
6 pre-processing techniques to use for your information retrieval system
Story overview
- Introduction
- Lemmatization
- Stemming
- Remove unnecessary characters
- Stop-words
- Lower case
- Correct spelling

Introduction
This article will talk about different pre-processing techniques you can use within information retrieval (IR). Pre-processing techniques here, refer to methods you can apply to your data, to make your information retrieval algorithm like for example TF-IDF, work better.
The data in this case will be documents. Documents are just a string representing the information contained in our document. For our IR algorithm, we would like to retrieve the documents (information), that is most relevant to our query, where the query is what we search for. Our documents could therefore look like a list of strings.
Now, we would like to pre-process these strings by applying different techniques to them:
Lemmatization
Lemmatization is converting similar words, to the same word. This is important for IR, as you want to fetch the most relevant documents, and if words are similar, they are often relevant as well.
Examples of lemmatization:
- Programming -> program
- Walking -> walk
- Better -> good
With lemmatization, our vocabulary will be smaller, and algorithms like TF-IDF can therefore work better.
Lemmatization implementation in Python:
To implement lemmatization, we will use the nltk package. Before importing the WordNetLemmatizer, we need to download a package from NLTK first. Run the code below in a separate file (or cell if you are using a notebook)
#download wordnet from the NLTK package
import nltk
nltk.download('wordnet')This will download word net. Now you can import the Lemmatizer:
#Implementing lemmatizer in Python
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
# a denotes adjective in "pos"
print("better :", lemmatizer.lemmatize("better", pos ="a"))
print("good :", lemmatizer.lemmatize("good", pos ="a"))
print("\nworst :", lemmatizer.lemmatize("worst", pos ="a"))
print("bad :", lemmatizer.lemmatize("bad", pos ="a"))You can now see that some of the words like “better” and “worst” are changed, while “good” and “bad” stay the same. The overall theme here however is that lemmatization reduces the vocabulary size of your corpus.

Stemming:
Stemming is changing words to the standard form of the word. This works because the present tense of a word often means the same as the infinitive of a word. We therefore convert all conjugations of a word, to its infinitive form. An example is shown below:
#stemming implementation Python:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print("Walk : ", stemmer.stem("walk"))
print("walking : ", stemmer.stem("walking"))
print("walked : ", stemmer.stem("walked"))You can then see the output here:
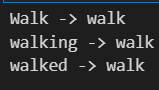
Remove unnecessary characters:
Sometimes, it can also be good to remove certain characters. An example could be to remove punctuation. Removing characters can be done with the RegexpTokenizer from nltk.tokenize. The tokenizer takes in a regex string and tokenizes the sentence with the use of the regex string. There is a lot of depth to regex which I will not go into here, but you can check it out at RegexDocs. If you want to remove punctuations, you can for example use the code below. Do note that the tokenizer converts a string, to a list of strings containing a token (a part of the sentence), so if you want to make the list a string again, you can use the last line below, joining the list into a string.
#nltk tokenizer to remove punctuations
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+') #tokenizer = RegexpTokenizer('\w+')
sentence = "I love apples. They taste very nice"
tokenizedSentence = tokenizer.tokenize(sentence)
# in list format
print(tokenizedSentence)
# in string format:
print(" ".join(tokenizedSentence))
Stop-words:
Stop words are commonly used words in a language such as “the” or “I”. These words often do not contribute a lot to the meaning of a sentence, and can therefore be removed. You can remove stopwords in Python with the following code:
#remove stopwords in Python
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
def removeStopWords(string) -> str:
"""takes in a string, removes stop words from it, and returns the string without stopwords"""
word_tokens = word_tokenize(string)
filtered_sentence = [w for w in word_tokens if not w.lower() in stop_words]
return " ".join(filtered_sentence)
sentence = "Hi, I am a Python programmer that likes the platform Medium"
print(removeStopWords(sentence))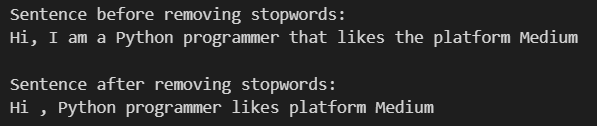
Lower case:
It is a good idea to have all words be lowercase, as a word with a first letter lowercase or uppercase is rarely different. It should be noted that sometimes capital letters can be used to express feelings, for example, if a word is written in all uppercase. To make words in Python lower, you can use the code below (this will make all letters lowercase, except if the whole word is upper case, then it is kept as uppercase):
#convert string lower case except words in all uppercase
import re
#use regex to make all words lowercase except all uppercase words
inputString = "I am SO EXCITED for This course. It looks SUPER Interesting."
pat = re.compile(r"[A-Z]*[a-z]|\s[A-Z]\s|^[A-Z]\s")
outputString = pat.sub(lambda match: match.group().lower(), inputString)
print(inputString)
print(outputString)
print(inputString.lower()) #make the whole string lowercase with .lower()
Correct spelling:
The last pre-processing technique is making sure you have the correct spelling. If something is spelled wrong, then it could be difficult to retrieve the correct information. The spelling correction can be used both in your corpus (the text you are retrieving information from), or the query that is used to retrieve information, so it is not just a pre-processing technique.
First, you have to install the autocorrect package in the terminal:
pip install autocorrect
Now you simply import the package and run the spell checker, you can see it outputs the correct words. Do note that sometimes, especially with severe spelling mistakes, it can be hard to know the intent of which word was intended to use, so this spellchecker will just choose the most likely word given the word that is input.
# correct spelling in Python with autocorrect
from autocorrect import Speller
spell = Speller(lang='en')
#spellchecking single words
print(spell("nicee"))
print(spell("intresting"))
print(spell("botlte"))
#spellchecking for whole sentence
sentence = "I think the botlte was verry intresting"
tokenizedSentence = sentence.split()
for idx, token in enumerate(tokenizedSentence):
tokenizedSentence[idx] = spell(token)
spellCheckedSentence = " ".join(tokenizedSentence)
print("\nOld sentence: ", sentence)
print("\nSpellchecked sentence: ", spellCheckedSentence)
Conclusion:
These are just some pre-processing techniques you can implement in your information retrieval system. I recommend using them with care since sometimes a pre-processing technique can change your data in different ways than you intended. Other than that, they can also be used in combination. I would for example remove stopwords from a corpus (your data), spellcheck the words, and then do stemming on the words. This is just an example of some pre-processing you can do on your data.
If you want to check some other related articles I have written, please check out:
- ✅ Fine-tuning EasyOCR
- ✅ Empower your Donut (document understanding transformer) model
- ✅ Running Llama2 locally on Windows
- ✅ Analyzing graph networks: Utilizing advanced methods
You can also read my articles on WordPress.





