
Machine Learning Art
20 billion-parameter AI art model
Pathways Autoregressive Text-to-Image model PARTI

When artists read or talk about a scene, they can picture it in their minds in great detail. Supporting the ability to make images based on these descriptions could open up creative possibilities in many areas of life, such as the arts, design, and multimedia content. Recent research on text-to-image generation, such as DALL·E 2 ,Imagen and Co, has made much progress in making high-quality images and showing that it can generalize to combinations of objects and ideas that it hasn’t seen before. Both use modern sequence-to-sequence architectures like Transformers to learn the relationship between language inputs and visual outputs.
- June 2022 — AI art tools update can be found ➡️ HERE ⬅️
How many parameters does Dall-E 2 have?
3.5-billion-parameter
DALL-E 2 is controlled by a 3.5-billion-parameter model that was trained on thousands of pairs of photos and descriptions from the internet. This method lets the model make connections between visual concepts and texts that describe them. CLIP and DALL-E datasets (approximately 650 million images in total) GPT-3 has 175 B Parameters
20B -PARTI by Google Research
Pathways Autoregressive Text-to-Image model (Parti), an autoregressive text-to-image generation model that can make high-fidelity photorealistic images and supports content-rich synthesis with complex compositions and world knowledge. Recent advances in diffusion models for text-to-image generation, like Google’s Imagen, have also shown impressive capabilities and state-of-the-art performance on research benchmarks. Both Parti and Imagen look at two different families of generative models: autoregressive and diffusion. This makes it possible to combine these two powerful models in interesting ways.
Project Page (scroll down)
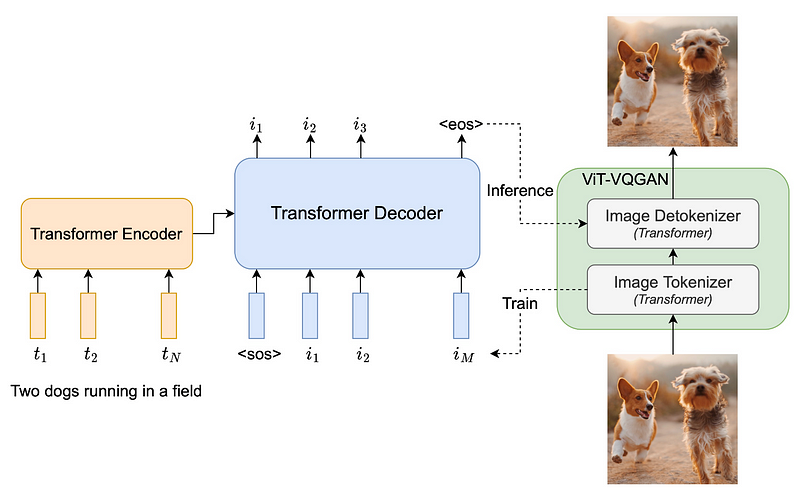
Parti thinks of text-to-image generation as a sequence-to-sequence modeling problem, similar to machine translation. This lets it take advantage of improvements made to large language models, especially those that can be used when data and model sizes are increased. In this case, the target outputs are not strings of text in another language, but rather sequences of image tokens. Parti uses the powerful image tokenizer ViT-VQGAN to encode images as sequences of discrete tokens and takes advantage of its ability to rebuild such image token sequences as high-quality, visually diverse images.
The following results were seen by the authors:
🔵 By making Parti’s encoder-decoder work with up to 20 billion parameters, the quality keeps getting better.
🔵 On MS-COCO, a zero-shot FID score of 7.23 and a fine-tuned FID score of 3.22 are considered to be state-of-the-art.
🟠 Effectiveness across a wide range of categories and levels of difficulty in their analysis of Localized Narratives and PartiPrompts, a new global benchmark of 1600+ English prompts.
From 350 million to 20 billion parameters
Parti is implemented in Lingvo and scaled with GSPMD on TPU v4 hardware for both training and inference. This allowed us to train a 20B parameter model that sets records on multiple benchmarks.

The authors compare the 350M, 750M, 3B, and 20B scales of Parti models in great detail and find:
🔵 Consistent and significant improvements to the model’s capabilities and the quality of the images it produces.
🔵 When people looked at the 3B and 20B models side by side, most of the time they liked the 20B model better. 63.2 percent for image quality and how real it is. 75.9 percent for text-to-image match
🟠 The 20B model works best with prompts that are abstract, require knowledge of the world, require a specific point of view, or require writing and symbol rendering.

Responsibility and effects on a larger scale
Text-to-image models offer many opportunities and risks that could affect bias and safety, visual communication, false information, creativity, and art. In the same way as with Imagen, the authors of Parti know that it could contain harmful stereotypes and representations. Some possible risks have to do with how the models are built, especially for the training data. Current models like Parti are trained on large, often noisy, image-text datasets that are known to have biases about people from different backgrounds. Because of this, these models, like Parti, tend to give stereotypical descriptions of people, like lawyers, flight attendants, homemakers, etc. They also tend to show Western biases toward things like weddings. This is a problem for people whose backgrounds and interests aren’t well represented in the data and model, primarily if these models are used for visual communication, for example, to help social groups with low literacy levels. Models that make outputs that look like photos, especially of people, add more risks and worries to making deepfakes. This creates risks for spreading possible visual misinformation and for the people and organizations whose pictures are used or mentioned.
Text-to-image models give people many new ways to make unique and aesthetically pleasing images. They act as a paintbrush to help people be more creative and do more. But it’s essential to have a nuanced understanding of algorithmically based art over time, the model itself, the people who worked on it, and the art world when judging its design or artistic value. Bias is also critical because the range of outputs from a model depends on the training data. This may lead to a bias toward Western imagery and make it harder for models to show utterly new art styles like humans can.
Because of these things, the people who made Parti models, code, and data have decided not to let the public use them until more safety measures are in place. In the meantime, they put a “Parti” watermark on all of our shared images.
As a curator of AI art, I believe that ready-to-use, ultra-large models will help people be more creative and productive, rather than replace them, so that we can all enjoy a world of new, engaging, and responsible ways to view AI art.
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, digital art, Dalle 2, Imagen, Parti, text-to-image, diffusion models, generative art,
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/evartology
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (14.8K+ ML-professionals)
- Twitter (4.9K+ followers)
- Instagram (2.2K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
Project Page :
https://gweb-research-parti.web.app/parti_paper.pdf

Parti is a collaboration that spans authors across multiple Google Research teams:Jiahui Yu*, Yuanzhong Xu†, Jing Yu Koh†, Thang Luong†, Gunjan Baid†, Zirui Wang†, Vijay Vasudevan†, Alexander Ku†, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang Jason Baldridge†, Yonghui Wu*





