
LLM Do You Speak Only English?
Exploring Open Source Language Models for Multilingual Conversations

I never questioned too much the fact that also LLMs have a main-stream. I mean, I tried also ChatGPT & Claude and I was surprised how they were able to switch from one language to the other with no issues.
But recently from the Medium community I have been requested to specify the Languages for the LLM I am writing about. I started to dig a little into it and I found that… it is not clear at all!
So in this article I will introduce the multilingual models and show you few that can speak and understand not only English!
Follow along with the provided Google Colab Notebooks and learn how to do it yourself!
T5 and Multi-language
After introducing Mistral7b one Italian reader asked me if Mistral can also be used with Italian documents and in general with the Italian language.
I imagined myself already rushing into the Hugging Face hub and start filtering models with Italian language… Surprisingly I found only a bunch of them, and basically all part of the T5 family.
The transformer models, like T5 and the BART family, have their roots in a type of model called sequence-to-sequence. These models consist of an encoder and a decoder, and they can be trained using various techniques.
Because of their nature they are the best suited for translation purposes and can be trained on more than one language. As a drawback, they cannot be (so far…) quantized: this means that you need a really powerfull computer to run them.
One such technique is span corruption and reconstruction. Sequence-to-sequence models are particularly useful for language translation tasks.
Is there any Open Source polyglot?
Have you ever tried to ask Llama2 a question in a language different from English? What result did you get?
The reasons are simple. All the GPT family of modern LLMs, such as the ChatGPT series, Llama, Mistral and BLOOM, are autoregressive models. In this type of architecture, the decoder component is kept while the encoder part is discarded after pre-training. But what if any of these pre-trained models have a good multi language dataset as a baseline?
In my quest for an Italian Proficient LLM (but I guess valid also for Spanish, French… well better you try 😏) I tested 4 different Open Source language models to verify if they are pre-trained for multiple languages.
NOTE: I didn’t test Mistral7b at all, because I initially understood that was trained only for English. You will see why I changed my mind
The 4 contestants I picked up are:
- Llama2–13b
- Orca_mini_v3_13b
- Vicuna-13b
- WizardLM-13b
I wanted to check them on a bigger parameters level, and only after that I tried to pick the smaller versions and verify the performances.
To give you a good preview, except for Llama2, all the other ones can speak and understand Italian very fluently, even with the 7B parameter model! But the Llama2 model can surprise you: the Chat version apparently can speak other languages!!!
ChatArena Italian showdown
This time I looked for a more impersonal approach to the evaluation. I mean, I can always decide myself about the quality of the answers given by the different LLMs, but to overcome my personal point of view I opted to use the ChatBot Arena approach.

Inspired by the paper Judging LLM-as-a-judge with MT-Bench and Chatbot Arena, and by the first investigations on multi language capabilities on Hugging Face Hub, I proceeded as follows (and you can do the same on your target language as well 🤹♂️🏟️):
- run with GGML/GGUF model A with language specific prompts
- save into a pickle file the database of questions and answers received
- run in GGML/GGUF model B with the same language specific prompts of model A
- save into a pickle file the database of questions and answers received
- Run with GPTQ a third model to act as a Judge of model A and model B answers and assign grades to them to declare the winner
You can find the Google Colab Notebooks that work with free tier resources only in my GitHub repo
So, follow me along and discover how to do it yourself
Test your language out
I have previously wrote about how to run basically every quantized model on a free Google Colab Notebook. The advantages are that:
- You don’t need to buy an expensive hardware upfront before testing out and decide what model is the right one
- You can play around as much as you like exploring the capabilities with prompt engineering techniques
I learned that Vicuna is able to speak Italian during my initial curious experiments with ChatBot Arena. In fact you don’t know who model A and model B are until the judgement is complete. In my test Vicuna33b was the winner, and for me it was the best hint to understand the Italian capabilities I was looking for:
So you write a question, and you will see the answers streaming for both models. When it is completed you evaluate if A or B wins, or if it is a tie. After your evaluation the contestants are revealed. See my surprise when I discovered that both Llama2 and Mistral7b-instruct can speak Italian!!!
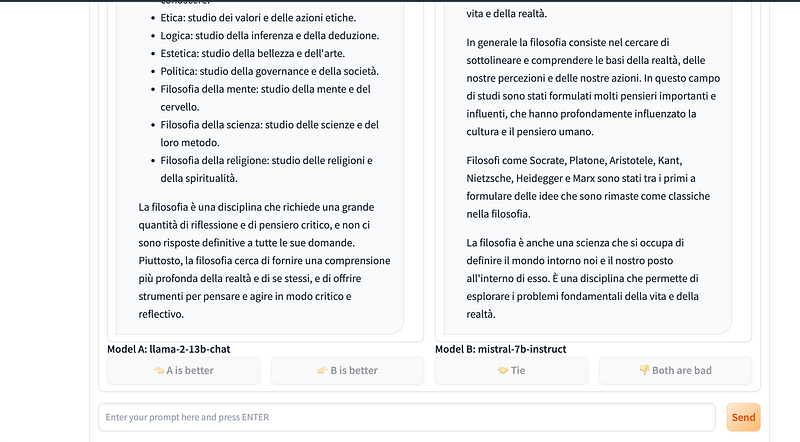
LLM can speak Italian
Well, in my easygoing BattleArena mode, I decided to test Vicuna, WizardLM and Orca_mini.
If you want to know your language support, run your ChatBot Arena
Here I will report only the code used for the evaluation of the winner. As I mentioned this time one LLM is assigning grades to the text generated.
I picked up the idea from page 14ss of the mentioned paper LLM as a Judge: the prompt template they used for the ChatBot Arena idea are all listed there! I had to tweak them a bit but it wasn’t too hard.
Prompt Template
prompt_template=f'''USER: Please act as an impartial judge and evaluate the quality of the response provided by an
AI assistant to the user question displayed below. Your evaluation should consider factors
such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of
the response. Begin your evaluation by providing a short explanation. Be as objective as
possible. After providing your explanation, please rate the response on a scale of 1 to 10
by strictly following this format: "[[rating]]", for example: "Rating: [[5]]".
[Question]
{question}
[The Start of Assistant’s Answer]
{answer}
[The End of Assistant’s Answer]
ASSISTANT:
'''NOTE: I tried to use also the template that evaluate the winner🏆 … But the LLM was choosing always the Model_A, even if the single grading was different.

Prompt Engineering and formatted output
An important point to understand is that the prompt must be good. You can see my previous article about it.
In this scenario you need also to translate in your target language the prompt template to make sure that it will be understood and produce the desired answer.
Here an example: Here I asked to translate into English the result of an Italian text generated previously .
Prompt: Traduci in lingua Inglese il seguente testo delimitato da tre backquotes:
```
RIFLESSIONI: L'AI e l'apprendimento automatico sono tecnologie in continua evoluzione che hanno il potenziale
di trasformare molte aree della vita umana, dalle decisioni finanziarie alle cure mediche. Tuttavia, come
tutte le tecnologie, anche l'AI ha i suoi limiti e rischi. È importante considerare gli effetti a lungo
termine dell'uso dell'AI, comprese le questioni etiche che si presentano in questa area.
CRITICHE: Una critica all'idea che l'AI possa sostituire completamente i dati di mercato è che l'AI non può
ancora prevedere il futuro con precisione e che ci sono molte variabili imprevisibili che possono influenzare
le decisioni finanziarie. Inoltre, anche se l'AI può fornire valutazioni e raccomandazioni, la decisione
finale spetta sempre all'uomo.
RISPOSTA: Sono d'accordo con entrambe le posizioni presentate, ma credo che l'AI possa avere un impatto
significativo sulla formazione del futuro. L'AI può essere utilizzata per analizzare grandi quantità di dati e
prevedere tendenze e cambiamenti nel mercato finanziario a breve e lungo termine, ma non può sostituire
completamente la comprensione umana delle decisioni finanziarie. Inoltre, l'AI può essere utilizzata per
creare modelli di simulazione che consentono agli investitori di esercitarsi e migliorare le loro capacità di
previsione, senza dover affrontare i rischi reali del mercato finanziario. Tuttavia, è importante considerare
anche gli effetti a lungo termine dell'uso dell'AI in questo campo e affrontare le questioni etiche che si
presentano in questa area.
```On the other side you can use the same format to translate into Italian:
Translate into Italian the following text delimited by triple backquotes:
```Lost in the Middle: How Language Models Use Long Contexts. Language models have become an important and
flexible building block in a variety of user-facing language technologies, including conversational
interfaces, search and summarization, and collaborative writing. These models perform downstream tasks
primarily via prompting: all relevant task specification and data to process is formatted as a textual
context, and the model returns a generated text completion. These input contexts can contain thousands of
tokens, especially when using language models on lengthy inputs (e.g., legal or scientific documents,
conversation histories, etc.) or augmenting them with external information (e.g.,relevant documents from a
search engine, database query results, etc; Petroni et al., 2020; Ram et al., 2023; Shi et al., 2023; Mallen
et al., 2023; Schick et al., 2023, inter alia). Handling these ...arly visualized in Figure 1, as we vary the
position of the relevant information —language model performance is highest when relevant information occurs
at the very beginning or end of its input context, and performance significantly degrades when models must
access and use information in the middle of their input context (§3.3). For example, when relevant information
is placed in the middle of its input context, GPT3.5-Turbo’s performance on the multi-document question task
is lower than its performance when predicting without any documents (i.e., the closedbook setting; 56.1%).
```Conclusions
With the new big actors also in the Open Source community, we cannot rely anymore only on the Hugging Face Hub model filtering to understand if a LLM is trained in more than one language.
Make use of the Battle Arena or simply try to experiment to witness yourself the capabilities and accuracy.
All the notebooks used are in the Notebooks section of the GitHub repo
If this story provided value and you like the topics consider subscribing to Medium to unlock more resources. Medium is a big community with high quality content: you can certainly find here what you need.
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Highlight what you want to remember and if you have doubts or suggestions simply drop a comment to the article: I will promptly reply to you
- Read my latest articles https://medium.com/@fabio.matricardi
Don you want to read more? Here some topics





