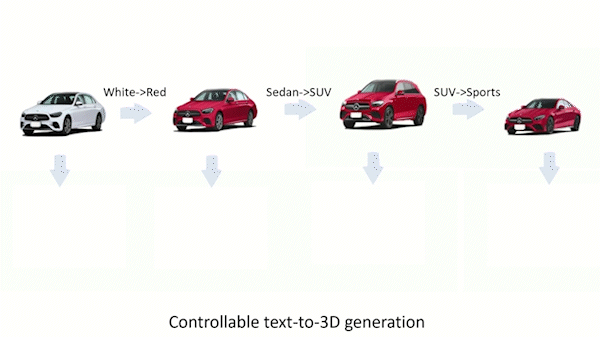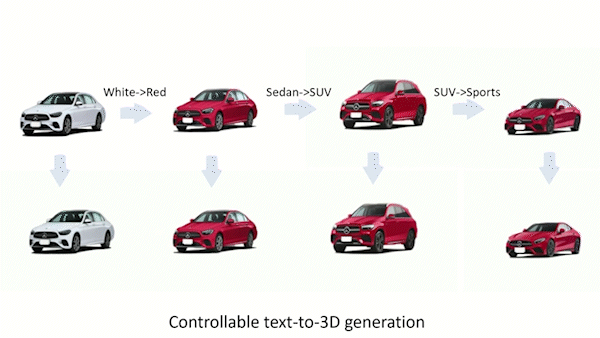
What kind of work is done in 3D modeling?
Artists create 3D models. They work in film and video production studios, game design, graphic and advertising, web design, software, architecture, product design, or manufacturing. 3D AI Designer is the first text-guided generative model to conduct 3D generation, 3D editing / inpainting , and one-shot view synthesis.
Next step in text-to-3D
3D inpainting
Text-guided diffusion models are better at making and editing images and videos. Even though there have been few 3D explorations. In this work, the researchers talk about three important and interesting issues on this subject.
First, they use text-guided diffusion models to ensure that the generation is consistent in 3D. In particular, they combine a neural field like NeRF to make low-resolution, rough results for a given camera view. These results can give 3D priors as conditions for the next diffusion process. During denoising diffusion, they improve the 3D consistency even more by modeling cross-view correspondences with a new two-stream (each stream represents a different view) asynchronous diffusion process. This makes the 3D more consistent.
Second, they look at 3D local editing and propose a two-step solution that can change an object from a single view in a way that changes it in all directions. In the first step, they plan to do 2D local editing by mixing the predicted noises. Step 2: they do a process called “noise-to-text inversion,” which maps 2D blended noises into the space for text embedding that doesn’t depend on the view. As soon as the right text embedding is found, 360-degree images can be made.
Last but not least, they extend the model to do one-shot novel view synthesis by fine-tuning a single image. They do this to first show how text guidance can be used for novel view synthesis.
Can an AI create a model in three dimensions?
Text-guided 3D-consistent generation framework (training phase).
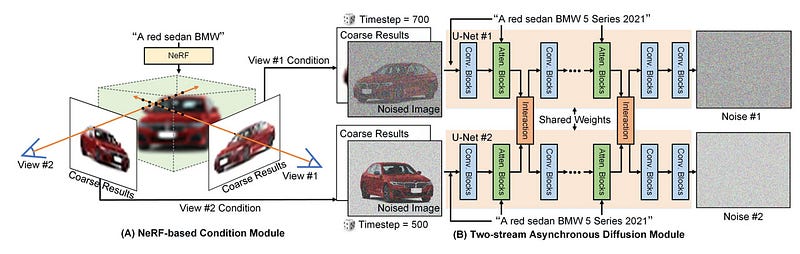
(A) NeRF-based Condition Module that takes one low-resolution text and two low-resolution camera views as inputs and makes low-resolution coarse results. The coarse results are shrunk and added to images with noise to set up conditions for denoising. (B) Two-stream Asynchronous Diffusion Module takes one full text, two coarse results, two timesteps, and two noisy images as inputs and predicts the added noises. Except for the feature interaction module after each attention block, each stream is a plain text-driven diffusion model. The timesteps are chosen randomly, and the parameters of these two streams are the same.
A picture of how 3D local editing / inpainting works.
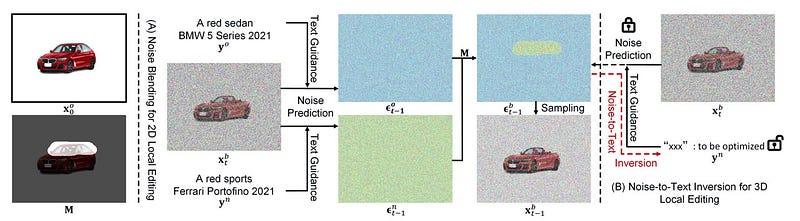
The researchers mix noises at each step of sampling to do 2D local editing and do a noise-to-text inversion to make 3D images that have been changed.
3DDesigner is better than other methods because it uses the proposed NeRF-based Condition Module, Two-stream Asynchronous Diffusion Module, and new diffusion training, sampling, and blending strategies. As a result, it can make highly realistic, detailed, and controlled 3D objects.
Unfortunately, the researchers have not published the code, I suggest to use a similar tool now for free and immediately — HERE
AI is everywhere, But the question is, how much do you love it?
I invite you to explore the concept of Machine Learning Art by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, wombo dream, digital art, Dalle 2, Imagen, wombo ai, Parti, 3D point cloud, diffusion models, generative art, wombo art, photographic quality, img by AI system, AI art generator, text to art generator, 3D, midjourney, dalle2, stablediffusion, 3D AI designer

PROJECT PAGE:
https://arxiv.org/pdf/2211.14108.pdf
TITLE: Towards Photorealistic 3D Object Generation and Editing with Text-guided Diffusion Models
AUTHORS :Gang Li, Heliang Zheng, Chaoyue Wang, Chang Li, Changwen Zheng, Dacheng Tao.





