Machine Learning Art
New method converts two images into 3D model
the art and science of extracting 3D information from photographs

What is photogrammetry 3D scanning?
Photogrammetry is a way to make models in three dimensions. It’s an alternative to 3D scanning that lets you use photos instead of light sources. You could easily use photogrammetry to make your 3D models if you had a camera, a computer, and software that was made for photogrammetry.
- June 2022 — AI art tools update can be found ➡️ HERE ⬅️
The new photogrammetry method eliminates the need to take many pictures for camera pose estimation and 3D reconstruction, which could save money on storage and processing. But unfortunately, it could also be used to spy on people and may raise privacy concerns as it becomes easier to put together a 3D model from a few images.
Project Page (scroll down)
How can I turn a picture into a 3D model?
In computer vision, it has been a problem for a long time to figure out how to use extreme-view images to figure out where the cameras are and how the scene is shaped. Current 3D reconstruction algorithms often use the image-matching paradigm and assume that a part of the scene is visible in multiple images. As a result, there isn’t much overlap between the photos, which can lead to poor performance. On the other hand, humans can use their knowledge of shapes to link parts visible in one image to parts not visible in another photo.
Because of this, the authors have devised a new idea called “virtual correspondences” (VCs). VCs are two pixels from two different images whose camera rays cross in three dimensions. VCs follow epipolar geometry, just like classic correspondences, but unlike classic correspondences, VCs don’t have to be visible in all views simultaneously. So, VCs can be set up and used even if the images don’t overlap.

The authors develop a way to find virtual correspondences based on the people in a scene. They show how VCs can be combined with traditional bundle adjustment seamlessly to recover camera poses across extreme views. Experiments show that the method performs much better than the best current methods for figuring out where a camera is in challenging situations. It serves about the same as the traditional setup with many images. Their approach also unlocks the potential for many tasks after it, such as recreating a scene from multiple stereo views and making new views in extreme-view situations.
3D human estimation
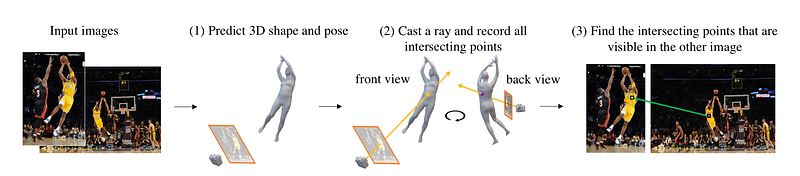
First, use the picture on the left to guess the 3D shape and pose of the basketball player. Then, shoot a ray and write down all the places it hits, like his back and belly button. Even though the two images barely touch, the right one shows the back of the player. So, the method can tell that the rays of the two pixels cross in 3D and are virtual matches. The same process is used to make the right image, too.
Using Humans to Get VC Estimates
People are the most common “objects” in pictures, so that’s what the authors focus on. With a 2D image, they first use a deep network to predict the 3D shape and pose of each person in the scene, as well as their relative poses to the camera. They use SMPL as a representation because it lets them put together a full mesh of a human from pieces of information. Then, they sent a ray through each pixel and used ray-plane intersection to record all the 3D points where the rays hit the human mesh. Lastly, the authors check to see if any of these 3D points can be seen in other 2D images. If they do, we say that the two pixel rays cross in 3D, and the two pixels that they touch are VCs. In particular, we use a program called DensePose to link each pixel to a point on the human mesh. If a ray hits the back of the mesh and DensePose tells us that a certain pixel is the back, then these two pixels are called vertex connectors (VCs). They point out that their method is general and could be used on other objects as long as they have the right shape priors and surface mapping.
A new idea called “virtual correspondences” is two image points whose camera rays cross in three dimensions.
In contrast to traditional correspondences, virtual correspondences do not have to describe the same 3D points that can be seen at the same time. The authors came up with a way to pull out virtual correspondences from an image based on what they already knew about the foreground objects and how they fit into existing 3D frameworks. Their experiments with two difficult human-based datasets show that virtual correspondences are essential for successful camera pose estimation, multi-view stereo, and novel view synthesis in extreme-view scenarios.
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, digital art, pose estimation, photogrammetry, Simple Vision Transformer, DensePose, 2D to 3D, 3D model
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/evartology
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (14.2K+ ML-professionals)
- Twitter (4.9K+ followers)
- Instagram (2.2K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
Colab (comming soon)
Project Page:
@inproceedings{ma2022virtual,
title={Virtual Correspondence: Humans as a Cue for Extreme-View Geometry},
author={Wei-Chiu Ma and Anqi Joyce Yang and Shenlong Wang
and Raquel Urtasun and Antonio Torralba},
journal={CVPR},
year={2022}
}