
Using Google BigQuery as a Data Mesh
A Guide to efficient Data Management

While the Data Lakehouse is the technical approach to a modern data platform, the Data Mesh is the social and organizational component to enable a data-driven culture as a company[1][2].
The Data Mesh is a modern architectural approach that aims to decentralize data ownership and improve data accessibility within an organization. It promotes the idea of treating data as a product and allowing domain teams to have self-service data access. BigQuery, Google Cloud’s fully managed Data Warehouse, provides powerful capabilities for implementing a data mesh framework. In this article, I would like to examine how you can use BigQuery as a data mesh and discuss best practices for efficient data management[2].
Define Data Domains
The first step in implementing a Data Mesh with BigQuery is actually non- technical. Here, you have to identify and define data domains. Data domains represent specific areas of data ownership within your organization, often aligned with different business functions or teams. Each data domain is responsible for managing and maintaining its own data products. Start working with domain teams to understand their data needs and define the boundaries of each domain.
Design stable Data Pipelines
To enable self service data access, it is important to design scalable and reliable data pipelines. BigQuery offers several options for ingesting and transforming data. Use tools like Cloud Dataflow, Apache Beam or BigQuery’s Data Transfer Service to automate data ingestion from various sources. With Google BigLake, you now also have the opportunity to integrate or directly query data sources via a Zero-ETL approach and be also cloud independent[4].
Establish a Data Governance
Data Governance plays a critical role in ensuring data quality, security, and compliance across the enterprise[3]. With BigQuery, you can implement robust data governance practices easily by defining data access controls using BigQuery’s Identity and Access Management (IAM) to grant appropriate permissions to domain teams. Set standards for data cataloging using tools like Data Catalog to maintain a centralized repository of data assets, including metadata and data lineage. Another quite interesting new feature was also added with Data Clean Rooms.
Implement Data Mesh Principles
Adopting Data Mesh principles with BigQuery requires breaking monolithic data architectures into smaller, decentralized components. Encourage domain teams to take ownership of their data products and manage them independently. Each team can create their own BigQuery datasets to store and process their domain-specific data. You can define schemas, manage access controls, and implement rules and data transformations by using SQL or tools like the BigQuery Analytics Hub[5].
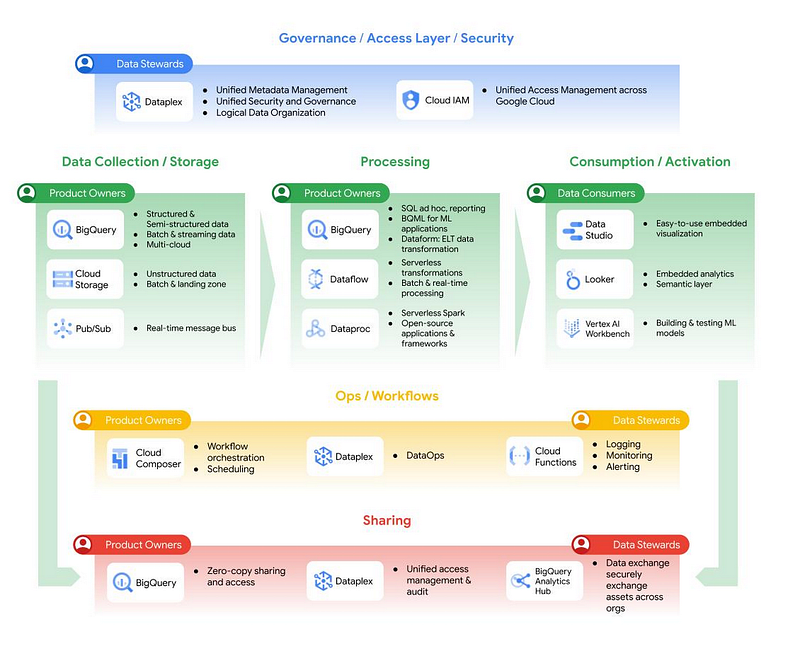
Enable Data Discovery and Collaboration
To encourage data discovery and collaboration, leverage the capabilities of BigQuery. Implement a robust data catalog using tools like Data Catalog or BigQuery’s metadata capabilities. Make sure data domains document and annotate their datasets and provide clear descriptions and usage policies. Encourage domain teams to share their data products across the organization and make them visible to other teams via the data catalog.
Monitor and optimize Performance
In order for the CIO and CDO to not have a heart attack when they get the bill from Google, it requires efficient data management by monitoring and optimizing performance. BigQuery provides tools like BigQuery Monitoring and BigQuery Reservations to track query performance, manage resources, and optimize costs[6]. Encourage domain teams to monitor their query patterns, identify long-running or inefficient queries, and tune them for better performance.
Summary
By implementing a Data Mesh architecture withing the Google Cloud and BigQuery as the main tool, organizations can distribute data ownership, improve data accessibility, and foster a data-driven culture. I hope the article gave you an idea of how to build such an architecture and which technical and organizational components are important here. Leveraging BigQuery’s powerful data storage, processing, and management capabilities, domain teams can take ownership of their data products and enable self-service data access.
Sources and Further Readings
[1] Stefan Koch, Können Lakehouses einen Paradigmenwechsel anstossen? (2021)
[2] Michael Armbrust, Ali Ghodsi, Bharath Gowda, Arsalan Tavakoli-Shiraji, Reynold Xin and Matei Zaharia, Frequently Asked Questions About the Data Lakehouse (2021)
[3] talend, What is Data Governance and Why Do You Need It? (2023)
[4] Google, BigLake (2022)
[5] Google, Build a modern, distributed Data Mesh with Google Cloud (2023)
[6] Google, Statistiken zur Abfrageleistung abrufen (2023)