
Machine Learning Art
Finetuning is All You Need
Diffusion models — image-to-image

Since network finetuning in NLP (GPT3) has been successful, it’s time to finetune image-to-image translation.
- May 2022 — AI art tools update can be found ➡️ HERE ⬅️
Many content production projects include transforming a simple sketch into a photorealistic picture. image-to-image translation involves learning the conditional distribution of natural pictures given input using deep generative models. Over the years, we’ve seen many task-specific approaches that advance state of the art yet present solutions struggle to create high-fidelity pictures for practical use.
Project Page (scroll down)

The basic concept is to utilize a pre-trained neural network to capture the natural picture manifold. Image translation is similar to traversing this manifold and locating the viable input semantic point. The synthesis network should be pretrained using many pictures to provide credible output from any sampling from its latent space. With a pretrained synthesis network, downstream training adjusts user input to the model’s latent representation. Unlike previous research that sacrificed picture quality to fit a semantic pattern, the proposed framework assures translation quality since the created samples sit on the natural image manifold.
The GAN is dead, long live the Diffusion Model!
Instead of GANs, which perform best for specific domains, the authors utilize the diffusion model, synthesizing a broad diversity of pictures. Second, it should produce pictures from two types of latent codes: one describes visual semantics, and the other adjusts for image fluctuations. A semantic, low-dimensional latent is crucial for downstream tasks. Otherwise, it would be impossible to translate modality inputs to complex latent space. In light of this, they use GLIDE as the pretrained generative prior, a data-driven model that can produce different pictures. Since GLIDE employs the text latent, it permits a semantic latent space.
Diffusion models
Diffusion and score-based approaches exhibit generation quality across benchmarks. On class-conditional ImageNet, these models rival GAN-based approaches in visual quality and sampling variety. Recently, diffusion models trained with large-scale text-image pairings have shown amazing capability. A well-trained diffusion model may provide a universal generating prior for synthesis.
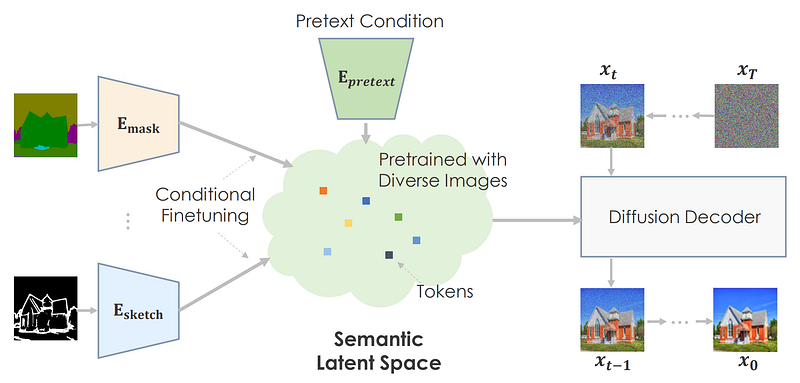
The Framework
The authors may pretrain on enormous data using pretext tasks and develop a highly meaningful latent space that predicts picture statistics. For downstream tasks, they conditionally fine-tune the semantic space to map task-specific circumstances. The machine creates believable visuals based on pretrained information.
Generative finetuning
Authors suggest pretraining the diffusion model using semantic input. They use the text-conditioned, image-trained GLIDE model. A transformer network encodes text input and outputs tokens for the diffusion model. As planned, textual embedding space is meaningful.

The picture above shows the writers’ work. Pretrained models increase picture quality and variety compared to from-scratch techniques. As the COCO dataset has numerous categories and combinations, basic approaches fail to provide aesthetically appealing results with compelling architectures. Their approaches may create rich details with precise semantics for difficult scenarios. The picture demonstrates their approach’s versatility.
Impact
Conditional image synthesis creates high-quality pictures that match the condition. Computer vision and graphics use it to create and manipulate information. Large-scale pretraining improves picture categorization, object identification, and semantic segmentation. Unknown is whether large-scale pretraining benefits general generating tasks. Energy usage and carbon emissions are picture pretraining’s key problems. Pretraining is energy-intensive, yet it’s only needed once. Conditional fine-tuning lets downstream tasks use the same pretrained model. Pretraining allows training a generative model with less training data, increasing image synthesis when data is restricted owing to privacy concerns or costly annotation costs.
Keywords: computer vision, Artificial Intelligence, datasets, Machine Learning, AI art, art, digital art, Training , carbon emissions, Diffusion models, finetuning, image-to-image
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (11.8K+ ML-professionals)
- Twitter (4.8K+ followers)
- Instagram (2.2K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
Project Page:
https://arxiv.org/pdf/2205.12952.pdf

@article{wang2022pretraining,
title = {Pretraining is All You Need for Image-to-Image Translation},
author = {Wang, Tengfei and Zhang, Ting and Zhang, Bo and Ouyang, Hao and Chen, Dong and Chen, Qifeng and Wen, Fang},
publisher = {arXiv},
year = {2022},
}




