
Video-to-3D Avatar. Dynamic Human Reconstruction
How Machines Decode Cinematic Stories

Bridging Video and 3D Avatars
Once upon a time, in the bustling world of technology and innovation, a team of researchers from ETH Zurich embarked on a fascinating journey. Their mission was to bridge the gap between the realms of video and 3D avatars, a task that had challenged many before them.
AI and Cinema
From Simple Videos to Dynamic 3D Avatars: A Technological Leap
Their journey began with a simple video, a mere collection of two-dimensional images. The video, however, held a world of potential. It was a window into a three-dimensional reality, a reality that the researchers aimed to capture and translate into the digital world.
The team, armed with their knowledge and expertise, developed a novel approach. They created a system that could take a single video as input and generate a 3D avatar as output. This was no ordinary avatar, though. It was a dynamic, animated representation that could mimic the movements and expressions of the person in the video with remarkable accuracy.
Deep Learning: The Key to Capturing Human Movement in 3D
The researchers’ system was a marvel of modern technology. It utilized deep learning techniques to understand and replicate the intricate details of human movement. It could capture the subtleties of facial expressions, the fluidity of body movements, and even the complex dynamics of clothing.
3D Avatar Method
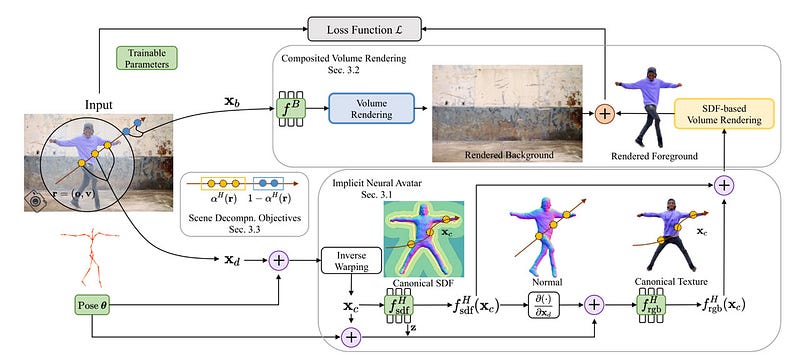
Their journey was not without challenges. The system had to overcome numerous obstacles, such as variations in lighting, different camera angles, and changes in the person’s appearance. But the researchers were undeterred. They refined their algorithms, improved their models, and gradually, their system became more robust and versatile.
A Breakthrough in Computer Vision: The Power of Video-to-3D Avatar Transformation
The culmination of their journey was a breakthrough in the field of computer vision and graphics. They had successfully transformed a simple video into a lifelike 3D avatar. But more than that, they had opened up a world of possibilities. Their system could be used in virtual reality, gaming, film production, and many other applications.
The Beginning of a New Era: Lifelike 3D Avatars and the Endless Possibilities of Technology
In the end, the researchers from ETH Zurich had not just created a system. They had told a story, a story of innovation, perseverance, and the endless possibilities of technology. And as they looked at the 3D avatar, a digital reflection of the real world, they knew that their journey was just the beginning.
In short, their contributions are:
- a method to reconstruct detailed 3D avatars from in-the-wild monocular videos using self-supervised scene decomposition;
- a way to get robust and detailed 3D reconstructions of the human even in difficult poses and environments without using external segmentation methods; and
- a new semi-synthetic testing dataset that allows for the first time to compare monocular human reconstruction methods on realistic scenes. The file has a lot of notes about the 3D surface.
Researchers will be able to use the code and data for their work.
Over the course of the previous year, we have made significant progress in transitioning from 2D to 3D; this fresh method is the next step, and there is still more to come.
AI is everywhere, But the question is, how much do you love it?
I invite you to explore the concept of Machine Learning Art by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, wombo dream, digital art, Dalle 2, Imagen, wombo ai, Parti, 3D point cloud, diffusion models, generative art, wombo art, photographic quality, img by AI system, AI art generator, text to art generator, 3D, midjourney, dalle2, stablediffusion, Dalle 3, Vid2Avatar

Project Page:
https://files.ait.ethz.ch/projects/vid2avatar/main.pdf
3D Avatar Reconstruction from Videos in the Wild
CODE:
https://github.com/MoyGcc/vid2avatar
@inproceedings{guo2023vid2avatar,
title={Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition},
author={Guo, Chen and Jiang, Tianjian and Chen, Xu and Song, Jie and Hilliges, Otmar},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}




