
Beyond Context: Unveiling the Limits of Large Language Models’ Performance
Extended-context models are not necessarily better at using input context: it is time to Break the paradigm and rethink the Role of Context in Large Language Models.

ChatGPT increased the context window to 16k; Anthropic created a model (Claude) that can ingest up to 100k. Did we finally found the solution to our problems?
And how can we offload from the LLM the data handling but still get the answers? How all of the above can be done with Open Source Language
models?
In a recent study, researchers looked at how well LLMs perform on two different tasks. The first task involved finding important information within a given context. The second task focused on answering questions and retrieving specific information from multiple documents. (ref: Lost in the Middle: How Language Models Use Long Contexts)
The study discovered that LLMs tend to do better when the relevant information is at the beginning or end of the context they are given. However, when the important context is located in the middle of longer contexts, the performance of the models decreases significantly. This decrease in performance is observed not only in general LLMs but also in models specifically designed to handle long contexts.

Why we need context
LLMs don’t know it all. I mean, they are trained on a huge dataset, with several discipline sources, but they have a time limit and a size limit.
- the time limit is the frozen date for the start of the training: everything that happen after that time is unknown to the model
- size limit is given by the costs of training and the selection of the training dataset
When it comes to specific knowledge base Large Language Models tends to hallucinate because they cannot find the answer. For this use cases RAG is the best option. Retrieval Augmented Generation (RAG) is a technique that brings together information retrieval and generative models.
When we use Retrieval Augmented Generation (RAG), we add a piece of information to the prompt during the process of generating responses. This information is usually a paragraph or a snippet of text that we find by searching through a database using special search techniques. When it’s time for the LLM to generate a response, this retrieved text is given to it as additional input.
With RAG, the prompt or input is enriched with relevant and contextual supporting information. This empowers the LLM to generate informative and contextually accurate responses that align with the user’s input.
NOTE: this strategy is really effective for factual information, but at the actual state of the art is still lacking on multi-reasoning questions. In fact the retrieval part is affected by the type of embeddings and the chunks size. So how to get answers on complex reasoning where multiple documents sources must be retrieved? How we can ensure the context is not lost?

Why all we need is an agnostic LLM?
A real pioneer in the strategies for RAG and claiming that LLM must be agnostic is Cobus Greyling. His articles are amazing! Do yourself a gift and start following him.
The knowledge that the LLM possesses is ingrained within it. However, this knowledge is limited to the training data it has been exposed to, which has a specific timeframe and may not include the most recent information and current events.
The LLM plays a crucial role in managing conversational dialog and generating concise responses using natural language generation (NLG) techniques. It acts as the backbone, providing the necessary foundation for effective communication.
But what if we remove all the unnecessary knowledge baked into the LLM? Do we really need it? In the end we can always inject what we need with a RAG strategy. In this scenario LLM can be ignorant of all the other contexts, it can be completely Agnostic.
The best situation is when the LLM focuses on its main job as a utility without having to handle data or complex applications. By using a RAG implementation, we can handle use-cases that require large context windows separately from the LLM. This allows the LLM to focus on its core tasks while still addressing the needs of use-cases that require extensive contextual information.

Towards agnostic LLM
A recent study called Textbooks Are All You Need introduces a completely new paradigm. A new model has been trained with textbooks like a human student. The amazing idea behind it is that these textbooks are synthetically generated and a slim model (Phi 1.5 has only 1.3 Billion parameters) performs amazingly in the human-eval scores. It is like teaching only the basic reasoning on different disciplines, and give the LLM the usual natural language skills, without other unnecessary knowledge.
A direction that is currently ongoing in the LLM community is to focus on general reasoning Models, capable of understanding complex prompts, and leave the knowledge base to the RAG strategies or the examples given in the prompt. Phi-1.5 and the LaMini are few attempt to train lightweight models with very high quality data.
Here some studies as an example:
- A Survey on Large Language Model based Autonomous Agents
- Agents: An Open-source Framework for Autonomous Language Agents
- AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors in Agents
Once the LLM is offloaded from the data handling, what is left is to optimize the retrieval applications
A way forward: Better RAG strategies
There are actually few limitations with the Retrieval Augmented Generation approach. The first is that we usually put the text corpus inside a vector store database, splitting it into chunks. The second one is that we go for a similarity search between the question and the chunks that match it the most.
The chunks are the granularity we apply to the entire text: if it is too little we loose the general context; if it is too large the chunk may show as a whole only a poor similarity to the question.
The similarity search is the basic approach to match a question with a text with the answer keeping the semantic meaning: however semantic similarity and relevance are not the same thing.
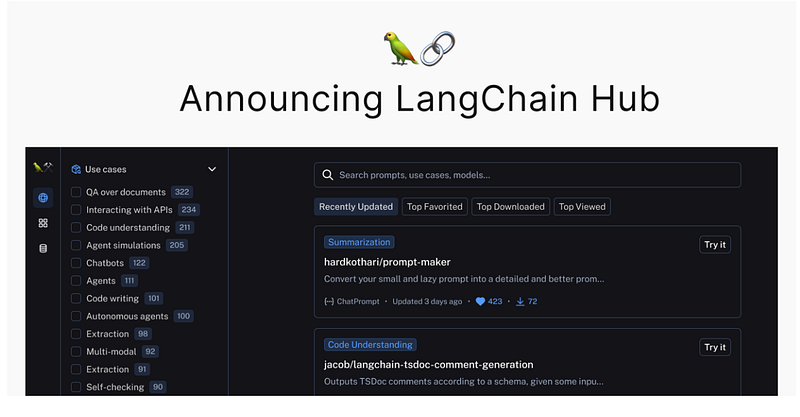
How can we make it better?
Here some suggestions (new or already explored ones…) we can try:
- Create more than one vector index: one that contains the summary of the text, and with a granularity balanced for facts and context (paragraph level). With this strategy we can always pair the question with two retrievals: the summary, to provide the bigger context, and the similarity search on the specific facts.
- Pick up a good embeddings model: not always faster means better. We must consider the token length available so that our chunks will not be truncated.
- Engineer chains that consider structural relationships among the documents and their part: knowledge graphs may come in hand here. Knowledge Graphs represent relationships between things. When we link passages to the specific documents or sections they come from, it helps us organize the information in a structured way. This way, we can understand the context and how everything is connected.
- Lost in the middle is a real thing: LLM forget things that are not placed at the beginning or at the end of the prompt. So why not re-rank the chunks according to their Relevance? The developers of Haystack were smart enough to take care of this: they released a component which optimizes the layout of selected documents in the LLM context window. The component is a way to work around the problem: the LostInTheMiddleRanker switches up the placing of the best documents at the beginning and end of the context window, making it easier for the LLM’s attention mechanism to access and use them.
- Prompt engineering experiments: this is a crucial field to keep on exploring. The LLM trend is oriented to train models able to understand complex instructions (see the agents and multi reasoning part). A lot to explore is left on the Open Source side of the Artificial Intelligence community. Langchain started LangSmith and Lanchain hub to collect the efforts of enthusiasts and experts, providing quick access to prompt templates to be used.
Next to come…?
These are my struggles and plans: create a Playground to test RAG strategies, prompts experimentation, different chunking and multiple vector indexes.
And all of above with only Open Source models, and (unfortunately) with no GPU. Do you think it will be possible? Do you have any suggestions?
Help me to figure out how we can do great things with Open Source LLMs. The literature is not really helping us: it is focused mainly on ChatGPT.
If this story provided value and you wish to show a little support, you could:
- Write a comment with your suggestions to how to make RAG better
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Read my latest articles https://medium.com/@fabio.matricardi
Meantime you can check:




