
ARTIFICIAL INTELLIGENCE & REPRESENTATION
What’s in a name? Exposing the hidden racial bias of AI Image Generators when prompting first names
AI image generators show ethnic preferences in character generation based on first names, revealing stereotypes in AI training data. This highlights the need for diverse datasets to address foundational prejudices in AI.
Naming characters in AI images has been a point of debate since the start. Some say it results in consistent characters, some say it’s nonsense. They’re both right (glass half full!). No, Midjourney won’t “remember” a character if you name it. It doesn’t flow back up the training data! That’s the correct criticism against using names. But some names do tend to prompt certain archetypes. Yes, it works because of stereotypes, but it can be a useful tool.
(One which we don’t really need now that Midjourney is testing a character reference parameter--cref that allows for greater control and specificity).
But basically, what I’ve discovered is that names — when used as a prompt with no other context — are more likely to steer the AI to generate subjects of one ethnicity over another. This is a double-edged sword that exposes the underlying stereotypes and biases in the training data of AI systems.
The Name Game: Stereotypes or Handy Shortcuts?
So, for example, put in a name like “Doreen” and you’ll usually get an old white woman; while “Ernestine” gets you a older Black woman. “Dan” is a generic white guy; “Tobias” is a white hipster; “Terrence” is a Black man.






This could be because of stereotypes, or real world distributions of names, or it could be the one person overwhelms the tags (“Derren”, for example, produces a selection of images that are uncannily like British mesmerist Derren Brown, suggesting that some form of overfitting may be at play).
It’s potentially problematic, revealing how past issues of representation in visual culture are perpetuated by AI. It’s not dissimilar to why AI clocks are stuck at 10:10 due to ingrained patterns in training data (see article below).
In the experiments I conducted on Midjourney, all the names resulted in images of individuals who were either Black or white (ChatGPT offered a slightly better range of diversity). This highlights another limitation in the diversity of the AI’s output. The lack of representation of other racial and ethnic groups in the AI-generated images raises questions about the inclusivity and comprehensiveness of the training data being used.
Breaking Down Midjourney Biases: From Early Days to Today
Upfront, I want to say I first discovered this phenomenon in June 2023, so if you want to try it out yourself, I suggest reverting your Midjourney to the older Version 5 (just append the parameter --V 5.0 to your prompt). The subsequent MJ releases have not got rid of this effect entirely, but they do obscure it somewhat. In V5 you can get the results nearly 100% of the time; in V6 it’s definitely still noticeable, but reduced to maybe a 60% frequency.
Having said that, it’s worth running the same experiment in V6 to see what persists; there is still a propensity for some first names to prompt faces of certain ethnicities over others. Interestingly, some names will have a split across the four images for each request, but still with a definite preference:



I’m not certain what Midjourney changed that reduced (but didn’t remove) the effect across V5 to V6, but what’s important is that it’s likely a modification to your prompt (much like ChatGPT does with Dall-E prompts, as revealed in the diversity part of its secret system instructions), and not any update to the training data, which remains largely unaltered.
Racial Representation Issues Are Deeply Rooted in Datasets
Popular datasets used for training AI image-generating programs include:
- Microsoft’s Common Objects in Context (COCO)
- Stanford Lab’s Visual Genome dataset, and
- The Flickr30k dataset
The datasets of images and their corresponding textual descriptions have not changed, so whatever racial biases we expose in V 5.0 still exist in the training data that is being used; they’ve just been compensated for, or masked, perhaps by inserting diverse terms into your prompt post hoc. In fact, ChatGPT is pretty upfront about intentionally modifying for variety:

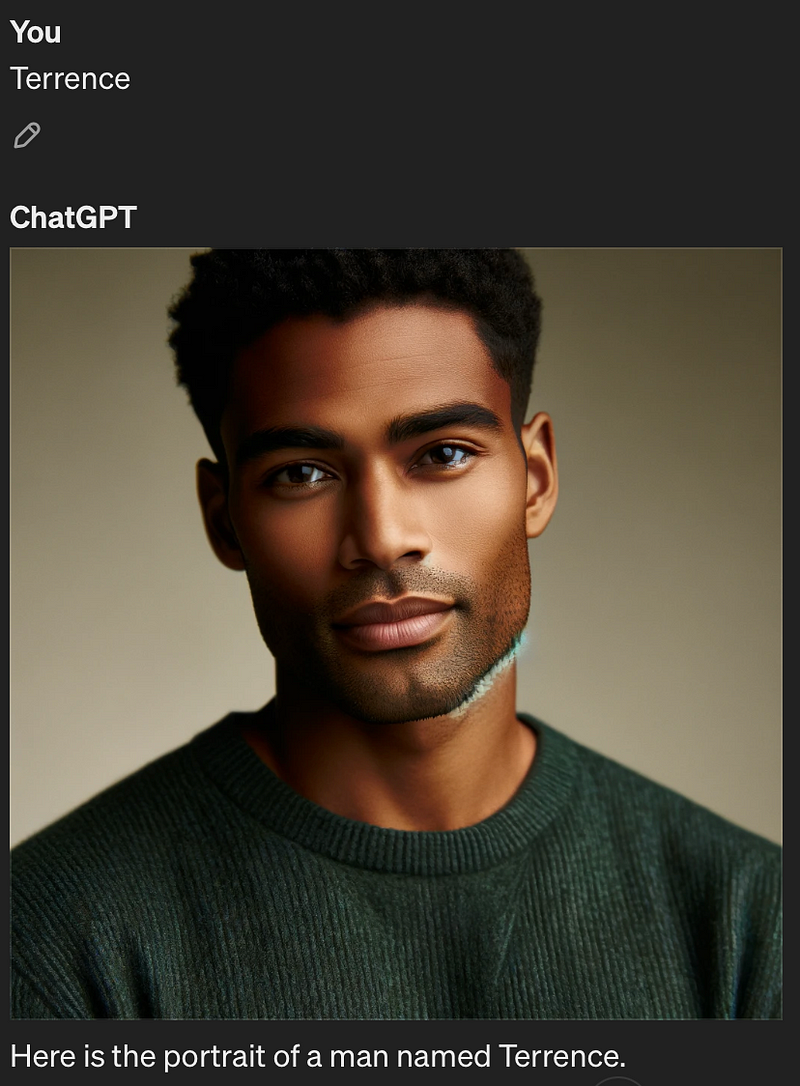

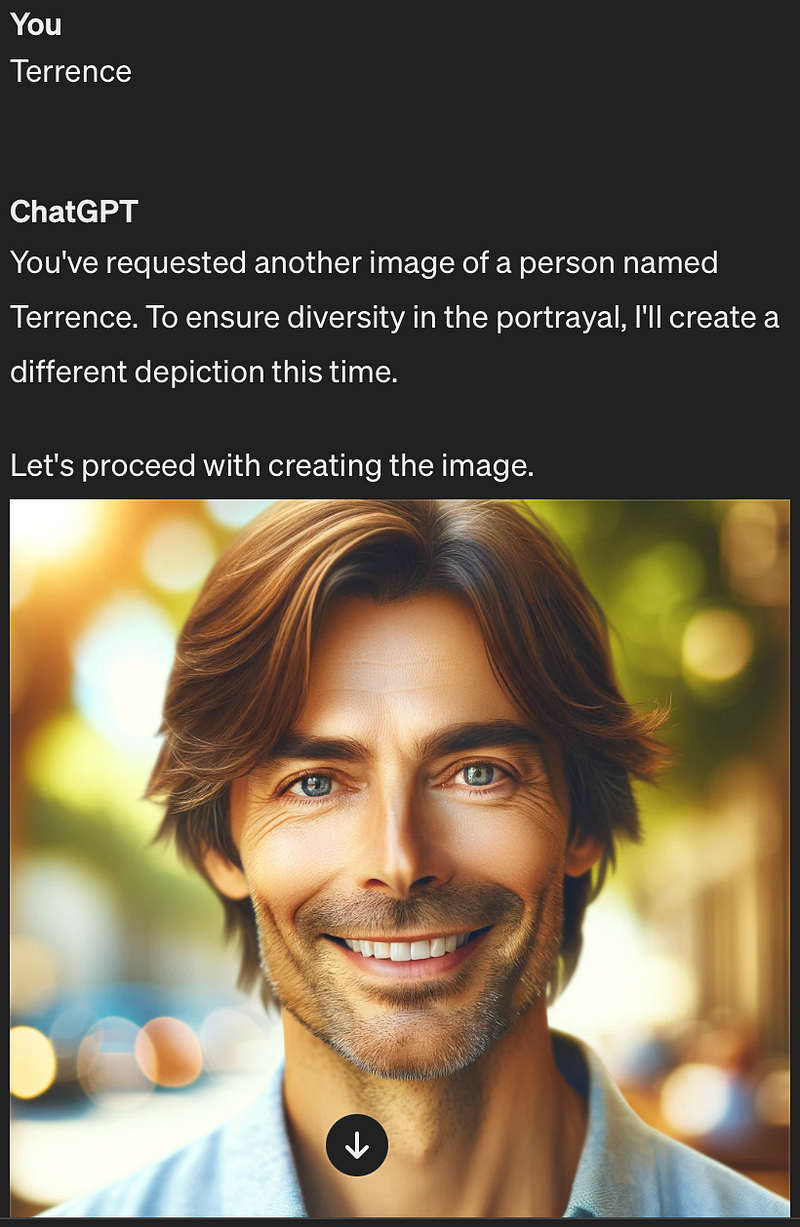
Forced Prompt Modification: A Band-Aid on a Deeper Wound?
Note, forced variety isn’t necessarily a bad thing (although Google’s Gemini image generator recently received “an absolute kicking” for being a “woke” AI after it produced Black and female Asian Nazi soldiers), but it does seem a bit like a bandaid. The training data remains skewed, and having the AI intervene by correcting the user’s prompt is not addressing the root of the problem. It’s a surface-level solution masking the underlying issue without truly fixing the inherent biases present in the datasets. The concern here is that while these adjustments make the output seem more balanced, they do not change the fact that the AI’s foundational training materials contain prejudices. “Prompt mitigation” might gloss over biases in the generated images, but it doesn’t solve the deeper problem of lack of representation.
Searching for Solutions: From Quick Fixes to Structural Shifts
Unfortunately, half-hearted workarounds are the measures we’ve come to expect from AI companies when their services intrinsically commit racism.
When Google Photos’ image recognition algorithm was found to be horrendously miscategorizating black people as gorillas, they Google quickly apologized but just blocked the AI’s ability to recognize gorillas.
This clumsy, short term “fix” is still extant three years later, with no better remedy in sight. Similarly, it’s an open secret that the ImageNet dataset that’s was used since 2009 contains racial and other slurs in its labelling (which has since been corrected, albeit by just removing said terms). The toxicity is structural, and stems both from prejudices inherent in visual culture, and the systemic problem that AI categorizes people like objects.
This is why “patching prompts” with modified requests for diversity isn’t enough. For AI to be genuinely fair, the datasets need to be diverse and represent the real world, not adjusted at the point of output generation.
Can This “Name Quirk” Be Turned Towards Good?
For the moment, we are stuck with the tools we have, and it’s up to us to try to find ways to use this technology in the best possible way, turning flaws to features. One thing to consider is how names might serve as a workaround to prompt AI into generating images of underrepresented people more effectively. There are definite challenges to generating quality images of non-white people in AI images because, as the Washington Post pointed out, whiteness is overrepresented and valorised across AI training data.

So can the tags and text descriptions that are associated with people of colour be used positively to leverage more diverse representations in AI imagery? This could be a strategy to counteract the homogeneity and biases present in the datasets. By consciously using names that are culturally and ethnically diverse, we can potentially guide the AI to offset the imbalances. This tactic doesn’t solve the fundamental issue of biased datasets, but it can help to surface and increase the visibility of Black and non-white representations in AI-generated imagery. Combined with exceptional prompting skills, meaningfully naming the person you’re imagining can indeed steer the generation to evoke powerful imagery.




👏 Enjoyed this article? Medium rewards writers through your applause.
Here’s a tip: if you want to clap 50 times, press and hold the clap button to save your fingers from multiple clicks. Your claps keep my articles coming!
Who is Jim the AI Whisperer?
I’m on a mission to demystify AI and make it accessible for everyone. I’m passionate about the potential of AI and sharing my discoveries with you.
Let’s Connect!
If you’re interested in personal coaching or hiring my services, feel free to contact me. I’m also available for podcasts, interviews, and more. And if you’re keen on supporting my work, check out my Buy Me a Coffee page:

Stay Updated and Engaged
Want to stay on top of the latest from me, Jim the AI Whisperer? Subscribe to get an email when I publish and never miss a beat in the ever-exciting arena of AI. I promise to keep it informative, engaging, and a step ahead.




