
Machine Learning Art
AI Pose Estimation — Ready-to-use
Simple Vision Transformer | state-of-the-art (SOTA)

The simple vision transformers can be used for a wider range of image processing activities, such as estimating the posture of humans and animals.
- May 2022 — AI art tools update can be found ➡️ HERE ⬅️

Customized vision transformers have recently been applied for human posture estimation and have outperformed more complex architectures. However, whether or not simple vision transformers can help with pose estimation is still unknown. In this research, the authors use a primary and non-hierarchical vision transformer and simple deconvolution decoders called ViTPose for human pose estimation as a first step in answering the question. They show that a simple vision transformer with MAE pretraining may perform better after finetuning on human posture estimation datasets. Furthermore, ViTPose is scalable in model size and flexible in terms of input resolution and token number.
Project page + code ( scroll down )

METHOD
Simple vision transformer baselines. On the MS COCO validation set, a basic baseline with the ViT-Base backbone with 256 192 input resolution achieves 75.8 mAP, outperforming or comparable to state-of-the-art (SOTA) results based on vision transformers, such as 75.6 mAP from HRFormer and 75.8 mAP from TokenPose and TransPose.
Pretraining. For greater performance, vision transformers are often data-hungry and require a large amount of training data. To remedy this issue, a number of projects have been proposed. In this study, the authorsuse MAE He pretrained weights on ImageNet1K Den , which comprises 1M image data, to initialize the vision transformer backbones.
Finer-resolution feature maps. The researchers investigate the benefits of employing finer-resolution feature maps for posture estimation to improve the performance of simple vision transformer baselines.
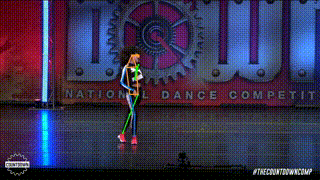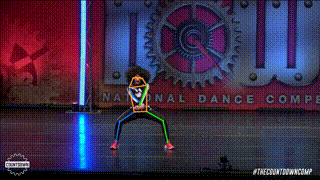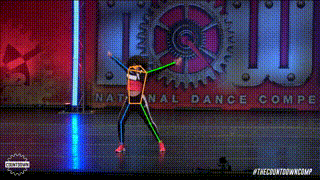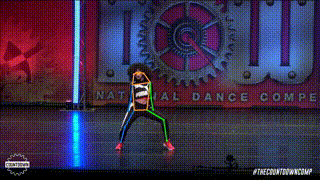
ANALYSIS OF SOTA METHODS
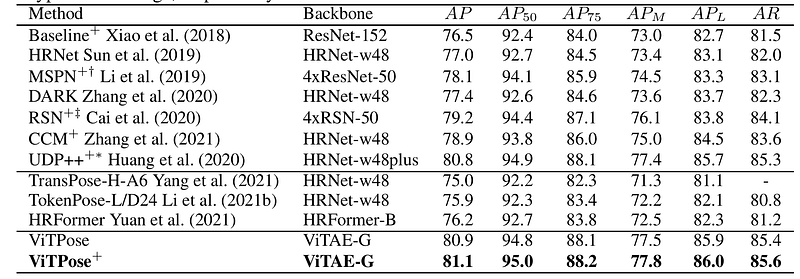
The authors show that, even without specialized designs, the plain vision transformer can generalize effectively on the human position estimation problem in this study. On the COCO test-dev set, the suggested simple but effective vision transformer baseline, ViTPose, achieves the best 81.1 mAP, benefiting from a larger model size, higher input resolution, and more token numbers.
@misc{xu2022vitpose,
title={ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation},
author={Yufei Xu and Jing Zhang and Qiming Zhang and Dacheng Tao},
year={2022},
eprint={2204.12484},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Project Page :
https://arxiv.org/pdf/2204.12484.pdf
Code:
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, digital art, pose estimation, ViTAE-Transformer, Simple Vision Transformer, ViTPose,
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/evartology
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai




