
Next step in text-to-3D
A novel model that learns 3D from a single photo
The power of combining several new improvements

3D digital content is being used in gaming, entertainment, architecture, and robotics. Shopping, Internet conferencing, social networking, education, etc., are all affected. High-quality 3D requires creative, artistic, and modeling skills. This involves a lot of work.
It’s time for a new model to recreate the 3D shape of a deformable object from a single image.
Next step in text-to-3D
Training 3D models using just single-view input photos
The authors use recent advancements in unsupervised representation learning, unsupervised picture matching, efficient implicit-explicit shape representations, and neural rendering to create a novel auto-encoder architecture that reconstructs 3D form, articulation, and texture from a single test image.
Learning Articulated 3D Animals in the Wild : MagicPony
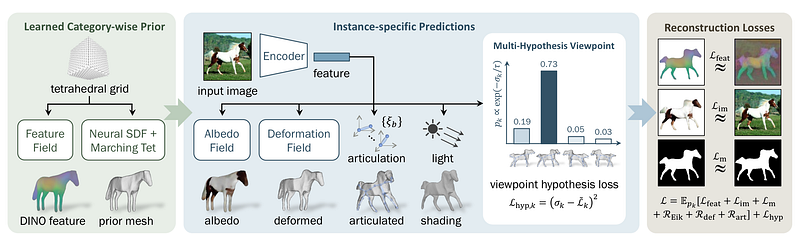
For training, researchers need a 2D object segmenter and 3D skeleton topology and symmetry. They don’t need previous knowledge of 3D form models, key points, views, or other 2D or 3D cues. The researchers develop a feed-forward function that can predict the form and texture of a new item from a single photograph. The function can rebuild things in abstract drawings despite being educated on actual photos.
Can one picture be used to make a 3D model?
The authors outline a few main difficulties and provide novel solutions for each. First, estimate perspectives. With a 3D model, it’s possible to allocate raw 2D photos of a specific item type to multiple aspects or views. Prior research has demonstrated that 2D point correspondences between pictures may simplify this effort. To avoid keypoint supervision, they fuse 3D model information from DINO-ViT, a self-supervised visual transformer network, into plausible but noisy correspondences (ViT).
The authors offer a novel efficient disambiguation approach that investigates numerous perspective assignment hypotheses for free, avoiding local optima generated by greedily matching noisy 2D correspondences.
Second, depict the object’s 3D shape, look, and deformations. Most past attempts employed textured meshes, but they’re tough to optimize from the start, requiring ad-hoc heuristics like re-meshing. Instead, use a volumetric representation such as a neural radiance field.
These representations may simulate complicated structures that change topology during training. Over-parameterization is a concern in monocular reconstruction and frequently leads to nonsensical shortcuts. Volumetric modeling of articulation is challenging.
Deformations are only specified for an object’s surface, interior, and canonical/pose-free to posed space. Ray marching implies extending these non-physical changes around the object and inverting them.
Briefly summarize
🟠 A new 3D object learning framework that combines recent advances in unsupervised learning, 3D representations, and neural rendering to get better reconstruction results with less supervision; 🟠 An effective method for fusing self-supervised features from DINO-ViT into the 3D model as a form of self-supervision; 🟠 An efficient multi-hypothesis viewpoint prediction scheme that avoids local optima in reconstruction at no extra cost; 🟠 The method works for abstract drawings.
New 3D generation method — 2×faster
Unfortunately, the code was not published by the authors. So, I’d like to suggest an available method that is just as interesting and only needs text. Use text to try the SOTA 3D method now.
AI is everywhere, But the question is, how much do you love it?
I invite you to explore the concept of Machine Learning Art by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, wombo dream, digital art, Dalle 2, Imagen, wombo ai, Parti, 3D point cloud, diffusion models, generative art, wombo art, photographic quality, img by AI system, AI art generator, text to art generator, 3D, midjourney, dalle2, stablediffusion,

Project Page:
https://arxiv.org/pdf/2211.12497.pdf
@article{wu2022magicpony,
author = {Shangzhe Wu and Ruining Li and Tomas Jakab and Christian Rupprecht and Andrea Vedaldi},
title = {{MagicPony}: Learning Articulated 3D Animals in the Wild},
journal = {arXiv preprint arXiv:2211.12497},
year = {2022}
}




