
Breaking Language Barriers with Zephyr-7b: a model you can run everywhere!
Experience the Incredible Capabilities of a Brand New Multilingual Language Model

Everyone is looking for models that can speak and understand their own language! And this make sense: we have plenty of literature, unprecedented and innovative studies, music and art in any language.
Why can we not interact with them?
In this article I will show you how to easily use with many languages a new Language Model. You will be surprised by the results!
SPOILER Alert. I tested at least the following languages: French, Spanish, Italian, Korean, Japanese, Russian, Arabic, Hungarian…
If you are going to test with your own language, drop a message here so we can expand the list, like Jeff Araujo did

English is the main stream, but it would be really sad if it becomes a barrier to the powers of Natural Language Processing. In my quest for LLMs that can read, write and understand other languages I stumbled upon a brand new one…
Introducing Zephyr: Your New AI Assistant with Impressive Language Skills
In the vast landscape of artificial intelligence, a remarkable language model called Zephyr has emerged, ready to revolutionize the way we interact with AI.
Specifically, Zephyr-7B-α, the first model in the Zephyr series, has been meticulously crafted to serve as a helpful assistant, offering an unprecedented level of interaction and utility. So, let’s dive deeper into the development and performance of Zephyr-7B.
Derived from Greek mythology, Zephyr draws inspiration from the god of the west wind, symbolizing a gentle breeze that ushers in the refreshing season of spring. And just like its namesake, Zephyr-7B-α aims to bring a breath of fresh air to the world of language models.
The Zephyr team fine-tuned this impressive model, building upon the foundation of Mistral-7B-v0.1. To achieve its outstanding performance, Zephyr-7B underwent rigorous training using a combination of publicly available and synthetic datasets. What makes Zephyr-7B truly unique is the application of Direct Preference Optimization (DPO), a technique that has proven to be highly effective in enhancing the capabilities of language models.
NOTE: Since Zephyr is based on Mistral7b this model also is available under the permissive Apache 2.0 license, for use without restrictions.
Let’s start using it and then we go deeper!
Zephyr-7B-α in 8 lines of code
I am a fan of open source and free resources. Here we will check how to run this model on Google Colab free: but this method it can be used in any computer running only CPU.
First we need to install the CTransformers library and download the GGUF quantized version of the model
!pip install ctransformers>=0.2.24 !wget https://huggingface.co/TheBloke/zephyr-7B-alpha-GGUF/resolve/main/zephyr-7b-alpha.Q4_K_M.gguf
Then we create a Configuration object and a llm instance that will load into the VRAM the model, leaving the CPU in charge of the inferences
from ctransformers import AutoModelForCausalLM, AutoConfig, Config
conf = AutoConfig(Config(temperature=0.7, repetition_penalty=1.1, batch_size=52,
max_new_tokens=1024, context_length=2048))
llm = AutoModelForCausalLM.from_pretrained("/content/zephyr-7b-alpha.Q4_K_M.gguf",
model_type="mistral", config = conf)As you can see the model type is inherited by Mistral. Now we simply have to call the llm with a prompt!
NOTE: this model follows a specific prompt template that we must follow. Since I will test it with several languages I included in the system prompt the instruction to reply in the target language of the prompt. Anyway if the question has clearly only one language “signature” it is not needed
prompt = "quel est le sens de la science?"
template = f'''<|system|>Reply in the target language of the prompt
</s>
<|user|>
{prompt}</s>
<|assistant|>
'''
print(llm(template))The prompt is a question in French: the question will be included in the template. After that we print the llm inference llm(template).
Le sens de la science est d’augmenter notre connaissance du monde et de nous aider à comprendre les phénomènes naturels, en utilisant un processus rigoureux et une méthodologie scientifique. Elle permet également de trouver des solutions pour les problèmes que nous rencontrons dans la vie quotidienne et d’améliorer notre qualité de vie. En somme, la science est une force puissante qui nous aide à mieux comprendre le monde autour nous et à améliorer notre compréhension de l’univers en général.
Cool right? And this is it! I mean we can now change the prompt string with whatever we want and get the answer!
🧙♂️ Learn how to start to Build Your Own ai with This Free eBook
French, Spanish, Italian, Korean, Japanese, Russian, Arabic, Hungarian…
Well I couldn’t stop my curiosity so I decided to test many languages. I was really cynical because in the announcement of Mistral7b release it was clearly stated that it was good at english and code, so I initially discarded this model for multi language purposes.
In reality while testing in ChatBot Arena I found that it could speak Italian too. Automatically when Zephyr was released I put all of this on the test bench.

French, Korean and Japanese
For what I could see French fluency is quite good. It seems that the smaller the training set, the smaller the accuracy of a target language.
But at least for this general question also the 2 asian languages are correctly replying.

Arabic, Russian and Hungarian
Here we start seeing the limitations in the training dataset for some specific languages. As you can see from the Arabic (MSA) question/answer prompt, we are not getting a really consistent reply: moreover we get some quotes from the Holy Quran and the text is repeated several times, despite of the repetition_penalty settings.
For the Russian I am quite impressed: the text is consistent and the fluency is not so bad.
Hungarian on the other end is not that fluent and there are few repetitions in the reply, overall mediocre but not that bad.
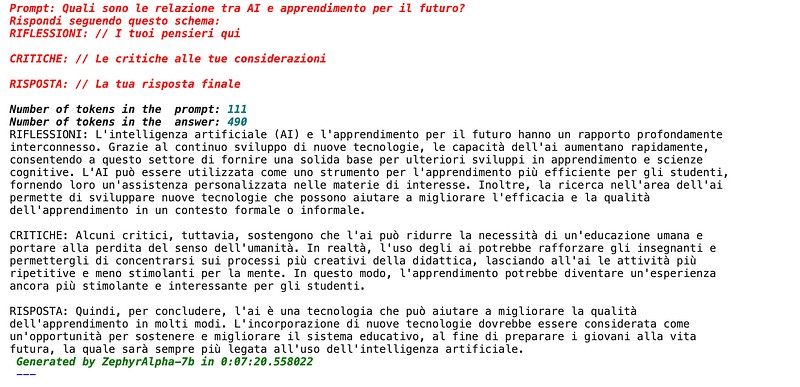
Italian
Maybe because it is my mother tongue I found it really easy to evaluate both the prompts and the results. In my opinion the results are not that far from biggest actors like OpenAI, but the amazing thing is that this is a 7 Billion parameters model, so the performances are outstanding!
The model can follow the instructions and also produce correctly the output according to the requested format. I asked also to translate the text from English to Italian and vice-versa and the quality is good indeed.
What is DPO?
In simple terms, this text is discussing the challenges of controlling the behavior of large-scale unsupervised language models (LMs) and introducing a new method called Direct Preference Optimization (DPO) to address these challenges.

Unsupervised language models learn a lot of general knowledge about the world and some reasoning skills, but it can be difficult to make them behave exactly as desired because they are trained without specific instructions.
Existing methods try to control their behavior by collecting labels from humans to evaluate the quality of the model’s output and then fine-tuning the model to align with these preferences. This fine-tuning process often involves reinforcement learning from human feedback (RLHF). However, RLHF is complex and can be unstable. It first creates a reward model that reflects human preferences and then fine-tunes the model using reinforcement learning to maximize this reward without deviating too much from the original model.
The authors of the paper propose a new approach called Direct Preference Optimization (DPO). They show that it is possible to optimize the process of maximizing the reward exactly using a single stage of policy training. Essentially, they solve a classification problem based on the human preference data. The resulting DPO algorithm is stable, performs well, and is computationally efficient. It eliminates the need to create a reward model, sample from the language model during fine-tuning, or spend a lot of time tweaking hyperparameters.
The experiments conducted by the authors demonstrate that DPO can fine-tune language models to align with human preferences as well as or even better than existing methods. Notably, using DPO for fine-tuning surpasses RLHF in controlling the sentiment of the model’s output and improves the quality of responses in tasks like summarization and single-turn dialogue. Importantly, DPO is much simpler to implement and train compared to RLHF.
Conclusions
With Zephyr-7B, the possibilities for AI-assisted interactions are endless. Experience the power of this advanced language model and witness firsthand how it sets new standards in language understanding and communication. Get ready to be amazed by Zephyr’s capabilities and embark on an exciting journey into the realm of AI language assistance.
Try yourself with your language and give me some feedbacks in the comments so that we can update the list, to be the most reliable as possible.
In a next article I will explain how to use the CTransformers library also to run GPTQ quantized model, simplifying the inference process.
If this story provided value and you like the topics consider subscribing to Medium to unlock more resources. Medium is a big community with high quality content: you can certainly find here what you need.
- Get my Free Ebook to Learn how to start to Build Your Own ai
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Highlight what you want to remember and if you have doubts or suggestions simply drop a comment to the article: I will promptly reply to you
- Read my latest articles https://medium.com/@fabio.matricardi
Don you want to read more? Here some topics




